大数据,顾名思义就是大量的数据,一般这些数据都是PB级以上。PB是数据存储容量的单位,它等于2的50次方个字节,或者在数值上大约等于1000个TB。这些数据的特点是种类繁多,有视频、有语音、有图片、有文字等等。面对这么多数据,使用常规技术就没法处理了,于是产生了大数据技术。
大数据分成了很多派系,其中最著名的是Apache Hadoop,Clouera CDH和 Hortonworks 派系。
Hadoop是一套开源的用于大规模数据集的分布式存储和处理的工具平台。它最早由Yahoo的技术团队根据Google所发布的公开论文思想用JAVA语言开发,现在则隶属于apache基金会。
Hadoop以分布式文件系统HDFS(Hadoop distributed file system)和Map Reduce分布式计算框架为核心,为用户提供了底层细节透明的分布式基础设施。
HDFS的高容错性、高伸缩性等优点,允许用户将Hadoop部署在廉价的硬件上,构建分布式文件存储系统。
MapReduce分布式计算框架则允许用户在不了解分布式系统底层细节的情况下开发并行、分布式的应用程序,充分利用大规模的计算资源,解决传统高性能单机无法解决的大数据处理问题。
Hadoop已经成长为一个庞大的体系,只要和海量数据相关的领域都能看到Hadoop的身影,以下是Hadoop生态系统中出现的各种数据工具。
(1)数据抓取系统:Nutch
(2)海量数据怎么存,当然是用分布式文件系统:HDFS
(3)数据怎么用呢,分析,处理
(4)MapReduce框架,让你编写代码来实现对大数据的分析工作
(5)非结构化数据(日志)收集处理:fuse/webdav/chukwa/flume/Scribe
(6)数据导入到HDFS中,至此RDBSM也可以加入HDFS:Hiho、sqoop
(7)MapReduce太麻烦,让你用熟悉的方式来操作Hadoop里的数据:Pig,Hive,Jaql
(8)让你的数据可见:drilldown,Intellicus
(9)用高级语言管理你的任务流:oozie,Cascading
(10)Hadoop当然也有自己的监控管理工具:Hue、karmasphere、eclipse plugin、cacti、ganglia
(11)数据序列化处理与任务调度:Avro、Zookeeper
(12)更多构建在Hadoop上层的服务:Mahout、Elastic map Reduce
(13)OLTP联机事务处理系统:Hbase
Apache Hadoop整体生态图如下。

总之,Hadoop是目前分析海量数据的首选工具,并已经被各行各业广泛应用于以下场景:
(1)大数据量存储:分布式存储(各种云盘,百度,360~还有云平台均有Hadoop应用)
(2)日志处理: Hadoop擅长这个
(3)海量计算: 并行计算
(4)ETL:数据抽取到oracle、mysql、DB2、mongdb及主流数据库
(5)使用HBase做数据分析:用扩展性应对大量读写操作—Facebook构建了基于HBase的实时数据分析系统
(6)机器学习:比如Apache Mahout项目(Apache Mahout简介 常见领域:协作筛选、集群、归类)
(7)搜索引擎:Hadoop + lucene实现
(8)数据挖掘:目前比较流行的广告推荐
(9)用户行为特征建模
(10)个性化广告推荐
Hadoop是开源的分布式存储和分布式计算平台。其中Hdfs是分布式文件存储系统,是用来存储文件的。在存储系统中涉及到的角色有下面三种。
1、NameNode:管理元数据信息,给子节点分配任务(FSImage是主节点启动时对整个文件系统的快照(元数据镜像文件),Edits是修改记录(操作日志文件))
2、DataNode:负责数据存储,实时上报心跳给主节点
3、SecondaryNameNode:
1)首先,它定时到NameNode去获取edit logs,并更新到fsimage上。一旦它有了新的fsimage文件,它将其拷贝回 NameNode中。
2) NameNode在下次重启时会使用这个新的fsimage文件,从而减少重启的时间。
这三个角色决定了hadoop的分布式文件系统hdfs的运行架构如下图所示。

分布式计算mapreduce的框架yarnYarn是一个资源管理系统,其中的角色如下。
1、ResourceManager 监控 NodeManager,负责集群的资源调度
2、nodemanager 管理节点资源,处理ResourceManager 命令
Hadoop是运行在Linux,虽然借助工具也可以运行在Windows上,但是建议还是运行在Linux系统上,这里首先介绍Linux环境的安装、配置、Java JDK安装等。
这里使用Vmware虚拟机安装Linux。首先需要把Vmware虚拟机与主机设置NAT模式配置。NAT是网络地址转换,是在宿主机和虚拟机之间增加一个地址转换服务,负责外部和虚拟机之间的通讯转接和IP转换。
(1)Vmware安装后,默认的NAT设置如下:

