XSS 攻击指的是跨站脚本攻击,是一种代码注入攻击。攻击者通过在网站注入恶意脚本,使之在用户的浏览器上运行,从而盗取用户的信息如 COOKIE 等。
XSS 的本质是因为网站没有对恶意代码进行过滤,与正常的代码混合在一起了,浏览器没有办法分辨哪些脚本是可信的,从而导致了恶意代码的执行。
攻击者可以通过这种攻击方式可以进行以下操作:
XSS 可以分为存储型、反射型和 DOM 型:
1)存储型 XSS 的攻击步骤:
这种攻击常⻅于带有⽤户保存数据的⽹站功能,如论坛发帖、商品评论、⽤户私信等。
2)反射型 XSS 的攻击步骤:
反射型 XSS 跟存储型 XSS 的区别是:存储型 XSS 的恶意代码存在数据库⾥,反射型 XSS 的恶意代码存在 URL ⾥。
反射型 XSS 漏洞常⻅于通过 URL 传递参数的功能,如⽹站搜索、跳转等。 由于需要⽤户主动打开恶意的 URL 才能⽣效,攻击者往往会结合多种⼿段诱导⽤户点击。
3)DOM 型 XSS 的攻击步骤:
DOM 型 XSS 跟前两种 XSS 的区别:DOM 型 XSS 攻击中,取出和执⾏恶意代码由浏览器端完成,属于前端Javascript ⾃身的安全漏洞,⽽其他两种 XSS 都属于服务端的安全漏洞。
Nginx 是一款轻量级的 Web 服务器,也可以用于反向代理、负载平衡和 HTTP 缓存等。Nginx 使用异步事件驱动的方法来处理请求,是一款面向性能设计的 HTTP 服务器。
传统的 Web 服务器如 Apache 是 process-based 模型的,而 Nginx 是基于event-driven模型的。正是这个主要的区别带给了 Nginx 在性能上的优势。
Nginx 架构的最顶层是一个 master process,这个 master process 用于产生其他的 worker process,这一点和Apache 非常像,但是 Nginx 的 worker process 可以同时处理大量的HTTP请求,而每个 Apache process 只能处理一个。
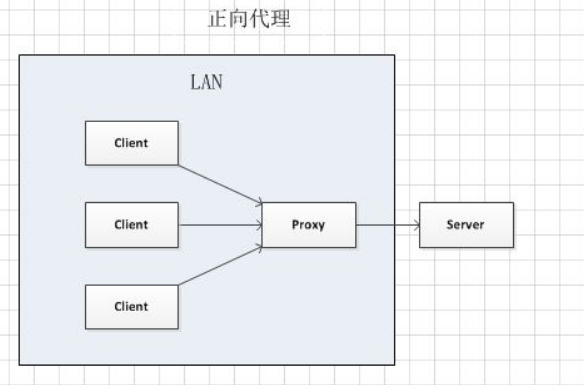
客户端想获得一个服务器的数据,但是因为种种原因无法直接获取。于是客户端设置了一个代理服务器,并且指定目标服务器,之后代理服务器向目标服务器转交请求并将获得的内容发送给客户端。这样本质上起到了对真实服务器隐藏真实客户端的目的。实现正向代理需要修改客户端,比如修改浏览器配置。
服务器为了能够将工作负载分不到多个服务器来提高网站性能 (负载均衡)等目的,当其受到请求后,会首先根据转发规则来确定请求应该被转发到哪个服务器上,然后将请求转发到对应的真实服务器上。这样本质上起到了对客户端隐藏真实服务器的作用。
一般使用反向代理后,需要通过修改 DNS 让域名解析到代理服务器 IP,这时浏览器无法察觉到真正服务器的存在,当然也就不需要修改配置了。
正向代理和反向代理的结构是一样的,都是 client-proxy-server 的结构,它们主要的区别就在于中间这个 proxy 是哪一方设置的。在正向代理中,proxy 是 client 设置的,用来隐藏 client;而在反向代理中,proxy 是 server 设置的,用来隐藏 server。
MDN中对documentFragment的解释:
DocumentFragment,文档片段接口,一个没有父对象的最小文档对象。它被作为一个轻量版的 Document使用,就像标准的document一样,存储由节点(nodes)组成的文档结构。与document相比,最大的区别是DocumentFragment不是真实 DOM 树的一部分,它的变化不会触发 DOM 树的重新渲染,且不会导致性能等问题。
当我们把一个 DocumentFragment 节点插入文档树时,插入的不是 DocumentFragment 自身,而是它的所有子孙节点。在频繁的DOM操作时,我们就可以将DOM元素插入DocumentFragment,之后一次性的将所有的子孙节点插入文档中。和直接操作DOM相比,将DocumentFragment 节点插入DOM树时,不会触发页面的重绘,这样就大大提高了页面的性能。
const promise = new Promise((resolve, reject) => {
console.log(1);
setTimeout(() => {
console.log("timerStart");
resolve("success");
console.log("timerEnd");
}, 0);
console.log(2);
});
promise.then((res) => {
console.log(res);
});
console.log(4);
输出结果如下:
1
2
4
timerStart
timerEnd
success
代码执行过程如下:
