示例代码和语料库来自于博客:(宝藏博主,其它博客对学习NLP很有用)
https://wmathor.com/index.php/archives/1443/
https://wmathor.com/index.php/archives/1435/
语料库下载地址:https://pan.baidu.com/s/10Bd3JxCCFTjBPNt0YROvZA 提取码:81fo
skip-gram是word2vec的一种训练方法,是核心思想是用中心词预测周围词,相比起用周围词预测中心词的CBOW训练方法,skip-gram训练的“难度更大”,因此训练出来的词向量往往也要比CBOW的要好一些。
从理论到代码最重要的一步就是要认识到在用中心词预测周围词的时候,比如当我们指定窗口为2,那么左右的周围词共有四个,skip-gram的训练过程不是一次性用中心词预测四个词,而是中心词和一个周围词组成一个训练样本,有4个周围词的话就有4个样本,即[中心词,周围词1]、[中心词,周围词2]...
在这个简易的实现版本中,只有一个相关的词向量矩阵,没有中心词矩阵和周围词矩阵,也不会涉及层次softmax或负采样这些优化措施,只是展现了最核心的一些原理。
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import torch.utils.data as Datadtype = torch.FloatTensor
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
这里没有使用大规模的语料库,只是使用了几句话,虽然数据很简单,但是在后面还是准备了相关的Dataset和Dataloader,在大规模语料库中,代码还是可以复用的。
# 文本预处理
sentences = ["jack like dog", "jack like cat", "jack like animal","dog cat animal", "banana apple cat dog like", "dog fish milk like","dog cat animal like", "jack like apple", "apple like", "jack like banana","apple banana jack movie book music like", "cat dog hate", "cat dog like"]word_sequence = " ".join(sentences).split() # ['jack', 'like', 'dog', 'jack', 'like', 'cat', 'animal',...]
vocab = list(set(word_sequence)) # build words vocabulary,去重
word2idx = {w: i for i, w in enumerate(vocab)} # {'apple': 0, 'fish': 1,..., },注意,不固定!!!不一定apple对应的就是0,在真实的源码中,是按照词频来排序、分配序号的。
# 模型的相关参数
batch_size = 8
embedding_size = 2 # 词向量的维度是2
C = 2 # window size,即左右各两个周围词
voc_size = len(vocab) # 词典的大小
注意:其实这里的中心词和周围词的构建不应该遍历下面代码中的word_sequence来实现,下面代码错误的把每句话首位相连,但是不同的话之前其实是没有上下文关系的,所以这里需要处理下!需要遍历每句话来处理,而不是遍历整个word_sequence,感兴趣的可以改写下代码。
# 数据预处理
skip_grams = []
print(word2idx)
for idx in range(C, len(word_sequence) - C):center = word2idx[word_sequence[idx]] # 中心词context_idx = list(range(idx - C, idx)) + list(range(idx + 1, idx + C + 1)) # 中心词左边的2个词+中心词右边的两个词cOntext= [word2idx[word_sequence[i]] for i in context_idx]for w in context:skip_grams.append([center, w]) # 中心词和每个周围词组成一个训练样本def make_data(skip_grams):input_data = []output_data = []for i in range(len(skip_grams)):# input_data转换为one-hot形式,output_data合成一个listinput_data.append(np.eye(voc_size)[skip_grams[i][0]])output_data.append(skip_grams[i][1])return input_data, output_dataprint(skip_grams)
input_data, output_data = make_data(skip_grams)
print(input_data)
print(output_data)
input_data, output_data = torch.Tensor(input_data), torch.LongTensor(output_data)
dataset = Data.TensorDataset(input_data, output_data)
loader = Data.DataLoader(dataset, batch_size, True)
"""
skip_grams: [[10, 2],[9, 8], [11, 5], ..., [11, 7], [11, 10], [11, 0]]
input_data: [array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0.]),...]
output_data: [2, 0, 2, 0, 0, 10, 0, 11, 10, 2, 11, 2, 2, 0, 2, 0, 0, 11, 0, 8, 11, 2, 8, 10, 2, 0, 10,...]
