在顺利运行官方DEMO后,我们开始学习如何使用 C++ 与 CUDA 进行交互。
高层抽象只需要我们考虑 WHAT,越到底层越需要我们了解 HOW。全部用底层实现会让我们无法聚焦核心的工作。因此,我们每次只选择比较重要的部分,用更底层的实现进行优化。
这次,让我们从 C++ front end 开始,逐步深入到 CUDA 实现。
在学习 C++ 调用 CUDA 之前,我们先了解一下 C++ 的高层封装,C++ front end。C++ front end 是 Pytorch 的 C++ 版。pytorch 利用 CPython 在它的基础上添加了一个胶水层,使我们能够用 Python 调用这些方法。
让我们来看一个简单的例子,首先,引入包:
python:
import torch
C++:
#include
建立模型:
python:
model = torch.nn.Linear(5, 1)
C++:
auto model = torch::nn::Linear(5, 1);
声明损失函数,并进行正向传播和反向传播:
python:
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
prediction = model.forward(torch.randn(3, 5))
loss = torch.nn.functional.mse_loss(prediction, torch.ones(3, 1))
loss.backward()
optimizer.step()
C++:
auto optimizer = torch::optim::SGD(model->parameters(), /*lr=*/0.1);
auto prediction = model->forward(torch::randn({3, 5}));
auto loss = torch::mse_loss(prediction, torch::ones({3, 1}));
loss.backward();
optimizer.step();
和 Pytorch 一样,在 C++ front end 中,我们无需关心 opt 的计算方式,也不需要考虑如何调用 GPU ,简单地建立模型结构,C++ front end 就会帮助我们解决这些问题。如果你想看更复杂的例子,请查阅官方文档。
现在,如果我们要自己定义一些操作,我们就会用到 C++ front end 的一些底层库。其中最为重要的是 ATEN 和 autograd。
ATEN 是一个 Tensor 库,它将数组封装为一个 Tensor 类(就像 numpy 把数组封装成 nparray)。它在 CPU 和 GPU 上,为我们提供了创建数组和操作数组的方法(没错,和 Pytorch 中的 Tensor 一样)。例如,我们可以这样使用:
#include
// 声明两个 Tensor 并相加
at::Tensor a = at::randn({2, 2}, at::kInt);
at::Tensor b = at::randn({2, 2}, at::kInt);
auto c = a + b;
// 在 GPU 声明两个 Tensor 并相加
at::Tensor a = CUDA(at::kFloat).ones({3, 4});
at::Tensor b = CUDA(at::kFloat).zeros({3, 4});
auto c = a + b;
如果只用 ATEN 库,我们需要自己实现反向传播(微分)。如果不想这么麻烦,我们就要引入 Autograd 了。它封装了 ATEN 的所有 Tensor 操作,为它们添加了自动微分的功能,使用起来和 Pytorch 相同。
