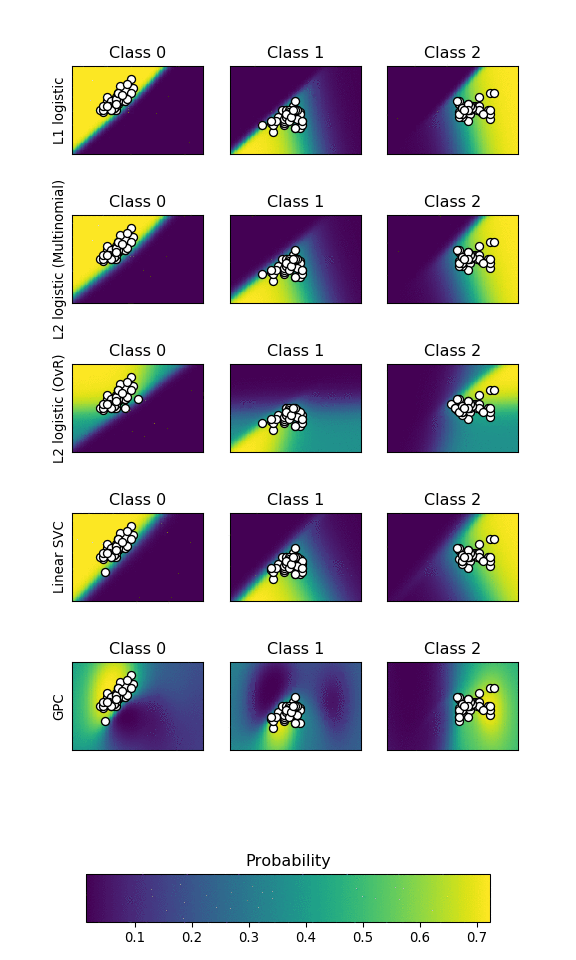
在这里,我们使用一个三类的数据集,分别用支持向量机(SVC)、L1 and L2惩罚的Logistic回归和高斯过程分类。默认情况下,线性SVC并不是一个概率分类器,但是可以通过设置参数probability=True改变。具有One v.s. Rest的Logistic回归并不是一个多类别分类器,因此,在分隔类2,类3时要比其它分类器复杂些。
实例详解
首先,导入必需的库。
print(__doc__)# Author: Alexandre Gramfort # License: BSD 3 clauseimport matplotlib.pyplot as plt import numpy as npfrom sklearn.metrics import accuracy_score from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC from sklearn.gaussian_process import GaussianProcessClassifier from sklearn.gaussian_process.kernels import RBF from sklearn import datasets
本例使用的是鸢尾花数据集iris, 并且只用前2个特征作图。
iris = datasets.load_iris() X = iris.data[:, 0:2] # we only take the first two features for visualization y = iris.targetn_features = X.shape[1]
Explore how Matterverse is redefining the metaverse experience, creating immersive and meaningful virtual environments that foster genuine connections and economic opportunities. ...
[详细]








 京公网安备 11010802041100号
京公网安备 11010802041100号