"""
# 构建模型
class Word2Vec(nn.Module):def __init__(self):super(Word2Vec, self).__init__()# W:one-hot到词向量的hidden layerself.W = nn.Parameter(torch.randn(voc_size, embedding_size).type((dtype)))# V:输出层的参数self.V = nn.Parameter(torch.randn(embedding_size, voc_size).type((dtype)))def forward(self, X):# X : [batch_size, voc_size] one-hot# torch.mm only for 2 dim matrix, but torch.matmul can use to any dimhidden_layer = torch.matmul(X, self.W) # hidden_layer : [batch_size, embedding_size]output_layer = torch.matmul(hidden_layer, self.V) # output_layer : [batch_size, voc_size]return output_layermodel = Word2Vec().to(device)
criterion = nn.CrossEntropyLoss().to(device) # 多分类,交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=1e-3) # Adam优化算法
# 训练
for epoch in range(2000):for i, (batch_x, batch_y) in enumerate(loader):batch_x = batch_x.to(device)batch_y = batch_y.to(device)pred = model(batch_x)loss = criterion(pred, batch_y)if (epoch + 1) % 1000 == 0:print(epoch + 1, i, loss.item())optimizer.zero_grad()loss.backward()optimizer.step()# 将每个词在平面直角坐标系中标记出来,看看各个词之间的距离
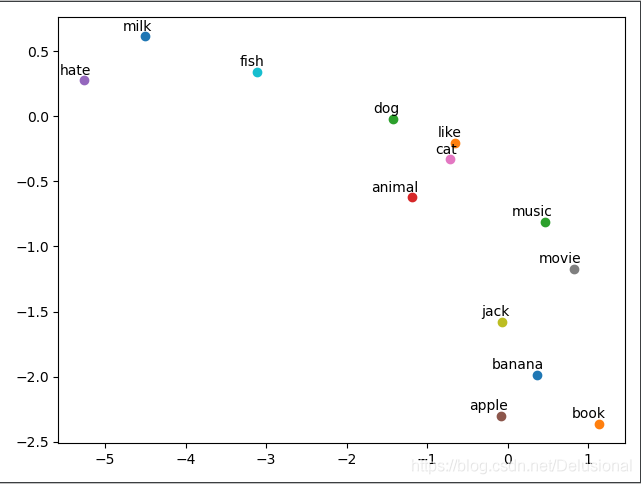
for i, label in enumerate(vocab):W, WT = model.parameters()# W是词向量矩阵x, y = float(W[i][0]), float(W[i][1])plt.scatter(x, y)plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom')
plt.show()
可视化的效果很一般,可能受限于语料库和数据的处理
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import torch.utils.data as Datadtype = torch.FloatTensor
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 文本预处理
sentences = ["jack like dog", "jack like cat", "jack like animal","dog cat animal", "banana apple cat dog like", "dog fish milk like","dog cat animal like", "jack like apple", "apple like", "jack like banana","apple banana jack movie book music like", "cat dog hate", "cat dog like"]word_sequence = " ".join(sentences).split() # ['jack', 'like', 'dog', 'jack', 'like', 'cat', 'animal',...]
vocab = list(set(word_sequence)) # build words vocabulary,去重
word2idx = {w: i for i, w in enumerate(vocab)} # {'apple': 0, 'fish': 1,..., },注意,不固定!!!# 模型的相关参数
batch_size = 8
embedding_size = 2 # 词向量的维度是2
C = 2 # window size
voc_size = len(vocab)# 数据预处理
skip_grams = []
print(word2idx)
for idx in range(C, len(word_sequence) - C):center = word2idx[word_sequence[idx]] # 中心词context_idx = list(range(idx - C, idx)) + list(range(idx + 1, idx + C + 1)) # 中心词左边的2个词+中心词右边的两个词cOntext= [word2idx[word_sequence[i]] for i in context_idx]for w in context:skip_grams.append([center, w]) # 中心词和每个周围词组成一个训练样本def make_data(skip_grams):input_data = []output_data = []for i in range(len(skip_grams)):# input_data转换为one-hot形式,output_data合成一个listinput_data.append(np.eye(voc_size)[skip_grams[i][0]])output_data.append(skip_grams[i][1])return input_data, output_dataprint(skip_grams)
input_data, output_data = make_data(skip_grams)
print(input_data)
print(output_data)
input_data, output_data = torch.Tensor(input_data), torch.LongTensor(output_data)
dataset = Data.TensorDataset(input_data, output_data)
loader = Data.DataLoader(dataset, batch_size, True)
"""
skip_grams: [[10, 2],[9, 8], [11, 5], ..., [11, 7], [11, 10], [11, 0]]
input_data: [array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0.]),...]
output_data: [2, 0, 2, 0, 0, 10, 0, 11, 10, 2, 11, 2, 2, 0, 2, 0, 0, 11, 0, 8, 11, 2, 8, 10, 2, 0, 10,...]