#include
#include
#include
at::Tensor a = torch::randn({2, 2}, at::requires_grad());
at::Tensor b = torch::randn({2, 2});
auto c = a + b;
c.backward();
到这里,所有 Pytorch 的功能我们都可以找到 C++ 的对应实现了。如果你想了解更详细的内容,请查阅官方文档。让我打开Pytorch-CUDA从入门到放弃(一)中下载的官方 DEMO。我们应该已经可以看懂 LLTM 的正向传递(和反向传递)的 C++ 实现:
#include
std::vector
at::Tensor input,
at::Tensor weights,
at::Tensor bias,
at::Tensor old_h,
at::Tensor old_cell) {
auto X = at::cat({old_h, input}, /*dim=*/1);
// ========== C++ 实现 LLTM ==========
auto gate_weights = at::addmm(bias, X, weights.transpose(0, 1));
auto gates = gate_weights.chunk(3, /*dim=*/1);
auto input_gate = at::sigmoid(gates[0]);
auto output_gate = at::sigmoid(gates[1]);
auto candidate_cell = at::elu(gates[2], /*alpha=*/1.0);
auto new_cell = old_cell + candidate_cell * input_gate;
auto new_h = at::tanh(new_cell) * output_gate;
// ========== C++ 实现 LLTM ==========
return {new_h,
new_cell,
input_gate,
output_gate,
candidate_cell,
X,
gate_weights};
}
下面,我们开始学习使用 CUDA 函数替换上面代码中 C++ 实现的 LLTM,也就是手动操作 GPU 进行计算。
在使用 CUDA 之后,我们获得了 GPU 的控制权,现在在编写代码时需要指明是 CPU 还是 GPU 进行数据运算。我们可以简单的将数据运算(即函数的调用方式)分为三种:
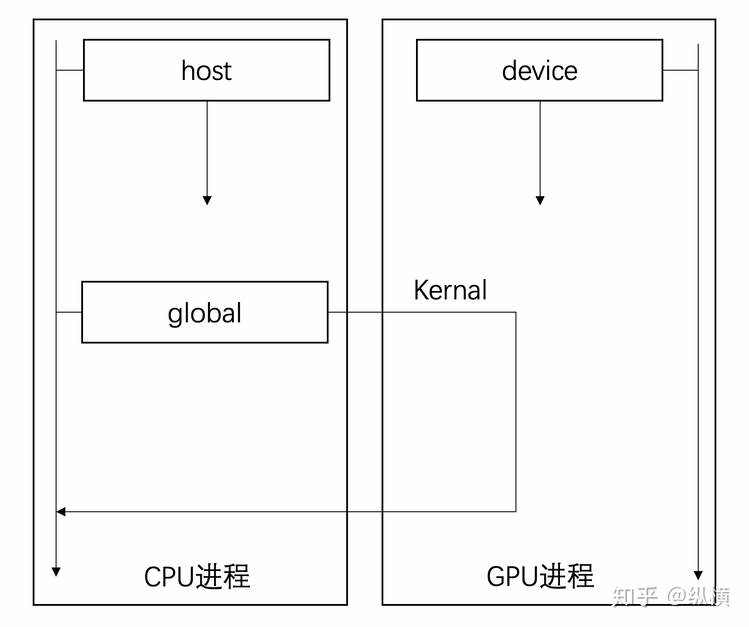
函数的调用方式
CUDA 在 C 语言的基础上添加了三个关键字区分三种不同的函数,我们现在需要这样声明:
__global__ void MyFunc(float func_input)
{
// DO SOMETHING
}
__host__ void MyFunc(int func_input)
{
// DO SOMETHING
}
__device__ void MyFunc(byte func_input)
{
// DO SOMETHING
}
__global__ 和 __device__ 声明的函数,在调用时会被分配给 CUDA 中众多的核,在多个线程中执行。因此在调用函数时,我们需要告诉 GPU,哪些线程要执行该函数。由于 GPU 的线程太多了,因此我们为 GPU 的线程划分了国(grid)-省(block)-市(thread)的分级。
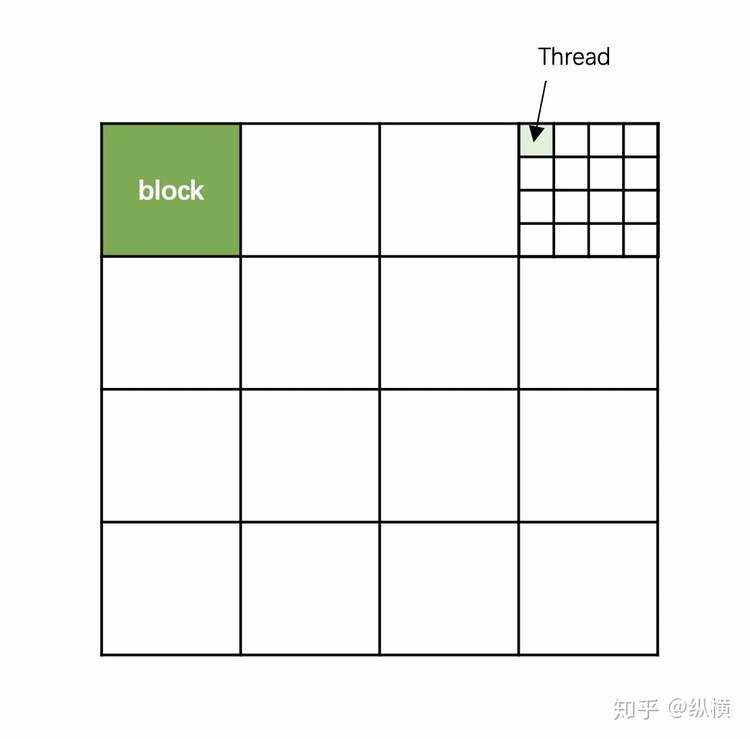