1;steTimeout,它是一个宏任务,放入宏任务队列;Promise的状态此时还是pending,所以promise.then先不执行;steTimeout;timerStart,然后遇到了resolve,将promise的状态改为resolved且保存结果并将之前的promise.then推入微任务队列,再执行timerEnd;promise.then,打印出resolve的结果。这两种方式都是提高网页性能的方式,两者主要区别是一个是提前加载,一个是迟缓甚至不加载。懒加载对服务器前端有一定的缓解压力作用,预加载则会增加服务器前端压力。
CSRF 攻击指的是跨站请求伪造攻击,攻击者诱导用户进入一个第三方网站,然后该网站向被攻击网站发送跨站请求。如果用户在被攻击网站中保存了登录状态,那么攻击者就可以利用这个登录状态,绕过后台的用户验证,冒充用户向服务器执行一些操作。
CSRF 攻击的本质是利用 COOKIE 会在同源请求中携带发送给服务器的特点,以此来实现用户的冒充。
常见的 CSRF 攻击有三种:
参考:前端进阶面试题详细解答
setTimeout(fn, 0)多久才执行,Event LoopsetTimeout 按照顺序放到队列里面,然后等待函数调用栈清空之后才开始执行,而这些操作进入队列的顺序,则由设定的延迟时间来决定
console.log(1);
setTimeout(() => {
console.log(2);
Promise.resolve().then(() => {
console.log(3)
});
});
new Promise((resolve, reject) => {
console.log(4)
resolve(5)
}).then((data) => {
console.log(data);
})
setTimeout(() => {
console.log(6);
})
console.log(7);
代码输出结果如下:
1
4
7
5
2
3
6
代码执行过程如下:
IndexedDB 具有以下特点:
Javascript 的加载、解析与执行会阻塞文档的解析,也就是说,在构建 DOM 时,HTML 解析器若遇到了 Javascript,那么它会暂停文档的解析,将控制权移交给 Javascript 引擎,等 Javascript 引擎运行完毕,浏览器再从中断的地方恢复继续解析文档。也就是说,如果想要首屏渲染的越快,就越不应该在首屏就加载 JS 文件,这也是都建议将 script 标签放在 body 标签底部的原因。当然在当下,并不是说 script 标签必须放在底部,因为你可以给 script 标签添加 defer 或者 async 属性。
var length = 10;
function fn() {
console.log(this.length);
}
var obj = {
length: 5,
method: function(fn) {
fn();
arguments[0]();
}
};
obj.method(fn, 1);
输出结果: 10 2
解析:
对于 Loader 来说,影响打包效率首当其冲必属 Babel 了。因为 Babel 会将代码转为字符串生成 AST,然后对 AST 继续进行转变最后再生成新的代码,项目越大,转换代码越多,效率就越低。当然了,这是可以优化的。
首先我们优化 Loader 的文件搜索范围
module.exports = {
module: {
rules: [
{
// js 文件才使用 babel
test: /\.js$/,
loader: 'babel-loader',
// 只在 src 文件夹下查找
include: [resolve('src')],
// 不会去查找的路径
exclude: /node_modules/
}
]
}
}
对于 Babel 来说,希望只作用在 JS 代码上的,然后 node_modules 中使用的代码都是编译过的,所以完全没有必要再去处理一遍。
当然这样做还不够,还可以将 Babel 编译过的文件缓存起来,下次只需要编译更改过的代码文件即可,这样可以大幅度加快打包时间
loader: 'babel-loader?cacheDirectory=true'
受限于 Node 是单线程运行的,所以 Webpack 在打包的过程中也是单线程的,特别是在执行 Loader 的时候,长时间编译的任务很多,这样就会导致等待的情况。
HappyPack 可以将 Loader 的同步执行转换为并行的,这样就能充分利用系统资源来加快打包效率了
module: {
loaders: [
{
test: /\.js$/,
include: [resolve('src')],
exclude: /node_modules/,
// id 后面的内容对应下面
loader: 'happypack/loader?id=happybabel'
}
]
},
plugins: [
new HappyPack({
id: 'happybabel',
loaders: ['babel-loader?cacheDirectory'],
// 开启 4 个线程
threads: 4
})
]
DllPlugin 可以将特定的类库提前打包然后引入。这种方式可以极大的减少打包类库的次数,只有当类库更新版本才有需要重新打包,并且也实现了将公共代码抽离成单独文件的优化方案。DllPlugin的使用方法如下:
// 单独配置在一个文件中
// webpack.dll.conf.js
const path = require('path')
const webpack = require('webpack')
module.exports = {
entry: {
// 想统一打包的类库
vendor: ['react']
},
output: {
path: path.join(__dirname, 'dist'),
filename: '[name].dll.js',
library: '[name]-[hash]'
},
plugins: [
new webpack.DllPlugin({
// name 必须和 output.library 一致
name: '[name]-[hash]',
// 该属性需要与 DllReferencePlugin 中一致
context: __dirname,
path: path.join(__dirname, 'dist', '[name]-manifest.json')
})
]
}
然后需要执行这个配置文件生成依赖文件,接下来需要使用 DllReferencePlugin 将依赖文件引入项目中
// webpack.conf.js
module.exports = {
// ...省略其他配置
plugins: [
new webpack.DllReferencePlugin({
context: __dirname,
// manifest 就是之前打包出来的 json 文件
manifest: require('./dist/vendor-manifest.json'),
})
]
}
在 Webpack3 中,一般使用 UglifyJS 来压缩代码,但是这个是单线程运行的,为了加快效率,可以使用 webpack-parallel-uglify-plugin 来并行运行 UglifyJS,从而提高效率。
在 Webpack4 中,不需要以上这些操作了,只需要将 mode 设置为 production 就可以默认开启以上功能。代码压缩也是我们必做的性能优化方案,当然我们不止可以压缩 JS 代码,还可以压缩 HTML、CSS 代码,并且在压缩 JS 代码的过程中,我们还可以通过配置实现比如删除 console.log 这类代码的功能。
可以通过一些小的优化点来加快打包速度
resolve.extensions:用来表明文件后缀列表,默认查找顺序是 ['.js', '.json'],如果你的导入文件没有添加后缀就会按照这个顺序查找文件。我们应该尽可能减少后缀列表长度,然后将出现频率高的后缀排在前面resolve.alias:可以通过别名的方式来映射一个路径,能让 Webpack 更快找到路径module.noParse:如果你确定一个文件下没有其他依赖,就可以使用该属性让 Webpack 不扫描该文件,这种方式对于大型的类库很有帮助COOKIE是最早被提出来的本地存储方式,在此之前,服务端是无法判断网络中的两个请求是否是同一用户发起的,为解决这个问题,COOKIE就出现了。COOKIE的大小只有4kb,它是一种纯文本文件,每次发起HTTP请求都会携带COOKIE。
COOKIE的特性:
如果需要域名之间跨域共享COOKIE,有两种方法:
COOKIE的使用场景:
LocalStorage是HTML5新引入的特性,由于有的时候我们存储的信息较大,COOKIE就不能满足我们的需求,这时候LocalStorage就派上用场了。
LocalStorage的优点:
LocalStorage的缺点:
LocalStorage的常用API:
// 保存数据到 localStorage
localStorage.setItem('key', 'value');
// 从 localStorage 获取数据
let data = localStorage.getItem('key');
// 从 localStorage 删除保存的数据
localStorage.removeItem('key');
// 从 localStorage 删除所有保存的数据
localStorage.clear();
// 获取某个索引的Key
localStorage.key(index)
LocalStorage的使用场景:
SessionStorage和LocalStorage都是在HTML5才提出来的存储方案,SessionStorage 主要用于临时保存同一窗口(或标签页)的数据,刷新页面时不会删除,关闭窗口或标签页之后将会删除这些数据。
SessionStorage与LocalStorage对比:
SessionStorage的常用API:
// 保存数据到 sessionStorage
sessionStorage.setItem('key', 'value');
// 从 sessionStorage 获取数据
let data = sessionStorage.getItem('key');
// 从 sessionStorage 删除保存的数据