"""# 构建模型
class Word2Vec(nn.Module):def __init__(self):super(Word2Vec, self).__init__()self.W = nn.Parameter(torch.randn(voc_size, embedding_size).type((dtype)))self.V = nn.Parameter(torch.randn(embedding_size, voc_size).type((dtype)))def forward(self, X):# X : [batch_size, voc_size] one-hot# torch.mm only for 2 dim matrix, but torch.matmul can use to any dimhidden_layer = torch.matmul(X, self.W) # hidden_layer : [batch_size, embedding_size]output_layer = torch.matmul(hidden_layer, self.V) # output_layer : [batch_size, voc_size]return output_layermodel = Word2Vec().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)# 训练
for epoch in range(2000):for i, (batch_x, batch_y) in enumerate(loader):batch_x = batch_x.to(device)batch_y = batch_y.to(device)pred = model(batch_x)loss = criterion(pred, batch_y)if (epoch + 1) % 1000 == 0:print(epoch + 1, i, loss.item())optimizer.zero_grad()loss.backward()optimizer.step()# 将每个词在平面直角坐标系中标记出来,看看各个词之间的距离
for i, label in enumerate(vocab):W, WT = model.parameters()# W是词向量矩阵x, y = float(W[i][0]), float(W[i][1])plt.scatter(x, y)plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom')
plt.show()# https://wmathor.com/index.php/archives/1443/
这个版本和之前不同的是:
1.用大规模的语料训练
2.设计了中心词和周围词两个词向量矩阵
3.采用了负采样的方法来优化训练过程
在训练skip-gram的时候,最后一层的激活函数的是softmax,输出层神经元的数量是词典所有单词的大小,当训练的语料库很大的时候,词典也非常大,神经网络的训练过程也会变的十分低效。负采样的思想就是减少最后一层分类的个数,我们要的是尽量增大P(周围词|中心词)的概率,减小P(非周围词|中心词)的概率,对于每个中心词,非周围词的数量肯定比周围词的数量要多的多,负采样的做法就是在随机在词典中选取一定数量的词,这个数量通常与周围词的多少有关,window size设置的越大,周围词越多,所需要的非周围词的负样本也就要越多。随机选取的词要避免它是周围词或者中心词的情况,以随机负样本的概率,代替整体负样本的概率。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as tudfrom collections import Counter
import numpy as np
import randomimport scipy
from sklearn.metrics.pairwise import cosine_similarityrandom.seed(1)
np.random.seed(1)
torch.manual_seed(1)C = 3 # 背景词
K = 15 # 负采样的噪声词
epoch = 2 # 训练的迭代次数
MAX_VOCAB_SIZE = 10000 # 词典中最大单词的数量,训练9999个词的词向量,还有一个是
EMBEDDING_SIZE = 100 # 词向量维度
batch_size = 32 # 每次训练的样本数量
lr = 0.2 # 优化器的step
语料库下载地址:https://pan.baidu.com/s/10Bd3JxCCFTjBPNt0YROvZA 提取码:81fo
文件中的内容是处理过的英文文本,去除了标点,每个单词用空格隔开,这里只使用了其中的train.txt
# 为文件中出现频率最高的前9999个单词构建词向量
with open('text8.train.txt') as f:text = f.read() # 得到文本内容text = text.lower().split() # 分割成单词列表
vocab_dict = dict(Counter(text).most_common(MAX_VOCAB_SIZE - 1)) # 得到单词字典表,key是单词,value是次数
vocab_dict['
word2idx = {word:i for i, word in enumerate(vocab_dict.keys())}
idx2word = {i:word for i, word in enumerate(vocab_dict.keys())}
word_counts = np.array([count for count in vocab_dict.values()], dtype=np.float32)