一个grid
在一个 grid 中也有很多 block。让我们来声明一个有 4*4 个 block 的 grid:
// dim3 代表一个三元组
// 在学习过程中我们只考虑二维问题,因此只定义 x 和 y
dim3 grid(4, 4);
这时候深绿色 block 有自己的位置:
// 第一行 第一列
blockId.x = 1;
blockId.y = 1;
一个 block 中有很多 thread。让我们定义一个有 4*4 个 thread 的 block:
// dim3 代表一个三元组
// 在学习过程中我们只考虑二维问题,因此只定义 x 和 y
dim3 block(4, 4);
这时候 thread 也有自己的位置。让我们看一下浅绿色的 Thread 的位置:
// block 第一行 第四列
blockId.x = 1;
blockId.y = 4;
// thread 第一行 第一列
threadId.x = 1;
threadId.y = 1;
现在,你可以让一个函数去管理自己的线程们了。还记得我们之前讨论的吗,要在 main 中(CPU 中)调用 GPU 进行计算,我们要用 global 关键字修饰。在调用函数的时候需要为函数(按级别)分配 GPU 线程:
// 定义
__global__ void MyFunc(float func_input)
{
DO SOMETHING
}
int main()
{
...
// 领土范围
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(16, 16);
// 调用
MatAdd<<
...
}
在 MyFunc 中,CUDA 已经为我们注入了关键字 blockId 和 threadId 用于获取 thread 的位置,在矩阵运算中,我们通常会将矩阵中的元素与 GPU 中的 thread 一一对应:
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N])
{
// 这里就获取了当前市 thread 的位置
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
// 根据位置 thread 情况计算
if (i
}
CPU 的内润和 GPU 的内存是两个独立的空间。我们现在已经能够通过 global function(kernal)指定 GPU 对 GPU 内存上的数据进行加工了。然而,我们怎样把 CPU 内存的数据传送到 GPU 内存,又怎样传输回来呢。
我们先看一下 global function 能运过去什么,运回来什么:
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]) ;
global 函数的输入是有限的,因此无法用来传输数组(的内容),但是可以用来传递数组的(CPU 内存或 GPU 内存)地址。global 函数的返回时 void,没有什么用。
因此我们需要一个接口,把 CPU 内存上的数据传送到 GPU 内存,然后告诉我们 GPU 内存上的位置。我们就可以通过 global function 对指定 GPU 内存的数据进行操作了。CUDA 是这样实现的:通过 cudaMalloc 在 GPU 上申请一块空间并获得空间的地址,再通过 cudaMemcpyHostToDevice 把数据放在这块空间(利用前面获得的地址),最后再把数据的地址(就是前面获得的地址)作为输入传递给 global function。
float *func_input_in_device;
float func_input[] = [...]
