本文只针对数字或字母验证码识别
准备工具
- tesseract-ocr-w64-setup-v4.1.0.20190314.exe
- pip install pytesseract
- pip install pillow
- 中文包
tesseract-ocr和中文包的下载连接: 链接:链接:https://pan.baidu.com/s/1r_LZKRXBT2Ffp7QrYQwOSA?pwd=junm
提取码:junm
安装好tesseract,记住安装的所在位置
如D:\Program Files\Tesseract-OCR
解压中文包的压缩包
解压中文包的压缩包,将压缩包里面格式为.traineddata的文件复制在安装目录里边tessdata的文件夹下,如D:\Program Files\Tesseract-OCR\tessdata这下面就行了。
配置tesseract的环境变量
第一个:
TESSDATA_PREFIX —> 你安装的路径,比如 D:\Program Files\Tesseract-OCR
第二个: 在path里面新建一个
你安装的路径,比如 D:\Program Files\Tesseract-OCR


查看版本
win+R输入cmd打开命令行工具,输入tesseract -v

查看一安装好的语言包
win+R输入cmd打开命令行工具,输入tesseract --list-langs

修改pytesseract.py文件,指定tesseract.exe安装路径
# CHANGE THIS IF TESSERACT IS NOT IN YOUR PATH, OR IS NAMED DIFFERENTLY
tesseract_cmd = 'C:\\Program Files (x86)\\Tesseract-OCR\\tesseract.exe‘
#就是你安装的位置

代码实例
import pytesseract
from PIL import Image
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECchromedriver_path = "C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe"
options = webdriver.ChromeOptions()
options.add_argument('--no-sandbox')
options.add_argument('--start-maximized')
options.add_argument('--disable-gpu')
options.add_argument('--hide-scrollbars')
options.add_argument('test-type')
options.add_experimental_option("excludeSwitches", ["ignore-certificate-errors","enable-automation"])
driver = webdriver.Chrome(options=options, executable_path=chromedriver_path)
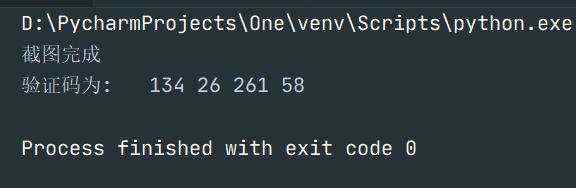
driver.get('http://www.alihba.fun/jiaoyanma/jiaoyanma.php')def screen(screenXpath):img = WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.XPATH, screenXpath)))driver.save_screenshot("allscreen.png") left = img.location['x']+26top = img.location['y']+10right = img.location['x'] + img.size['width']+53bottom = img.location['y'] + img.size['height']+10print(left,top,right,bottom)im = Image.open('allscreen.png')im = im.crop((left, top, right, bottom)) im.save('jietu.png')print("截图完成")def Identify():image = Image.open("./jietu.png")code = pytesseract.image_to_string(image,lang="eng", config="--psm 6") print("识别出验证码为: ",code)def main():screenXpath = '//*[@id="captcha_img"]'screen(screenXpath)sleep(5)Identify()if __name__ == '__main__':main()

-psm 参数
0:定向脚本监测(OSD)
1: 使用OSD自动分页
2 :自动分页,但是不使用OSD或OCR(Optical Character Recognition,光学字符识别)
3 :全自动分页,但是没有使用OSD(默认)
4 :假设可变大小的一个文本列。
5 :假设垂直对齐文本的单个统一块。
6 :假设一个统一的文本块。
7 :将图像视为单个文本行。
8 :将图像视为单个词。
9 :将图像视为圆中的单个词。
10 :将图像视为单个字符。
通过测试,如果验证码全为数字,准确率比较高,字母识别的准确率稍低
最后可以关注一下我个人微信公众号,不定期更新一些好用的资源以及生活上的点点滴滴~~








 京公网安备 11010802041100号
京公网安备 11010802041100号