public class TestDemo {
public static void main(String[] args) {
Person p1 = new Person("阿伦");
Person p2 = new Person("阿伦");
System.out.println(p1.equals(p2));
}
static class Person {
public Person(String name) {
this.name = name;
}
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return Objects.equals(name, person.name);
}
}
}
上方代码运行结束后,可以看到输出的结果为true。

可以看到,因为重写了equals方法后,只要类型相同,name相同,就认定两个对象是同一个,而不是默认用内存地址去比对是不是同一个,
在我们的业务代码中一般会需要这么用,例如一个人名字相等,就是同一个人,正常来说,我们重写了equals判断是相等的不就已经够用了吗,为什么还要重写hashCode呢, 下面我们再看一个例子。
根据开篇中的代码,我们不重写hashCode,下面来做一个需求,过滤重复的人,例如两个名叫阿伦的人, 但是我们只保存一个,
那这时候咱们用HashMap来做,因为HashMap的key是唯一的,去重的,我们重写了Person的equals方法,只要名字是相等的,就是同一个对象,那HashMap应该会识别出来并去重吧?我们看下结果:
public static void main(String[] args) {
Person p1 = new Person("阿伦");
Person p2 = new Person("阿伦");
Map map = new HashMap<>();
map.put(p1, p1.getName());
map.put(p2, p2.getName());
System.out.println("map长度:" + map.size());
map.forEach((key, value) -> {
System.out.println(key.getName());
});
}

是不是很神奇,竟然没有去重,两个都保存到了HashMap中,并没有达到我们想要的效果,这是为什么?
首先HashMap的内部存值是一个数组,但是HashMap的查找速度非常快,基本是O(1),
这是因为它借助了Hash算法,HashMap对key进行hash后,得出一个整数值, 这个整数值就是存放到最终的存储数组中的下标, 当然这块后续还有一系列的处理, 可以查阅相关资料做深入的了解, 这里只做简单的描述,
我们接着上面的问题看,因为我们没有重写hashCode方法,虽然equals以两个对象的name值是否相同做对比,但是HashMap存值的时候,是通过hashCode进行计算,算出一个值存到相应的数组下标下去的呀?
所以我们上面代码中的p1和p2两个值返回的hashCode值是不同的,所以计算出来的下标也不同,导致他们被HashMap存到不同的数组下标下面去了~ 这就是为什么没有去重成功的原因,
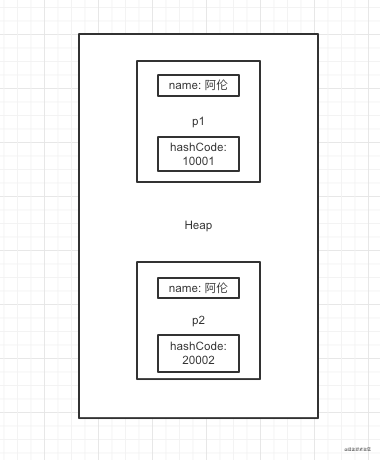
看上图, 两个对象在堆地址中, 名字是一样的,hashCode不同,如果是通过名字做比对,做hash,那么就是相等的,但是HashMap用的是hashCode,所以,我们需要重写hashCode方法,根据自身业务保证,相同含义在业务层面属于一个对象的hashCode也要保持一致。
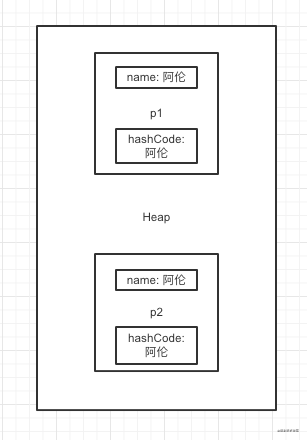
看下图,我们可以将hashCode的计算方式改成用name来计算:
public class TestDemo {
public static void main(String[] args) {
Person p1 = new Person("阿伦");
Person p2 = new Person("阿伦");
System.out.println(p1.hashCode());
System.out.println(p2.hashCode());
Map map = new HashMap<>();
map.put(p1, p1.getName());
map.put(p2, p2.getName());
map.get(p1);
System.out.println("map长度:" + map.size());
map.forEach((key, value) -> {
System.out.println(key.getName());
});
}
static class Person {
public Person(String name) {
this.name = name;
}
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name);
}
}
}

可以看到,当我们重写了hashCode让对象的名字作为计算的值,用来产生最终的hash值,这样HashMap就可以帮我们把两个对象,路由到一个下标下面了,再通过equals比对,确定两个是同一个对象,从而达到去重的效果。
根据业务状况重写equals后,一定要将hashCode用一定相同的规则做hash,防止在一些需要用到对象hashCode的地方造成误会,引发问题,
同时这里再说一点,hashCode也会发生冲突和重复喔~ 也许他们并不是一个对象,但是hashCode是相同的,这时HashMap是怎么处理的呢?
这里简单说一下,是用链表,当两个对象hashCode冲突时,会将这两个对象放在同一个下标下的链表中都保存着,获取的时候通过hashCode路由到相应的地点,然后循环这个列表通过equals方法做对比,返回最终的正确值。
重写equals和hashCode的原则:
1.自反性:x.equals(x) == true,自己和自己比较相等
2.对称性:x.equals(y) == y.equals(x),两个对象调用equals的的结果应该一样
3.传递性:如果x.equals(y) == true y.equals(z) == true 则 x.equals(z) == true,x和y相等,y和z相等,则x和z相等
4.一致性 : 如果x对象和y对象有成员变量num1和num2,其中重写的equals方法只有num1参加了运算,则修改num2不影响x.equals(y)的值
到此这篇关于浅谈java中为什么重写equals后需要重写hashCode的文章就介绍到这了,更多相关Java重写equals内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!





 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 