这是个啥:
logging的主入口只有一个,那就是日志处理的主对象。至于要输送记录内容到哪里、怎么组织记录这些内容、怎么过滤这些问题本质上都是属于数据进入主入口之后的对输入内容的个性化加工处理方式,而这些处理方式都是通过addHandler添加进去,logging中包含的handler主要有如下几种:
handler名称:位置;作用StreamHandler:logging.StreamHandler;日志输出到流,可以是sys.stderr,sys.stdout或者文件
FileHandler:logging.FileHandler;日志输出到文件
BaseRotatingHandler:logging.handlers.BaseRotatingHandler;基本的日志回滚方式
RotatingHandler:logging.handlers.RotatingHandler;日志回滚方式,支持日志文件最大数量和日志文件回滚
TimeRotatingHandler:logging.handlers.TimeRotatingHandler;日志回滚方式,在一定时间区域内回滚日志文件
SocketHandler:logging.handlers.SocketHandler;远程输出日志到TCP/IP sockets
DatagramHandler:logging.handlers.DatagramHandler;远程输出日志到UDP sockets
SMTPHandler:logging.handlers.SMTPHandler;远程输出日志到邮件地址
SysLogHandler:logging.handlers.SysLogHandler;日志输出到syslog
NTEventLogHandler:logging.handlers.NTEventLogHandler;远程输出日志到Windows NT/2000/XP的事件日志
MemoryHandler:logging.handlers.MemoryHandler;日志输出到内存中的指定buffer
HTTPHandler:logging.handlers.HTTPHandler;通过"GET"或者"POST"远程输出到HTTP服务器
作为初学者,我们能理解StreamHandler、FileHandler、RotatingHandler这三个处理器(handler)(就可以快速上道了。
StreamHandler:其实是把输入到主入口的内容,经过某种组织方式,将日志输出到特定的位置,默认是输出到标准输出sys.stderr;FileHandler:这个就比较明确了,经过设定的处理,把日志输出到文件中,所以起码是要求我们输入文件名filename;RotatingHandler:这个其实是FileHandler的扩展板,能够设定日志回滚方式,支持日志文件最大数量和日志文件回滚,接下来举例说明。接下来通过代码理解
import logging
from logging.handlers import RotatingFileHandler # 导入上面介绍的“日志回滚方式”处理器,我们那这个作为例子# 通过__name__就可以看出当前文件是不是程序的入口文件,如果__name__!=__main__,就说明当前文件是被其他文件的代码所调用的模块,
# 此时__name__就是该模块的模块名
# 通过logging.getLogger()就是在实例化一个logging类,传进去的name参数就是实例名,可以通过 %(name)s 的方式在Formatter里面
# 设定输出格式
logger = logging.getLogger('__name__') # 设定级别,由低到高分别有logging.DEBUG、logging.INFO、logging.WARNING、logging.ERROR、logging.CRITICAL
# 本质上是一种过滤方式,设定的level决定了哪些内容可以被记录,哪些不能被记录。
# 其实setlevel是这个方法不仅主对象logger拥有,后面的处理器handler也有自己的setlevel方法,都是一样的方法,每一个handler
# 都可以利用setlevel设定自己的日志记录level
logger.setLevel(level = logging.INFO)# 定义一个RotatingFileHandler,最多备份3个日志文件,每个日志文件最大10K。默认的mode = 'a',就是append模式记录数据,
# 这种方式不会覆盖掉之前的内容。
# 注意,此时实例化的是handler,并没有挂靠到前面实例化的logger上,后面通过addHandler才可以添加到主对象上
rHandler = RotatingFileHandler("log.txt",maxBytes = 10*1024,backupCount = 3)
rHandler.setLevel(logging.INFO)
# 设定日志记录格式,关于格式的各种说明后文会列出
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# 把格式传递到rHandler实例处理器的setFormatter方法中
rHandler.setFormatter(formatter)
# 以上最近的4步设定几乎是模板:实例化一个handler——设定日志级别——格式规定——格式设定# 同一个主对象,可以添加多个handler,相当于并行的几条生产线,他们的输入内容一致,都是来源于主对象入口。后面的工作就是分支处理
# 每个handler生产自己制定格式的日志数据。
# 下面的logging.StreamHandler()是本文添加的第二个handler,没有指定stream,默认就是输出到控制台(准确说是sys.stderr)
console = logging.StreamHandler()
console.setLevel(logging.INFO)
console.setFormatter(formatter)# 当特定handler设置完毕后,就要把该生产线(handler)并入添加到主对象logger上,利用的是主对象的addHandler方法
logger.addHandler(rHandler)
logger.addHandler(console)# 接下来就是从主对象的入口输入内容,这些内容会经过主对象的并行的生产线handler,输出每条生产线所对应格式的日志内容到该条生产线的
# 指定输出地。
# logger.info、logger.warning都是在告诉记录器logger该条信息的级别,不然他自己是无法分辨的。
logger.info("Start print log")
logger.debug("Do something")
logger.warning("Something maybe fail.")
