作者:零食专卖店 | 来源:互联网 | 2023-09-09 12:17
1.前言
最近在做的项目中,一直用到了GBDT+LR算法模型来做二分类,好好梳理了下。下面介绍下这个算法。先来解答下面三个问题。
GBDT+LR模型是什么:是一种具有stacking思想的二分类器模型,所以可以用来解决二分类问题。这个方法出自于Facebook 2014年的论文 Practical Lessons from Predicting Clicks on Ads at Facebook 。
GBDT+LR模型常用在哪:GBDT+LR 使用最广泛的场景是CTR广告点击率预估,即预测当给用户推送的广告会不会被用户点击(也是个二分类问题),同时类似的二分类问题也很适合使用,我做的项目就是判断是否有某种风险分类,然后用于业务的电商风控内容。
为什么要GBDT+LR模型:点击率预估模型涉及的训练样本一般是上亿级别,样本量大,模型常采用速度较快的LR。但LR是线性模型,学习能力有限,此时特征工程尤其重要。现有的特征工程实验,主要集中在寻找到有区分度的特征、特征组合,折腾一圈未必会带来效果提升。GBDT算法的特点正好可以用来发掘有区分度的特征、特征组合,减少特征工程中人力成本。
2.原理
GBDT+LR 模型是一种stacking思想,而stacking又是一种典型的集成学习方法,“先从初始数据集训练出初级学习器,然后生成一个新数据集用于训练次级学习器”【1】(学习器也有叫分类器,后面叫分类器)。其中GBDT用来对训练集提取特征作为新的训练输入数据,LR作为新训练输入数据的分类器。如下图1 GBDT+LR模型结构图所示,具体来讲,有以下几个步骤:
2.1 GBDT首先对原始训练数据做训练,得到一个二分类器,当然这里也需要利用网格搜索寻找最佳参数组合。
2.2 与通常做法不同的是,当GBDT训练好做预测的时候,输出的并不是最终的二分类概率值,而是要把模型中的每棵树计算得到的预测概率值所属的叶子结点位置记为1,这样,就构造出了新的训练数据。
举个例子,下图是一个GBDT+LR 模型结构,设GBDT有两个弱分类器,分别以蓝色和红色部分表示,其中蓝色弱分类器的叶子结点个数为3,红色弱分类器的叶子结点个数为2,并且蓝色弱分类器中对0-1 的预测结果落到了第二个叶子结点上,红色弱分类器中对0-1 的预测结果也落到了第二个叶子结点上。那么我们就记蓝色弱分类器的预测结果为[0 1 0],红色弱分类器的预测结果为[0 1],综合起来看,GBDT的输出为这些弱分类器的组合[0 1 0 0 1] ,或者一个稀疏向量(数组)。
这里的思想与One-hot独热编码类似,事实上,在用GBDT构造新的训练数据时,采用的也正是One-hot方法。并且由于每一弱分类器有且只有一个叶子节点输出预测结果,所以在一个具有n个弱分类器、共计m个叶子结点的GBDT中,每一条训练数据都会被转换为1*m维稀疏向量,且有n个元素为1,其余m-n 个元素全为0。
2.3 新的训练数据构造完成后,下一步就要与原始的训练数据中的label(输出)数据一并输入到Logistic Regression分类器中进行最终分类器的训练。思考一下,在对原始数据进行GBDT提取为新的数据这一操作之后,数据不仅变得稀疏,而且由于弱分类器个数,叶子结点个数的影响,可能会导致新的训练数据特征维度过大的问题,因此,在Logistic Regression这一层中,可使用正则化来减少过拟合的风险,在Facebook的论文中采用的是L1正则化。