(2) 默认的设置是启动DHCP服务的,NAT会自动给虚拟机分配IP,需要将各个机器的IP固定下来,所以要取消这个默认设置。
(3) 为机器设置一个子网网段,默认是192.168.136网段,这里设置为100网段,将来各个虚拟机Ip就为 192.168.100.*。
(4)NAT设置按钮,打开对话框,可以修改网关地址和DNS地址。这里为NAT指定DNS地址。

(5)网关地址为当前网段里的.2地址,这里是固定的,不做修改,先记住网关地址就好了,后面会用到。
(1)文件菜单选择新建虚拟机
(2)选择经典类型安装,下一步。
(3)选择稍后安装操作系统,下一步。
(4)选择Linux系统,版本选择CentOS 64位。

(5)命名虚拟机,给虚拟机起个名字,将来显示在Vmware左侧。并选择Linux系统保存在宿主机的哪个目录下,应该一个虚拟机保存在一个目录下,不能多个虚拟机使用一个目录。

(6)指定磁盘容量,是指定分给Linux虚拟机多大的硬盘,默认20G就可以,下一步。
(7)点击自定义硬件,可以查看、修改虚拟机的硬件配置,这里我们不做修改。
(8)点击完成后,就创建了一个虚拟机,但是此时的虚拟机还是一个空壳,没有操作系统,接下来安装操作系统。
(9)点击编辑虚拟机设置,找到DVD,指定操作系统ISO文件所在位置。

(10)点击开启此虚拟机,选择第一个回车开始安装操作系统。

(11)设置root密码。

(12)选择Desktop,这样就会装一个Xwindow。

(13)先不添加普通用户,其他用默认的,就把Linux安装完毕了。
因为Vmware的NAT设置中关闭了DHCP自动分配IP功能,所以Linux还没有IP,需要我们设置网络各个参数。
(1)用root进入Xwindow,右击右上角的网络连接图标,选择修改连接。

(2)网络连接里列出了当前Linux里所有的网卡,这里只有一个网卡System eth0,点击编辑。

(3)配置IP、子网掩码、网关(和NAT设置的一样)、DNS等参数,因为NAT里设置网段为100.*,所以这台机器可以设置为192.168.100.10网关和NAT一致,为192.168.100.2。

(4)用ping来检查是否可以连接外网,如下图,已经连接成功。

临时修改hostname需要要linux下使用如下指令。
[root@localhost Desktop]# hostname mylinux-virtual-machine
永久修改hostname,需要修改配置文件/etc/sysconfig/network。
[root@mylinux-virtual-machine ~] vi /etc/sysconfig/network
打开文件后,进行如下设置:
NETWORKING=yes #使用网络
HOSTNAME=mylinux-virtual-machine #设置主机名
学习环境可以直接把防火墙关闭掉。
用root用户登录后,执行查看防火墙状态。
[root@mylinux-virtual-machine]#service iptables status
有的版本默认的防火墙是firewall或ufw。
关闭防火墙可以使用临时关闭。命令如下。
[root@mylinux-virtual-machine]# service iptables stop
还可以永久性关闭防火墙,命令如下。
[root@mylinux-virtual-machine]# chkconfig iptables off
关闭防火墙,这种设置需要重启才能生效。
selinux是Linux一个子安全机制,学习环境可以将它禁用。
禁用selinux可以对/etc/sysconfig/selinux文件进行编辑,打开配置文件/etc/sysconfig/selinu的命令如下。
[hadoop@mylinux-virtual-machine]$ vim /etc/sysconfig/selinux
在/etc/sysconfig/selinux文件中将selinux设置为disabled,具体内容如下。
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of these two values:
# targeted - Targeted processes are protected,
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
因为Hadoop底层是用Java实现的,这就需要查看环境中是否已经安装Java。
查看是否已经安装了java JDK,可以在linux下执行命令。
[root@mylinux-virtual-machine /]# java –version
注意:Hadoop机器上的JDK,最好是Oracle的Java JDK,不然会有一些问题,比如可能没有JPS命令。
如果安装了其他版本的JDK,卸载掉。
去下载Oracle版本Java JDK,最好8.0以上,可以访问Oracle官方网站。如下图所示。

