边策 十三 发自 凹非寺
量子位 报道 | 公众号 QbitAI
你在看电影,墙上的影子也在动。如果只让你看到这样一段视频,你能猜出来屏幕上播放的是什么吗?

最近MIT人工智能实验室(CSAIL)开发出的算法可以做到:

而真实的视频是这样的:

算法还原的结果只是模糊了些,但已经能猜出视频的大致内容了。
有了这套算法,就可以通过观察视频中阴影和几何图形之间的相互作用,预测出光在场景中的传播方式,然后从观察到的阴影中估计隐藏的视频,甚至看出人的轮廓。
这种图像重建算法会有许多用途:自动驾驶汽车可以了解拐角处正在发生的事情,监控摄像头也可以发现在视线外的人。该论文已经被最近召开的NeurIPS 2019大会所收录。
根据影子,还原看不见的死角
在下面这个场景中,人摆弄玩具的镜头被隐藏,在人们正常视野范围内是无法看见的。

我们唯一能够捕捉到的就是打在墙上的影子。
MIT的这项研究就是仅仅利用这些影子,重新还原隐藏视频的原貌。

算法对场景中的光线传输做了预测。
下图左侧是通过算法估计出来的阴影,而右侧则是实际场景中的阴影。

根据光线传输的预测和估计,就可以重建隐藏物体的运动情况。
例如在下图中,隐藏在摄像头视野之外的人,双手不停的在做着运动。
而我们能够观察到的只是图中左侧单个物体中光影的变化。
就是利用这样简单的光影变化,便可以重构出如图中右侧的视频。
与隐藏视频相比,重构的视频已经可以大致再现双手运动的轮廓。

根据房间杂物乱七八糟的影子,同样也可以还原下图隐藏视频中人物走动的大致轮廓。

当然还有这样的。

以及这样的。

总体来说,MIT的这次研究,能够根据隐藏视频中的内容将光线传输分离出来,从而对它做一个大致的估计。
原理
图像的影子具有线性叠加的特性。如果依次点亮隐藏的屏幕上的两个像素,并墙上的影子图像求和,结果应该和一次同时点亮两个像素时得到的图像相同。
从数学上来看,无论是墙上的影子,还是屏幕上的画面,都是矩阵。而符合线性叠加的特性,等于是在这两个矩阵之间做线性变换。
我们不妨把这二者别看做两个矩阵Z和L,经过空间传输,画面L变成了影子Z,这就相当于做了一次矩阵乘法,T是空间传输矩阵。
Z=TL
问题是我们只看到了影子Z,对于T和L,我们一无所知。
这篇论文的第一作者Miika Aittala说:“这就像是我告诉你,我正在考虑两个秘密数字,它们的乘积为80。你能猜出它们是什么吗?也许是40和2,或是371.8和0.2152。”
对于这个问题也是类似,而且我们在每个像素上都会有一样的困扰。如何求出传输矩阵T成了问题的关键。
如果我们知道了光传输矩阵,那么求原图像L的操作就变成了最小化||Z-TL||2的最小二乘法问题。
作者通过DCT和PCA方法测量了T,然后通过求逆的方法恢复了原始图像。