cudaMalloc((void**)&func_input_in_device, nBytes);
cudaMemcpy((void*)func_input_in_device, (void*)x, nBytes, cudaMemcpyHostToDevice);
dim3 blockSize(16,16);
dim3 gridSize(16,16);
MyFunc <<
获得返回也是一样,通过 cudaMalloc 在 GPU 上申请一块空间并获得空间的地址,再把这块空间的地址(就是前面获得的地址)作为输入传递给 global function 留给 GPU 填充结果,最后再通过 cudaMemcpyDeviceToHost 把地址指定的数据拷贝回来。
float *func_input_in_device;
cudaMalloc((void**)&func_input_in_device, nBytes);
cudaMemcpy((void*)func_input_in_device, (void*)x, nBytes, cudaMemcpyHostToDevice);
float *func_output_in_device;
cudaMalloc((void**)&func_output_in_device, nBytes);
float *func_output
func_outputs = (float*)malloc(nBytes);
dim3 blockSize(16,16);
dim3 gridSize(16,16);
MyFunc <<
cudaMemcpy((void*)func_output, (void*)func_output_in_device, nBytes, cudaMemcpyDeviceToHost);
你可能注意到,我们之前强调过,的计算是异步的。你是否觉得 cudaMemcpy 不一定会拿到我们期望的计算结果?其实,运算过程是这样的:
MyFunc1 <<<...>>>(...);
// MyFunc1加入GPU的任务队列,CPU不等待GPU的执行结果继续向下执行
MyFunc2 <<<...>>>(...);
//MyFunc2加入GPU的任务队列,等待MyFunc2执行完毕后执行,CPU不等待GPU的执行结果继续向下执行
cudaMemcpy(...);
// CPU被阻塞,等待GPU完成任务队列中所有任务后开始从GPU拷贝数据,直到拷贝完成再向下执行
由于这样写太复杂(需要来回拷贝),因此 CUDA 提供了一个语法糖进行简化。我们可以直接使用 cudaMallocManaged 开辟一个 CPU 和 GPU 都能访问到的公共空间。使用这个接口,我们不再需要手动对数据进行复制,但是其实原理和上面相同。
float *func_input, *func_output;
cudaMallocManaged(&func_input, nBytes);
cudaMallocManaged(&func_output, nBytes);
for (int i = 0; i
}
MyFunc <<
// CPU 可以拿到 func_output
需要注意的是,GPU 和公共区域上开辟的空间不会自动释放,需要我们手动调用 cudaFree 释放:
cudaFree(func_input)
cudaFree(func_output)
其实,这部分内容并不常用,因为大部分时候我们都会直接对 Tensor.data 进行操作生成一个结果赋给另一个 Tensor.data,而 Tensor.data 是被 ATEN 分配在 GPU 上的,也就不涉及到和 CPU 进行数据交换的问题了。
在 CPU 上我们有各种各样的函数库,然而这些函数库无法直接在 GPU 上(global function里)调用。不过不要担心,CUDA 本身为我们提供了丰富的函数库。
我们常用的数学运算在 CUDA math 中:
#include
#include
template
__device__ __forceinline__ scalar_t sigmoid(scalar_t z) {
return 1.0 / (1.0 + exp(-z));
// exp 函数
}
矩阵运算在 cuBLAS 中:
...
// 创建 handle
cublasHandle_t handle;
cublasCreate(&handle);
// 调用函数,传入计算所需参数
cublasSgemm(handle,CUBLAS_OP_N,CUBLAS_OP_N,1,3,2,&alpha,d_b,1,d_a,2,&beta,d_c,1);
利用这些库,我们可以将 LLTM 用到的操作用 CUDA 重构:
template
__device__ __forceinline__ scalar_t d_sigmoid(scalar_t z) {
const auto s = sigmoid(z);
return (1.0 - s) * s;
}
template
__device__ __forceinline__ scalar_t d_tanh(scalar_t z) {
const auto t = tanh(z);
return 1 - (t * t);
}
template
__device__ __forceinline__ scalar_t elu(scalar_t z, scalar_t alpha = 1.0) {
return fmax(0.0, z) + fmin(0.0, alpha * (exp(z) - 1.0));
}
template
__device__ __forceinline__ scalar_t d_elu(scalar_t z, scalar_t alpha = 1.0) {
const auto e = exp(z);
const auto d_relu = z <0.0 ? 0.0 : 1.0;
return d_relu + (((alpha * (e - 1.0)) <0.0) ? (alpha * e) : 0.0);
}
template
__global__ void lltm_cuda_forward_kernel(
const scalar_t* __restrict__ gates,
const scalar_t* __restrict__ old_cell,
scalar_t* __restrict__ new_h,
scalar_t* __restrict__ new_cell,
scalar_t* __restrict__ input_gate,