在上图中可以下载gz格式的压缩包,在linux下进行解压。例如解压到/usr/java目录下,usr目录是linux系统本身就有的,java目录可以自行在usr目录下创建,linux下创建usr目录的命令如下。
[root@mylinux-virtual-machine /]# tar -zxvf jdk-8u281-linux-x64.tar.gz -C /usr/java
接下来,添加环境变量。
设置JDK的环境变量 JAVA_HOME。需要修改配置文件/etc/profile,在linux中的修改命令如下。
[root@mylinux-virtual-machine hadoop]#vi /etc/profile
进入文件后,在文件末尾追加如下内容
export JAVA_HOME="/usr/java/jdk1.8.0_281"
export PATH=$JAVA_HOME/bin:$PATH
修改完毕后,执行 source /etc/profile
安装后再次执行 java –version,可以看见已经安装完成。
[root@mylinux-virtual-machine /]# java -version
java version "1.7.0_67"
Java(TM) SE Runtime Environment (build 1.7.0_67-b01)
Java HotSpot(TM) 64-Bit Server VM (build 24.65-b04, mixed mode)
Hadoop部署模式有:本地模式、伪分布模式、完全分布式模式、HA完全分布式模式。
区分的依据是NameNode、DataNode、ResourceManager、NodeManager等模块运行在几个JVM进程、几个机器。

本地模式是最简单的模式,所有模块都运行与一个JVM进程中,使用的本地文件系统,而不是HDFS,本地模式主要是用于本地开发过程中的运行调试用。下载hadoop安装包后不用任何设置,默认的就是本地模式。
hadoop安装包可以从官方网站下载。如下图所示。

从官方网站中点击“Download”下载按钮。根据需求选取适当的版本下载,下载后在linux环境下进行压缩包的解压。linux命令如下。
[hadoop@mylinux-virtual-machine hadoop]# tar -zxvf hadoop-2.7.0.tar.gz -C /usr/hadoop
解压后,配置Hadoop环境变量,linux下的修改/etc/profile命令如下。
[hadoop@mylinux-virtual-machine hadoop]# vi /etc/profile
对profile文件追加配置信息如下。
export HADOOP_HOME="/opt/modules/hadoop-2.5.0"
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
执行:source /etc/profile 使得配置生效
接下来,进入解压的目录下的etc/hadoop目录中,对5个文件进行设置。
第一步设置hadoop-env.sh文件,修改配置信息中JAVA_HOME参数如下。
export JAVA_HOME="/usr/java/jdk1.8.0_281"
第二步修改配置core-site.xml的文件。修改内容如下。
fs.defaultFS参数配置的是HDFS的地址。hadoop.tmp.dir配置的是Hadoop临时目录。
第二步修改配置hdfs-site.xml的文件。修改内容如下。
dfs.replication配置的是HDFS存储时的备份数量,因为这里是伪分布式环境只有一个节点,所以这里设置为1。
第四步配置配置mapred-site.xml
默认没有mapred-site.xml文件,但是有个mapred-site.xml.template配置模板文件。复制模板生成mapred-site.xml。复制命令如下。
[hadoop@mylinux-virtual-machine hadoop]#cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
在mapred-site.xml中添加配置如下。
该项配置用于指定mapreduce运行在yarn框架上。
第五步配置配置yarn-site.xml
在yarn-site.xml中添加配置信息如下。
yarn.nodemanager.aux-services配置了yarn的默认混洗方式,选择为mapreduce的默认混洗算法。
yarn.resourcemanager.hostname指定了Resourcemanager运行在哪个节点上。
这五步中的配置文件信息配置成功后,进行格式化HDFS。在linux系统中格式化HDFS的指令如下。
hdfs namenode -format
执行命令后,在服务启动中会询问三次输入密码的操作。执行结束后使jps显示进程信息如下图所示。

在这段信息中如果你找到了“has Successful”的信息,就证明hadoop的格式化已经成功了。
格式化是对HDFS这个分布式文件系统中的DataNode进行分块,统计所有分块后的初始元数据的存储在NameNode中。
格式化后,查看core-site.xml里hadoop.tmp.dir(本例是/opt/data目录)指定的目录下是否有了dfs目录,如果有,说明格式化成功。
启动hadoop平台,可以先启动hdfs。命令的执行路径在解压的hadoop路径中/sbin目录下,具体启动方法在linux执行如下。
[hadoop@mylinux-virtual-machine sbin]#./start-dfs.sh
执行结果如图所示。