因此知道了T,接下来恢复图像就好办了。
但是这篇文章要挑战更高的难度:如何在不知道T的情况下恢复图像。他们使用了去年一篇Deep Image Prior论文中的新的矩阵分解方法。
这篇文章曾经被CVPR 2018收录,在inpainting问题上收到了不错的效果。
过去也有一些矩阵分解方法,但是分解得到的矩阵一般都是低秩的,与图像差别很大,而且对初始值和优化的动力学都高度敏感,只能针对特定问题量身定制。
而作者使用的矩阵分解方法里,CNN随机初始化并“过拟合”,将两个噪声矢量映射到两个矩阵T和L,使它们的乘积与输入矩阵Z匹配。此过程将因式分解正则化为更接近于图像的结构。
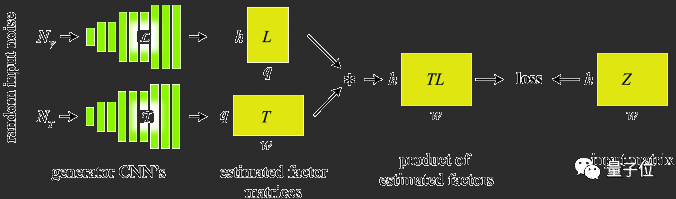
结合上面的思想
Deep Image Prior
作者首先描述了一种基线方法,在知道Z和L的情况下求T,其实就是求||Z-TL||2最小值的最小二乘法问题。
使用了Deep Image Prior的方法,作者提出了一种在无法测得的光传输矩阵时,逆向求原图像的方法。逆向光传输矩阵的体系架构和数据流动如下图所示:
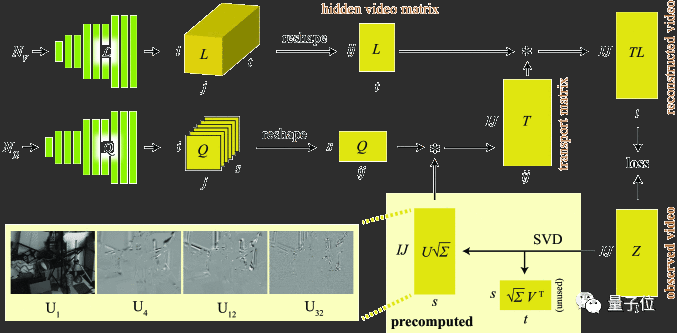
其中左下角是存储在U中的左奇异矢量的一个样本。L和Q是两个卷积神经网络,其余块是多维张量或矩阵,其尺寸显示在边缘。
L和Q生成各自矩阵的卷积神经网络中张量,然后在随后的网络操作中将结果重整为堆叠的矩阵表示形式,以便评估矩阵乘积。
传输矩阵T的分量可以表示为从输入视频的奇异值分解(SVD)获得的基本图像的线性组合。这样做计算效率高,又通过限制迭代和位于有效分解子空间中的解来指导优化。
通过输入Z预先计算的截断奇异值分解UΣVT带入到上面的网络中,计算出T,再将计算的TL与Z对比求得损失。
因此问题的核心就变成了用CNN得出Q,使得(UQ)L≈Z。
代码已开源
这么好玩的技术,代码当然开源啦~
GitHub链接如下:
https://github.com/prafull7/compmirrors
这份文档中列出了“矩阵分解”和“光线传输分解”的实现方法。
安装
git clone https://github.com/prafull7/compmirrors
cd compmirrors
配置要求:Python 3.7,以及还需要torch=1.0.1.post2、matplotlib、scipy、visdom等包。
矩阵分解
这步的实现代码在factorization_1d.py文件。可用如下代码运行:
python factorization_1d.py -T ./data/inputs_1d/lightfield.png -L ./data/inputs_1d/tracks_bg.png -o ./outdir_1d
光线传输分解
一次性训练实现代码在factorization_light_transport.py文件。可用如下代码运行:
export FACTORIZE_DATA_DIR=/path/to/where/data/folders/
export FACTORIZE_OUT_DIR=/path/to/output/directory
python factorization_light_transport.py -d ./data/light_transport/ -f FOLDER_NAME -ds DATASET_NAME -s SEQUENCE_NAME -dev DEVICE_NUMBER
依旧是“鸡生蛋,还是蛋生鸡”问题
虽然这项技术能够重建被隐藏的内容,但是用户还是需要提前知道被隐藏的东西是存在的。
用数学的角度来打个比方。
A和B相乘得80,让你来猜A和B分别是哪两个数字。
可能是40和2,也可能是371.8和0.2152。
在重建工作中,每个像素都会遇到这样的问题——有多种选择。
要让计算机来做选择,那它就会做最简单的事情,得到的结果就是随机的图像。
因此需要规定的算法来做训练。
在此之前,量子位也曾报道过,通过墙壁漫反射的光影,来重建原始画面。
墙上的漫反射如下图所示:

算法还原的图像则是:

这个图像还原实验是,在房间中间随手放置了一个不明位置的遮挡物体,可以是一块不发光的板子,也可以是随手拽过来的一把椅子,阻挡一部分光线到达墙壁。
而这次是完全根据墙上的影子来做图像还原工作。
通过影子的变化可以大致了解房间里隐蔽区域发生了哪些运动。
研究人员同时也对接下来的工作做了展望:
未来,希望能够提高系统的总体分辨率,并最终在不受控制的环境中测试该技术。
传送门
博客:
https://news.mit.edu/2019/using-computers-view-unseen-computational-mirrors-mit-csail-1206
论文:
https://arxiv.org/pdf/1912.02314.pdf
代码:
https://github.com/prafull7/compmirrors
数据:
http://compmirrors.csail.mit.edu/data/dots-sequence.tar
— 完 —
大咖齐聚!量子位MEET大会精彩回放
量子位 MEET 2020 智能未来大会精彩回放来袭!李开复、倪光南、景鲲、周伯文、吴明辉、曹旭东、叶杰平、唐文斌、王砚峰、黄刚、马原等AI大咖与你一起读懂人工智能。扫码观看回放吧~ ~

跟大咖交流 | 进入AI社群


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !











 京公网安备 11010802041100号
京公网安备 11010802041100号