word_freqs = word_counts / np.sum(word_counts) # 文本的出现频率
word_freqs = word_freqs ** (3./4.) # 频率变为原来的0.75次方
word_freqs 存储了每个单词的频率,然后又将所有的频率变为原来的 0.75 次方,因为 word2vec 论文里面推荐这么做,不改变这个值也可以。
接下来我们需要实现一个 DataLoader,DataLoader 可以帮助我们轻松打乱数据集,迭代的拿到一个 mini-batch 的数据等。一个 DataLoader 需要以下内容:
为了使用 DataLoader,我们需要定义以下两个 function
__len__():返回整个数据集有多少 item__getitem__(idx):根据给定的 idx 返回一个 item这里有一个好的 tutorial 介绍如何使用 PyTorch DataLoader
class WordEmbeddingDataset(tud.Dataset):def __init__(self, text, word2idx, word_freqs):''' text: a list of words, all text from the training datasetword2idx: the dictionary from word to indexword_freqs: the frequency of each word'''super(WordEmbeddingDataset, self).__init__() # 通过父类初始化模型,然后重写两个方法self.text_encoded = [word2idx.get(word, word2idx['
每一行代码详细的注释都写在上面了,其中有一行代码需要特别说明一下,就是注释了 tensor (list) 的那一行,因为 text_encoded 本身是个 tensor,而传入的 pos_indices 是一个 list。下面举个例子就很好理解这句代码的作用了
# 这里的B可以看成是索引
a = torch.tensor([2, 3, 3, 8, 4, 6, 7, 8, 1, 3, 5, 0], dtype=torch.long)
b = [2, 3, 5, 6]
print(a[b])
# tensor([3, 8, 6, 7])
通过下面两行代码即可得到 DataLoader
dataset = WordEmbeddingDataset(text, word2idx, word_freqs)
dataloader = tud.DataLoader(dataset, batch_size, shuffle=True)# dataloader的结果
print(next(iter(dataset)))
'''
(tensor(4813),tensor([ 50, 9999, 393, 3139, 11, 5]),tensor([ 82, 0, 2835, 23, 328, 20, 2580, 6768, 34, 1493, 90, 5,110, 464, 5760, 5368, 3899, 5249, 776, 883, 8522, 4093, 1, 4159,5272, 2860, 9999, 6, 4880, 8803, 2778, 7997, 6381, 264, 2560, 32,7681, 6713, 818, 1219, 1750, 8437, 1611, 12, 42, 24, 22, 448,9999, 75, 2424, 9970, 1365, 5320, 878, 40, 2585, 790, 19, 2607,1, 18, 3847, 2135, 174, 3446, 191, 3648, 9717, 3346, 4974, 53,915, 80, 78, 6408, 4737, 4147, 1925, 4718, 737, 1628, 6160, 894,9373, 32, 572, 3064, 6, 943]))
第一个tensor是中心词
第二个是postive word
第三个是negative word
'''
模型核心:用矩阵乘法的形式代替了网络中神经元数量的变化
class EmbeddingModel(nn.Module):def __init__(self, vocab_size, embed_size):super(EmbeddingModel, self).__init__()self.vocab_size = vocab_sizeself.embed_size = embed_sizeself.in_embed = nn.Embedding(self.vocab_size, self.embed_size) # 中心词权重矩阵self.out_embed = nn.Embedding(self.vocab_size, self.embed_size) # 周围词权重矩阵def forward(self, input_labels, pos_labels, neg_labels):''' input_labels: center words, [batch_size]pos_labels: positive words, [batch_size, (window_size * 2)]neg_labels:negative words, [batch_size, (window_size * 2 * K)]return: loss, [batch_size]'''input_embedding = self.in_embed(input_labels) # [batch_size, embed_size]pos_embedding = self.out_embed(pos_labels)# [batch_size, (window * 2), embed_size]neg_embedding = self.out_embed(neg_labels) # [batch_size, (window * 2 * K), embed_size]# squeeze是挤压的意思,所以squeeze方法是删除一个维度,反之,unsqueeze方法是增加一个维度input_embedding = input_embedding.unsqueeze(2) # [batch_size, embed_size, 1],在最后一维上增加一个维度# bmm方法是两个三维张量相乘,两个tensor的维度是,(b * m * n), (b * n * k) 得到(b * m * k),相当于用矩阵乘法的形式代替了网络中神经元数量的变化# 矩阵的相乘相当于向量的点积,代表两个向量之间的相似度pos_dot = torch.bmm(pos_embedding, input_embedding) # [batch_size, (window * 2), 1]pos_dot = pos_dot.squeeze(2) # [batch_size, (window * 2)]neg_dot = torch.bmm(neg_embedding, -input_embedding) # [batch_size, (window * 2 * K), 1],这里之所以用减法是因为下面loss = log_pos + log_neg,log_neg越小越好neg_dot = neg_dot.squeeze(2) # batch_size, (window * 2 * K)]log_pos = F.logsigmoid(pos_dot).sum(1) # .sum()结果只为一个数,.sum(1)结果是一维的张量log_neg = F.logsigmoid(neg_dot).sum(1)loss = log_pos + log_negreturn -lossdef input_embedding(self):return self.in_embed.weight.detach().numpy()# forward方法返回的就是loss,这里不需要再实例化loss了
model = EmbeddingModel(MAX_VOCAB_SIZE, EMBEDDING_SIZE)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
这里要分两个 embedding 层来训练,对于任一一个词,它既有可能作为中心词出现,也有可能作为背景词出现,所以每个词需要用两个向量去表示。in_embed 训练出来的权重就是每个词作为中心词的权重。out_embed 训练出来的权重就是每个词作为背景词的权重。那么最后到底用什么向量来表示一个词呢?是中心词向量?还是背景词向量?按照 Word2Vec 论文所写,推荐使用中心词向量,所以这里最后返回的是 in_embed.weight。
作者的博客: Word2Vec 详解
for e in range(1):for i, (input_labels, pos_labels, neg_labels) in enumerate(dataloader):input_labels = input_labels.long()pos_labels = pos_labels.long()neg_labels = neg_labels.long()optimizer.zero_grad()loss = model(input_labels, pos_labels, neg_labels).mean()loss.backward()optimizer.step()if i % 100 == 0:print('epoch', e, 'iteration', i, loss.item())embedding_weights = model.input_embedding()
torch.save(model.state_dict(), "embedding-{}.th".format(EMBEDDING_SIZE))
语料库较大,训练时间会比较长
我们可以写个函数,找出与某个词相近的一些词,比方说输入 good,他能帮我找出 nice,better,best 之类的。
def find_nearest(word):index = word2idx[word]embedding = embedding_weights[index]cos_dis = np.array([scipy.spatial.distance.cosine(e, embedding) for e in embedding_weights])return [idx2word[i] for i in cos_dis.argsort()[:10]]for word in ["two", "america", "computer"]:print(word, find_nearest(word))# 输出
two ['two', 'zero', 'four', 'one', 'six', 'five', 'three', 'nine', 'eight', 'seven']
america ['america', 'states', 'japan', 'china', 'usa', 'west', 'africa', 'italy', 'united', 'kingdom']
computer ['computer', 'machine', 'earth', 'pc', 'game', 'writing', 'board', 'result', 'code', 'website']
Word2Vec 论文中给出的架构其实就一个单层神经网络,那么为什么不直接用 nn.Linear() 来训练呢?nn.Linear() 不是也能训练出一个 weight 吗?