logger.info("Finish")
控制台的输出内容如下:
 目录里多了一
目录里多了一log.txt文件:
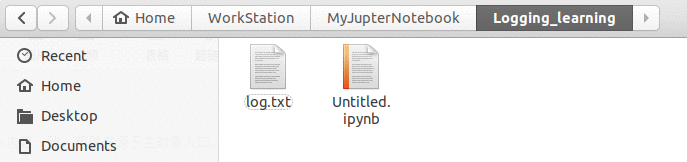
如果你在jupyter notebook里再次运行这一段代码,你会发现,每一条日志内容会输出两次,再运行则每一条日志内容会输出三次,为什么?
 原来,问题就在
原来,问题就在logging.getLogger()这个类上,如果能从当前的全局变量(变量本质上就是对象)中找到相同name的logger,则引用已经存在的logger即可,如果找不到才会创建,这一点从它的docstring中也可以证实:
Signature: logging.getLogger(name=None)
Docstring:
Return a logger with the specified name, creating it if necessary.
看见了吧,creating it if necessary
当获取到相同name的logger时,由于又重复添加了handler,所以生产线又多了几条,相应地输出的日志信息就会增多。
当然你也可以在上面代码的末尾添加如下内容,即可规避这种问题:
logger.removeHandler(rHandler)# 执行完相关程序在结尾移除特定的handler
logger.removeHandler(console)
入门推荐篇
深入了解篇:
关于多模块的使用,请参看入门推荐篇 2.5 多模块使用。
请务必先阅读2.5节的代码。
首先在主模块定义了logger,name=
'mainModule',并对它进行了配置,就可以在解释器进程里面的其他地方通过getLogger(‘mainModule’)得到的对象都是一样的,不需要重新配置,可以直接使用[1]。定义的该logger的子logger,都可以共享父logger的定义和配置,所谓的父子logger是通过命名来识别,任意以'mainModule'开头的logger都是它的子logger,例如’mainModule.sub’。
Python中的traceback模块被用于跟踪异常返回信息,可以在logging中记录下traceback
import logging
import sys
logger = logging.getLogger('traceback-capturing')
logger.setLevel(level = logging.INFO)
handler = logging.FileHandler("log.txt",mode='w')
handler.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler.setFormatter(formatter)console = logging.StreamHandler(stream=sys.stdout) # 这里我们指定说出到”sys.stdout“标准输出中,默认是输出到”sys.stderr“,#所以下面的内容的背景是白色的,否则是粉红色的背景
console.setLevel(logging.INFO)logger.addHandler(handler)
logger.addHandler(console)logger.info("Start print log")
logger.debug("Do something")
logger.warning("Something maybe fail.")