启动hdfs后,可以使用jsp查看进程,如图所示。

由图可知,已经在进程中启动了NameNode、SecondNameNode和DataNode等三个角色。
下面,继续进行yarn框架的启动,启动目录仍然是解压的hadoop路径中/sbin目录下,具体启动方法在linux执行如下。
[hadoop@mylinux-virtual-machine sbin]#./start-yarn.sh
执行结果如图所示。

yarn服务启动后,继续用jps查看进程信息,如下图所示。
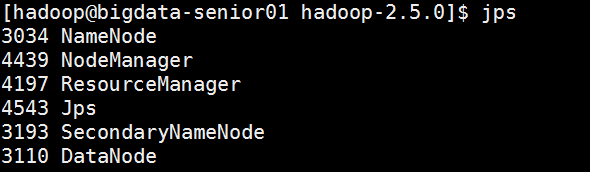
至此,Hadoop环境已搭建完成。
它是当今企业中最有效的数据处理框架。使用Spark的成本很高,因为它需要大量的内存进行计算,但它仍然是数据科学家和大数据工程师的最爱。
下载spark压缩包需要访问Spark官方网站。

进入网站后,选择“Download”选项,对其中规定的版本进行下载。
下载后,在linux平台上进行解压,解压到usr目录下的spark自定义目录下,linux命令如下。
[hadoop@mylinux-virtual-machine hadoop]# tar -zxvf spark-3.1.1-bin-hadoop2.7.tgz -C /usr/spark
接下来,打开Spark的配置目录,复制默认的Spark环境模板。它已经以spark-env.sh.template的形式出现了。使用cp命令复制一份,产生的副本中把“.template”去掉,linux命令如下。
[hadoop@mylinux-virtual-machine sbin]#cd /usr/lib/spark/conf/
[hadoop@mylinux-virtual-machine conf]#cp spark-env.sh.template spark-env.sh
[hadoop@mylinux-virtual-machine conf]# vi spark-env.sh
在文件中添加信息
export JAVA_HOME=/usr/java/jdk1.8.0_281
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.0
export PYSPARK_PYTHON=/usr/bin/python3
在配置信息中,JAVAHOME和HADOOPHOME是java和hadoop的路径变量,PYSPARK_PYTHON是python与pyspark进行联系的变量信息,/usr/bin/python是python3在linux中的路径,可以通过这样的路径操作查找是否能够找到python3。
了解了大数据的平台,就要在大数据的平台上进行数据分析,大数据平台的数据分析过程如下图所示。

在如图所示的分析过程中最重要的程WordCount程序。WordCount程序完全来自于MapReduce的分布式计算的思路。下面先说明一下MapReduce的计算思路。
先看如下的图形。

从流程中看出,MapReduce有两个阶段,在Map阶段会把输入的大数据文件切片首先处理成key-value值对的形式,然后对每一个值对调用Map任务,通过Map任务处理成新的key-value值对,大多数数据分析的分析思路都是把数据进行分组排序汇总统计。MapReduce的Redudce阶段也是分组排序汇总统计。最终做为值对的数据集输出。
对于WordCount程序来说,也就是统计分布式文件系统中的单词数量,其输入的内容和输出格式如下图所示。
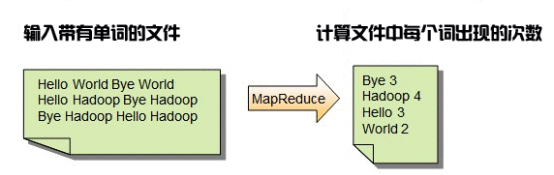
由图中可知,输入文件中是由英文单词组成的每句话,最终通过MapReduce过程处理后,输出每个单词在文件中出现的次数。
使用MapReduce过程对这样的wordCount程序进行处理的思路如下图所示。

