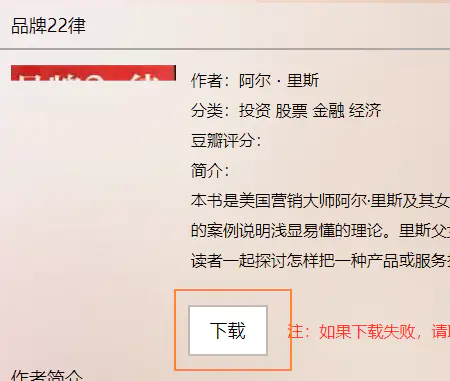
def async_content(tree):title = tree.xpath("//div[@class='hanghang-za-title']")[0].text# 如果页面没有信息,直接返回即可if title == '':returnelse:try:description = tree.xpath("//div[@class='hanghang-shu-content-font']")author = description[0].xpath("p[1]/text()")[0].replace("作者:","") if description[0].xpath("p[1]/text()")[0] is not None else NOnecate= description[0].xpath("p[2]/text()")[0].replace("分类:","") if description[0].xpath("p[2]/text()")[0] is not None else NOnedouban= description[0].xpath("p[3]/text()")[0].replace("豆瓣评分:","") if description[0].xpath("p[3]/text()")[0] is not None else None# 这部分内容不明确,不做记录#des = description[0].xpath("p[5]/text()")[0] if description[0].xpath("p[5]/text()")[0] is not None else NOnedownload= tree.xpath("//a[@class='downloads']")except Exception as e:print(title)returnls = [title,author,cate,douban,download[0].get('href')]return ls












 京公网安备 11010802041100号
京公网安备 11010802041100号