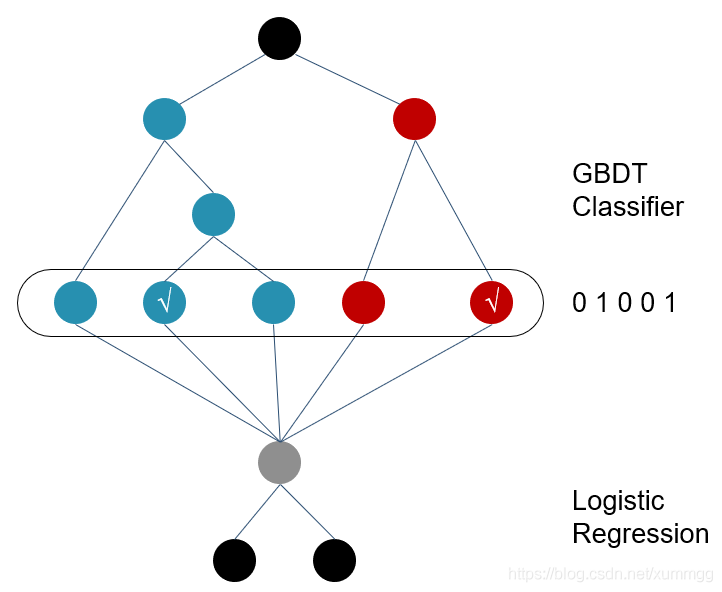
图1 GBDT+LR模型结构图
3 常见问题
3.1 GBDT+LR的输入特征是否要归一化?
GBDT+LR的输入特征不需要归一化。
归一化和标准化主要是为了使计算更方便,提升模型的收敛速度和提高精度。在实际应用中,通过梯度下降法求解的模型一般都是需要归一化的,比如线性回归、logistic回归、KNN、SVM、神经网络等模型。但树形模型不需要归一化,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率,如决策树、随机森林(Random Forest)。
3.2 为什么GBDT+LR优于GBDT?
第一:gbdt+lr类似于做了一个stacking。gbdt+lr模型中,把gbdt的叶子节点作为lr的输入,而gbdt的叶子节点相当于它的输出y’,用这个y’作为lr的x,和stacking是类似的。
第二:gbdt的每棵树其实是拟合上一颗树的残差上求得的局部最优解,把所有局部最优解的输出通过lr训练得到一个全局最优解。所以优于单独使用gbdt
3.3 为什么GBDT+LR优于LR?
第一:lr算法简单,能够处理超高纬度稀疏问题。但是lr需要人工进行特征组合。gbdt+lr相当于对原始特征通过gbdt进行了特征组合
第二:gbdt对连续特征划分能力强,可以帮助lr处理连续特征,避免了人工对连续特征分箱操作。
3.4 GBDT+LR的为什么适合输入连续特征?(为什么GBDT适用于连续型特征)
GBDT不能用离散特征不是因为它处理不了离散特征,而是因为离散化特征后会产生特别多的特征,决策树的叶子节点过多,遍历的时候太慢了。 所以海量离散特征+LR是业内常见的一个做法。而少量连续特征+复杂模型是另外一种做法,例如GBDT。
模型是使用离散特征还是连续特征,其实是一个“海量离散特征+简单模型” 同 “少量连续特征+复杂模型”的权衡。既可以离散化用线性模型,也可以用连续特征加深度学习。
3.5 为什么lr不能处理连续特征(为什么LR适用于离散型特征)
因为这样可以增加lr的鲁棒性,比如如果把年龄送进lr,那么23和24岁本来相差不大,但是却变成了完全不同的变量,也就是所23岁和24岁的区别程度和23岁和50岁的区别程度是一样的,显然不符合。或者加入一个300岁的偏差特征也可能会影响模型,但对年龄分箱之后就可以避免上述问题,增加模型鲁棒性。
3.2.6 可以GBDT+LR,那XGBOOST+LR,FR+LR等也可以吗?
既然GBDT可以做新训练样本的构造,那么其它基于树的模型,例如Random Forest以及Xgboost等也可以按类似的方式来构造新的训练样本。所有这些基于树的模型都可以和Logistic Regression分类器组合。至于效果孰优孰劣,总体效果都还可以,但是之间没有可比性,因为超参数的不同会对模型评估产生较大的影响。下图是RF+LR、GBT+LR、Xgb、LR、Xgb+LR 模型效果对比图2,然而这只能做个参考,因为模型超参数的值的选择这一前提条件都各不相同。
另外,RF也是多棵树,但从效果上有实践证明不如GBDT。且GBDT前面的树,特征分裂主要体现对多数样本有区分度的特征;后面的树,主要体现的是经过前N颗树,残差仍然较大的少数样本。优先选用在整体上有区分度的特征,再选用针对少数样本有区分度的特征,思路更加合理,这应该也是用GBDT的原因。
图2 各模型ROC图
4.参考资料
【1】《机器学习》-周志华,清华大学出版社 ,第8.4.3节“学习法”
【2】https://blog.csdn.net/zzy1448331580/article/details/106782677
【3】https://blog.csdn.net/Beyond_2016/article/details/80030427?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control&dist_request_id=1330144.10424.16180666440009909&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control
【4】https://blog.csdn.net/weixin_34019144/article/details/93064641
【5】https://www.jianshu.com/p/964130615414
【6】https://www.cnblogs.com/wkang/p/9657032.html







 京公网安备 11010802041100号
京公网安备 11010802041100号