scalar_t* __restrict__ output_gate,
scalar_t* __restrict__ candidate_cell,
size_t state_size) {
const int column = blockIdx.x * blockDim.x + threadIdx.x;
const int index = blockIdx.y * state_size + column;
const int gates_row = blockIdx.y * (state_size * 3);
if (column
output_gate[index] = sigmoid(gates[gates_row + state_size + column]);
candidate_cell[index] = elu(gates[gates_row + 2 * state_size + column]);
new_cell[index] =
old_cell[index] + candidate_cell[index] * input_gate[index];
new_h[index] = tanh(new_cell[index]) * output_gate[index];
}
}
ATEN 与 CUDA 交互实际上就是在解决 global function 的输入输出问题。我们需要将 ATEN 声明的 Tensor 转换成 global function 可以接受的数据,在 global function 处理后再将其输出转化为 ATEN 可以接受的形式。
值得庆幸的是,ATEN 的数据(CUDA Tensor)和 global function 的计算结果都在 GPU 中。因此不涉及到拷贝或是公共内存的问题。唯一需要考虑的是,ATEN 的数据数据类型和 global function 不同。
ATEN 为我们提供了接口函数 AT_DISPATCH_FLOATING_TYPES。这个函数接收三个参数,第一个参数是输入数据的源类型,第二个参数是操作的标识符(用于报错显示),第三个参数是一个匿名函数。在匿名函数运行结束后,AT_DISPATCH_FLOATING_TYPES 会将 Float 数组转化为目标类型(运行中的实际类型)数组。
有些同学可能不了解 C++ 的匿名函数,其实就是一个省略了函数名称的函数:
[](int x, int y) { return x + y; }
// [配置](参数){程序体}
[&](int x, int y) { return x + y; }
// 参数按引用传递
[=](int x, int y) { return x + y; }
// 参数按值传递
AT_DISPATCH_FLOATING_TYPES 中的匿名函数中可以使用 scalar_t 代指目标类型。而 ATEN 支持我们使用 Tensor.data<类型> 将 Tensor.data 转换为某个类型。因此,可以这样转换:
AT_DISPATCH_FLOATING_TYPES(gates.type(), "lltm_forward_cuda", ([&] {
lltm_cuda_forward_kernel
gates.data
old_cell.data
new_h.data
new_cell.data
input_gate.data
output_gate.data
candidate_cell.data
state_size);
}));
到这里,我们已经可以把原来 C++ 实现的 forward 中核心的部分替换为 CUDA 实现了:
std::vector
at::Tensor input,
at::Tensor weights,
at::Tensor bias,
at::Tensor old_h,
at::Tensor old_cell) {
auto X = at::cat({old_h, input}, /*dim=*/1);
auto gates = at::addmm(bias, X, weights.transpose(0, 1));
const auto batch_size = old_cell.size(0);
const auto state_size = old_cell.size(1);
auto new_h = at::zeros_like(old_cell);
auto new_cell = at::zeros_like(old_cell);
auto input_gate = at::zeros_like(old_cell);
auto output_gate = at::zeros_like(old_cell);
auto candidate_cell = at::zeros_like(old_cell);
const int threads = 1024;
const dim3 blocks((state_size + threads - 1) / threads, batch_size);
AT_DISPATCH_FLOATING_TYPES(gates.type(), "lltm_forward_cuda", ([&] {
lltm_cuda_forward_kernel
gates.data
old_cell.data
new_h.data
new_cell.data
input_gate.data
output_gate.data
candidate_cell.data
state_size);
}));
return {new_h, new_cell, input_gate, output_gate, candidate_cell, X, gates};
}
如果你有耐心看到这里,很快就能入门啦~ 有些同学私信我官方文档的 Demo 比较复杂,所以我手写了 Dense 扩展上传在了 Github 上面。讲解从 Python extension 优化到 CPP extension 再到 CUDA extension 的过程。感兴趣的同学可以照着实现一遍,有什么问题可以提 issue 或者留言。重复一下:
所以我手写了 Dense 扩展上传在了 Github 上面
所以我手写了 Dense 扩展上传在了 Github 上面
所以我手写了 Dense 扩展上传在了 Github 上面
在下一部分中,我们会学习将写好的 C++/CUDA 代码接入 python 的多种方式,并对代码进行自顶向下的单元测试和 DEBUG。





 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有