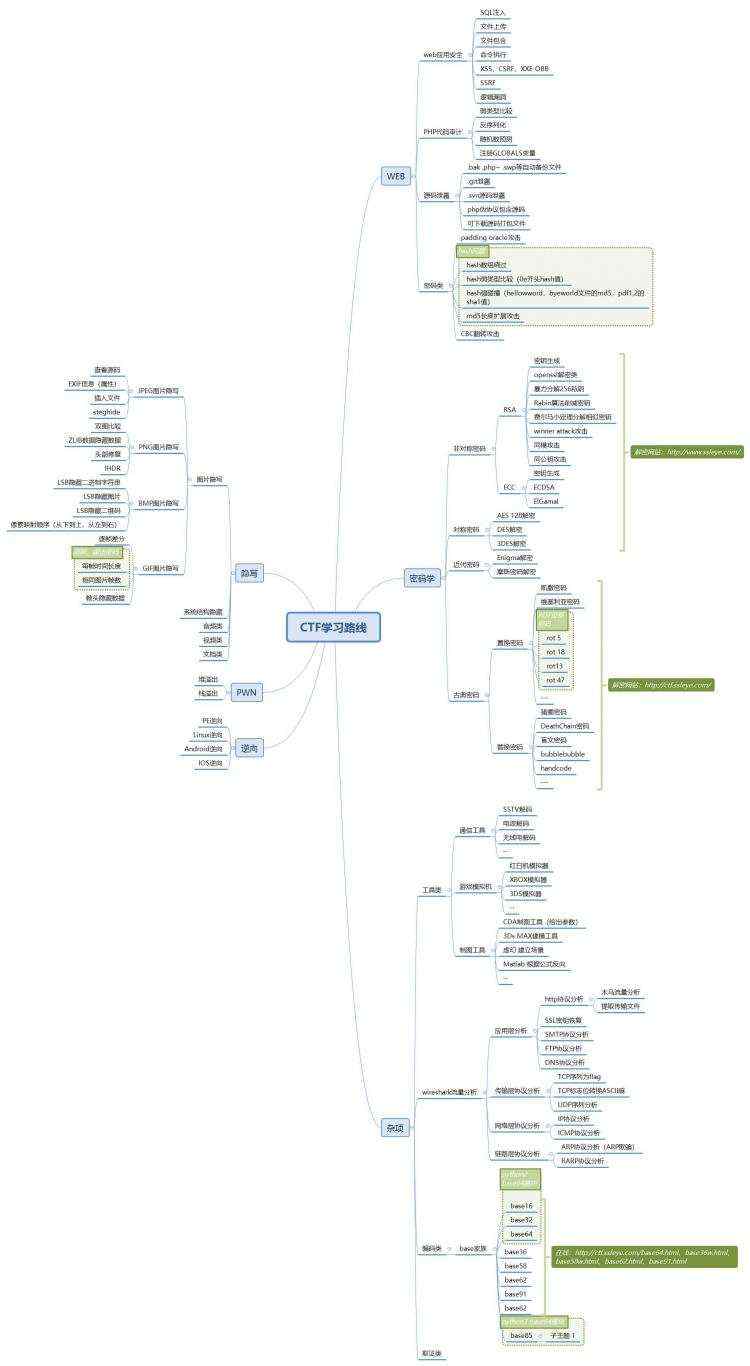
K近邻算法是一种懒惰算法,即没有对数据集进行训练的过程,其模型的三个要素:距离度量、k值的选择和分类决策规则决定。
K近邻的思想很简单,即在一个数据集上,给定一个新样本,找到与新样本距离最近的k个实例,在这些实例中属于多数的类即为这个新样本的类。
李航老师《统计学习方法》中,定义的K近邻算法如下:
算法虽然简单,但在其中也要解决一些问题滴。比如,距离度量该怎么选择、k值该怎么选择、分类决策规定该怎么选择。
对于距离度量,一般使用欧式距离,也可以使用其它距离的度量方式,常见的距离度量如下:
K值的选择是一个玄学问题,取小点,太草率;取多点,比如取到数据集的个数,又没什么意义。
因此,k值的选择很大程度上根据经验来选取。当然可以加些科学的手段,比如用交叉验证法、贝叶斯法等方法来确定k的取值。
分类决策规则是指在选取k个最近邻的样本时,我们该怎么判断这个新样本的类别呢?这里,我给出两个思路,欢迎大家留言补充。
1. 多数表决规则
即少数服从多数,这k个样本中,谁的类别最多,听谁的。所以,多说一句,在二分类问题中,k的取值建议为奇数,这样不会造成票数持平的状态。
多数表决法等价于经验风险最小化,推导如下:
2. 加权法
加权法是我的一些思考..算是多数表决法的扩展,主要思想是为每个样本赋予权值,加权最大的类即为推荐的类。在多数表决法中,默认为每个样本的权值相等。
knn算法思想成熟,可用于分类也可用于回归,其优势在于:
1.对数据没有假设,准确度高,对outlier不敏感;
2.KNN算法是懒惰学习方法,不需要训练,可以进行增量学习
缺点在于:
1.当样本不均衡时,选取的临近K个样本很可能造成取样不均,造成预测不精准
2.在数据量较大的情况,knn算法效率不高。kd树可以在一定程度上解决这个问题。
3.需要大量的内存








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有