由图可知,输入是每一行含有英文单词的句子,经过Map过程后变成英文单词和计数式的值对key-value,这个key-value格式只是在对数字进行计数,“
下面落实到代码上。
使用PySpark必须对SparkSession的Spark对话进行实例化。具体实例化的格式如下。
SparkSession.builder.master(“local”).appName(“wordCount”).getOrCreate()
builder指的是SparkSession是通过静态类Builder来完成实例化的。调用了builder之后,就可以调用Builder静态类中的很多方法。
master函数设置Spark master URL 连接,比如"local" 设置本地运行,"local[4]"本地运行4cores,或则"spark://master:7077"运行在spark standalone 集群。
appName(String name)函数用来设置应用程序名字,会显示在Spark web UI中。
getOrCreate()获取已经得到的 SparkSession,或则如果不存在则创建一个新的基于builder选项的SparkSession。
建立了SparkSession对话之后,SparkContext是对编写Spark程序用到的第一个类。SparkContext为Spark程序的主要入口点,因此SparkSession建立对话后,获取对话变量sparkContext程序。具体代码如下:
from pyspark.sql import SparkSession
spark=SparkSession.builder.master(“local”).appName(“wordCount”).getOrCreate()
sc=spark.sparkContext
有了Spark程序的入口sparkContext,完成数据分析的工作,首先要读取需要分析的文件,textFile来加载一个文件创建RDD,RDD是是Spark中最基本的数据抽象,RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,它代表一个不可变、可分区、里面的元素可并行计算的集合。Spark内有collect方法,这个方法可以将RDD类型的数据转化为数组来显示出来。如果要显示读取的RDD数据,就可以使用textFile读出hdfs中的数据,然后通过collect方法显示,textFile默认是从hdfs读取文件,也可以指定sc.textFile("路径").在路径前面加上hdfs://表示从hdfs文件系统上读取数据。具体代码如下。
from pyspark.sql import SparkSession
spark=SparkSession.builder.master(“local”).appName(“wordCount”).getOrCreate()
sc=spark.sparkContext
files=sc.textFile(“hdfs://mylinux-virtual-machine:9000/words.txt”)
print(files.collect())
代码中通过textFile读取hdfs服务器上的words.txt文件,读取后是RDD类型的数据,通过files.collect()方法转换成数组,通过print方法打印出来。运行结果如下。

通过图中结果可以看出,文件中的数据已经被读取出来并形成了列表。遍历读取出来的RDD就可以对RDD中的每个数据进行操作。
在spark中有两个很重要的函数:map函数和flatMap函数是两个比较常用的函数。其中
map:对集合中每个元素进行操作。
flatMap:对集合中每个元素进行操作然后再扁平化。
如果将前面读取的RDD通过map操作再使用collect()方法显示具体内容,代码如下。
from pyspark.sql import SparkSession
spark=SparkSession.builder.master(“local”).appName(“wordCount”).getOrCreate()
sc=spark.sparkContext
files=sc.textFile(“hdfs://mylinux-virtual-machine:9000/words.txt”)
map_files=files.map(lambda x:x.split(“ “))
print(map_files)
运行结果如下:

如果将前面读取的RDD通过flatMap操作再使用collect()方法显示具体内容,代码如下。
from pyspark.sql import SparkSession
spark=SparkSession.builder.master(“local”).appName(“wordCount”).getOrCreate()
sc=spark.sparkContext
files=sc.textFile(“hdfs://mylinux-virtual-machine:9000/words.txt”)
flatmap_files=files.flatMap(lambda x:x.split(“ “))
print(flatmap_files)
运行结果如下:

根据map和flatMap两种不同的对每个元素操作的返回结果集可以看出,针对wordCount的问题,flatMap 的返回结果更加符合预期。再对flatMap返回的结果集进行处理,以计数式的key-value键值对,形成(hello,1)、(java,1)、(android,1)等形式,代码如下。
from pyspark.sql import SparkSession
spark=SparkSession.builder.master(“local”).appName(“wordCount”).getOrCreate()
sc=spark.sparkContext
files=sc.textFile(“hdfs://mylinux-virtual-machine:9000/words.txt”)
flatmap_files=files.flatMap(lambda x:x.split(“ “))
map_files=flatmap_files.map(lambda x:(x,1))
print(map_files.collect())
运行结果如下。

构造出如上图所示的key-value数据后,利用spark中的reduceByKey方法,reduceByKey就是对元素为KV对的RDD中Key相同的元素的Value进行function的reduce操作,因此,Key相同的多个元素的值被reduce为一个值,然后与原RDD中的Key组成一个新的KV对。这里实现的是相同的key对应的值求和的累加,可以使用lambda函数来完成,代码如下。
from pyspark.sql import SparkSession
spark=SparkSession.builder.master(“local”).appName(“wordCount”).getOrCreate()
sc=spark.sparkContext
files=sc.textFile(“hdfs://mylinux-virtual-machine:9000/words.txt”)
flatmap_files=files.flatMap(lambda x:x.split(“ “))
map_files=flatmap_files.map(lambda x:(x,1))
freduce_map=map_files.reduceByKey(lambda x,y:x+y)
print(reduce_map.collct())
程序最终的输出结果如图所示。

视频讲解地址:
1、pyspark分析大数据1-hadoop环境搭建:https://www.bilibili.com/video/BV1Z54y1L7cT/
2、pyspark分析大数据2-mapreduce过程:https://www.bilibili.com/video/BV15V411J75a/
3、pyspark分析大数据3-pyspark分析wordcount程序及延伸:https://www.bilibili.com/video/BV1y64y1m7XN/









 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 