sessionStorage.removeItem('key');
// 从 sessionStorage 删除所有保存的数据
sessionStorage.clear();
// 获取某个索引的Key
sessionStorage.key(index)
SessionStorage的使用场景
实现多个标签页之间的通信,本质上都是通过中介者模式来实现的。因为标签页之间没有办法直接通信,因此我们可以找一个中介者,让标签页和中介者进行通信,然后让这个中介者来进行消息的转发。通信方法如下:
function A(){
}
function B(a){
this.a = a;
}
function C(a){
if(a){
this.a = a;
}
}
A.prototype.a = 1;
B.prototype.a = 1;
C.prototype.a = 1;
console.log(new A().a);
console.log(new B().a);
console.log(new C(2).a);
输出结果:1 undefined 2
解析:
理论上,既然样式表不改变 DOM 树,也就没有必要停下文档的解析等待它们。然而,存在一个问题,Javascript 脚本执行时可能在文档的解析过程中请求样式信息,如果样式还没有加载和解析,脚本将得到错误的值,显然这将会导致很多问题。所以如果浏览器尚未完成 CSSOM 的下载和构建,而我们却想在此时运行脚本,那么浏览器将延迟 Javascript 脚本执行和文档的解析,直至其完成 CSSOM 的下载和构建。也就是说,在这种情况下,浏览器会先下载和构建 CSSOM,然后再执行 Javascript,最后再继续文档的解析。
function Foo(){
Foo.a = function(){
console.log(1);
}
this.a = function(){
console.log(2)
}
}
Foo.prototype.a = function(){
console.log(3);
}
Foo.a = function(){
console.log(4);
}
Foo.a();
let obj = new Foo();
obj.a();
Foo.a();
输出结果:4 2 1
解析:
console.log(1)
setTimeout(() => {
console.log(2)
})
new Promise(resolve => {
console.log(3)
resolve(4)
}).then(d => console.log(d))
setTimeout(() => {
console.log(5)
new Promise(resolve => {
resolve(6)
}).then(d => console.log(d))
})
setTimeout(() => {
console.log(7)
})
console.log(8)
输出结果如下:
1
3
8
4
2
5
6
7
代码执行过程如下:
(1)针对Javascript: Javascript既会阻塞HTML的解析,也会阻塞CSS的解析。因此我们可以对Javascript的加载方式进行改变,来进行优化:
(1)尽量将Javascript文件放在body的最后
(2) body中间尽量不要写标签
(3)标签的引入资源方式有三种,有一种就是我们常用的直接引入,还有两种就是使用 async 属性和 defer 属性来异步引入,两者都是去异步加载外部的JS文件,不会阻塞DOM的解析(尽量使用异步加载)。三者的区别如下:
(2)针对CSS:使用CSS有三种方式:使用link、@import、内联样式,其中link和@import都是导入外部样式。它们之间的区别:
外部样式如果长时间没有加载完毕,浏览器为了用户体验,会使用浏览器会默认样式,确保首次渲染的速度。所以CSS一般写在headr中,让浏览器尽快发送请求去获取css样式。
所以,在开发过程中,导入外部样式使用link,而不用@import。如果css少,尽可能采用内嵌样式,直接写在style标签中。
(3)针对DOM树、CSSOM树: 可以通过以下几种方式来减少渲染的时间:
(4)减少回流与重绘:
table布局, 一个小的改动可能会使整个table进行重新布局documentFragment,在它上面应用所有DOM操作,最后再把它添加到文档中display: none,操作结束后再把它显示出来。因为在display属性为none的元素上进行的DOM操作不会引发回流和重绘。浏览器针对页面的回流与重绘,进行了自身的优化——渲染队列
浏览器会将所有的回流、重绘的操作放在一个队列中,当队列中的操作到了一定的数量或者到了一定的时间间隔,浏览器就会对队列进行批处理。这样就会让多次的回流、重绘变成一次回流重绘。
将多个读操作(或者写操作)放在一起,就会等所有的读操作进入队列之后执行,这样,原本应该是触发多次回流,变成了只触发一次回流。







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有