from torch.nn.init import xavier_uniform_, xavier_normal_ from torch.nn.init import kaiming_uniform_, kaiming_normal_
2. 各种初始化方法分析
xavier_uniform_(tensor, gain=1.0)
Note: 以均匀分布的值初始化输入tensor. 方法根据《Understanding the difficulty of training deep feedforward neural networks – Glorot, X. & Bengio, Y. (2010)》论文实现。最终得到的Tesor值取样于U(−a,a) ,
其中: \
参数:
gain: 缩放因素(optional)
xavier_normal_(tensor, gain=1.0)
Note: 以正太分布的值初始化输入tensor. 方法根据《Understanding the difficulty of training deep feedforward neural networks – Glorot, X. & Bengio, Y. (2010)》论文实现。最终得到的Tesor值取样于,
Note: 以均匀分布的值初始化输入tensor. 方法根据《Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification – He, K. et al. (2015)》论文实现。最终得到的Tesor值取样于U(−bound,bound) ,
Note: 以正太分布的值初始化输入tensor. 方法根据《Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification – He, K. et al. (2015)》论文实现。最终得到的Tesor值取样于,
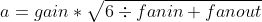 \
\ ,
,


![[转载]从零开始学习OpenGL ES之四 – 光效](https://img.php1.cn/3cd4a/18ace/696/1d8e759bd3e6bbec.jpeg)





 京公网安备 11010802041100号
京公网安备 11010802041100号