try:open("sklearn.txt","rb")
except (SystemExit,KeyboardInterrupt):raise
except Exception:# To pass exception information, use the keyword argument exc_info with a true value, e.g.# logger.error("Houston, we have a %s", "major problem", exc_info=1)logger.error("Faild to open sklearn.txt from logger.error,that is %s"," major problem",exc_info = True)# 也可以用 logger.exceptionlogger.info("Finish")
logger.removeHandler(handler)
logger.removeHandler(console)
结果如下:

首先看看json文件的配置,可以发现,主要有以下几个部分:
formatters:用来定义输出的格式。里面的“simple”就是其中的一种格式,你还可以据此定义更多的格式,和"simple"并行放在一起。"handlers":"handlers"的value就是众多处理器handler的集合地,该案例的文件定义了"console"、"info_file_handler"、"error_file_handler"这几个处理器实例,每一个实例字典里的键值对就是在配置相应的handler。其中"class"代表你选择的handler类型(通常是StreamHandler、FileHandler、RotatingHandler)"loggers":这里面可以定义很多记录器logger,本案例我们仅添加了一个name="my_module"的记录器logger,而每个记录器下面又可以添加多个handler,存放在handlers对应的value里面。propagate是什么?起什么作用?下一节会说。"root":定义的是根记录器logger,name=“root”,其他的类似。{"version":1,"disable_existing_loggers":false,"formatters":{"simple":{"format":"%(asctime)s - %(name)s - %(levelname)s - %(message)s"}},"handlers":{"console":{"class":"logging.StreamHandler","level":"DEBUG","formatter":"simple","stream":"ext://sys.stdout"},"info_file_handler":{"class":"logging.handlers.RotatingFileHandler","level":"INFO","formatter":"simple","filename":"info.log","maxBytes":10485760,"backupCount":20,"encoding":"utf8"},"error_file_handler":{"class":"logging.handlers.RotatingFileHandler","level":"ERROR","formatter":"simple","filename":"errors.log","maxBytes":10485760,"backupCount":20,"encoding":"utf8"}},"loggers":{"my_module":{"level":"ERROR","handlers":["info_file_handler"],"propagate":"no"}},"root":{"level":"INFO","handlers":["console","info_file_handler","error_file_handler"]}
}
当配置文件写好后,就可以加载配置文件了:
import json
import logging.config
import osdef setup_logging(default_path = "logging.json",default_level = logging.INFO,env_key = "LOG_CFG"):path = default_pathvalue = os.getenv(env_key,None)if value:path = valueif os.path.exists(path):with open(path,"r") as f: # 打开配置文件config = json.load(f) # 利用json模块加载配置文件到内存,转换成Python的dict对象
# print(config["handlers"]["info_file_handler"])logging.config.dictConfig(config) # 配置else:logging.basicConfig(level = default_level)def func():logging.info("start func") # 通过logging.info/warning操作,默认用的是name"root"的logger记录器logging.info("exec func")logging.info("end func")logger.info("start func")logger.info("exec func")logger.info("end func")if __name__ == "__main__":setup_logging(default_path = "logging.json")logger = logging.getLogger('my_module') # 实例化一个已经配置好的name="my_module"的loggerfunc()
关于这个问题,在我推荐的第二篇文章里其实有涉及,官方文档中提供的流程图足以说明logger的运行机制。
 从官方文档中提供的流程图可以看出,
从官方文档中提供的流程图可以看出,propagate会把当前的logger设置为其parent的logger, 并将LogRecord传入parent的Handler, 这就会导致一个有趣的现象:
# 给root logger 添加一个Handler
In [42]: import sysIn [43]: logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)In [44]: logging.root.handlers
Out[44]: [<StreamHandler <stdout> (NOTSET)>]# 新建一个child loggerIn [5]: child &#61; logging.getLogger(&#39;child&#39;)In [6]: child.parent
Out[6]: <RootLogger root (DEBUG)>In [7]: child.handlers
Out[7]: []# log 信息
In [8]: child.debug(&#39;this is a debug message&#39;)
DEBUG:child:this is a debug message
我们的child logger 是没有Handler的, 但是我们的LogRecord还是被发送到了终端, 这就是propagate的作用, 它把子代的所有LogRecord都发送给了父代, 循环往复, 最终到达root, 如果我们在子代中设置了hander, 那么一个LogRecord就会被发送两次:
In [9]: child.addHandler(logging.StreamHandler())In [10]: child.debug(&#39;this message will be handled twice&#39;)
this message will be handled twice
DEBUG:child:this message will be handled twice
第一次是子代发送到stderr(默认), 第二次是使用root的Handler.
讲到这里&#xff0c;通观本篇全文&#xff0c;你就可以发现&#xff0c;除了name&#61;“root”&#xff0c;其他所有的logger都是parent logger&#xff0c;归根结底其他logger都是root的child。这里我们可以通过logger.propagate来查看每一个记录器的propagate属性(bool值)。
下面引用的这句话是第二篇文章作者的观点&#xff0c;我认为他说的是对的&#xff0c;但是好像和大家的使用习惯不太一样&#xff0c;通常我们习惯实例化一个logger&#xff0c;并且对实例logger进行配置&#xff0c;虽然我们可以配置logging.root来实现这位作者的观点&#xff0c;但通常我们并不这么做。
我们没必要配置子代的
Handler, 因为最终所有的LogRecord都会被转发到root, 我们只需要配置它就可以了.
再次强调&#xff0c;第二篇文章非常有深入了解logging的价值&#xff0c;希望看到本篇博文的读者最好去研读下。







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 