答案是可以的,当然可以直接使用 nn.Linear(),只不过输入要改为 one-hot Encoding,而不能像 nn.Embedding() 这种方式直接传入一个 index。还有就是需要设置 bias=False,因为我们只需要训练一个权重矩阵,不训练偏置
这里给出一个使用单层神经网络来训练 Word2Vec 的博客
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as tudfrom collections import Counter
import numpy as np
import randomimport scipy
from sklearn.metrics.pairwise import cosine_similarityrandom.seed(1)
np.random.seed(1)
torch.manual_seed(1)C = 3 # 背景词
K = 15 # 负采样的噪声词
epoch = 2
MAX_VOCAB_SIZE = 10000
EMBEDDING_SIZE = 100
batch_size = 32
lr = 0.2# 读取文本数据并处理
with open('./text8/text8.train.txt') as f:text = f.read() # 得到文本内容text = text.lower().split() # 分割成单词列表
vocab_dict = dict(Counter(text).most_common(MAX_VOCAB_SIZE - 1)) # 得到单词字典表,key是单词,value是次数
vocab_dict['
print(len(vocab_dict))
word2idx = {word: i for i, word in enumerate(vocab_dict.keys())}
idx2word = {i: word for i, word in enumerate(vocab_dict.keys())}
word_counts = np.array([count for count in vocab_dict.values()], dtype=np.float32)
word_freqs = word_counts / np.sum(word_counts)
word_freqs = word_freqs ** (3. / 4.) # 将所有的频率变为原来的 0.75 次方,论文中是这样写的# 实现DataLoader
class WordEmbeddingDataset(tud.Dataset):def __init__(self, text, word2idx, word_freqs):super(WordEmbeddingDataset, self).__init__()# 单词数字化表示,如果不在词典中(前10000个,表示为UNK对应的valueself.text_encoded = [word2idx.get(word, word2idx['
dataloader = tud.DataLoader(dataset, batch_size, shuffle=True)
print(next(iter(dataset)))class EmbeddingModel(nn.Module):def __init__(self, vocab_size, embed_size):super(EmbeddingModel, self).__init__()self.vocab_size = vocab_sizeself.emded_size = embed_sizeself.in_embed = nn.Embedding(self.vocab_size, self.emded_size)self.out_embed = nn.Embedding(self.vocab_size, self.emded_size)def forward(self, input_labels, pos_labels, neg_labels):""":param input_labels: center words, [batch_size]:param pos_labels: positive words, [batch_size, (window_size * 2)]:param neg_labels: negative words, [batch_size, (window_size * 2 * K)]:return: loss, [batch_size]"""input_embedding = self.in_embed(input_labels) # [batch_size, embed_size]pos_embedding = self.out_embed(pos_labels) # [batch_size, (window * 2), embed_size]neg_embedding = self.out_embed(neg_labels) # [batch_size, (window * 2 * K), embed_size]# squeeze是挤压的意思,所以squeeze方法是删除一个维度,反之,unsqueeze方法是增加一个维度input_embedding = input_embedding.unsqueeze(2) # [batch_size, embed_size, 1],在最后一维上增加一个维度# bmm方法是两个三维张量相乘,两个tensor的维度是,(b * m * n), (b * n * k) 得到(b * m * k)pos_dot = torch.bmm(pos_embedding, input_embedding) # [batch_size, (window * 2), 1]pos_dot = pos_dot.squeeze(2) # [batch_size, (window * 2)]neg_dot = torch.bmm(neg_embedding, -input_embedding) # [batch_size, (window * 2 * K), 1]neg_dot = neg_dot.squeeze(2) # batch_size, (window * 2 * K)]log_pos = F.logsigmoid(pos_dot).sum(1) # .sum()结果只为一个数,.sum(1)结果是一维的张量log_neg = F.logsigmoid(neg_dot).sum(1)loss = log_pos + log_negreturn -lossdef input_embedding(self):return self.in_embed.weight.detach().numpy()model = EmbeddingModel(MAX_VOCAB_SIZE, EMBEDDING_SIZE)
print(model)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)# 训练模型
for e in range(1):for i, (input_labels, pos_labels, neg_labels) in enumerate(dataloader):input_labels = input_labels.long()pos_labels = pos_labels.long()neg_labels = neg_labels.long()optimizer.zero_grad()loss = model(input_labels, pos_labels, neg_labels).mean()loss.backward()if i % 100 == 0:print('epoch', e, 'iteration', i, loss.item())embedding_weights = model.input_embedding()
torch.save(model.state_dict(), "embedding-{}.th".format(EMBEDDING_SIZE))def find_nearest(word):index = word2idx[word]embedding = embedding_weights[index]cos_dis = np.array([scipy.spatial.distance.cosine(e, embedding) for e in embedding_weights])return [idx2word[i] for i in cos_dis.argsort()[:10]]for word in ["two", 'america', "computer"]:print(word, find_nearest(word))






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 
