threading 模块建立在thread 模块之上。thread模块以低级、原始的方式来处理和控制线程,而threading 模块通过对thread进行二次封装,
import threading
import time
def sayhi(num): #定义每个线程要运行的函数
print("running on number:%s" %num)
time.sleep(3)
if __name__ == ‘__main__‘:
t1 = threading.Thread(target=sayhi,args=(1,)) #生成一个线程实例
t2 = threading.Thread(target=sayhi,args=(2,)) #生成另一个线程实例
t1.start() #启动线程
t2.start() #启动另一个线程
import threading
import time
class MyThread(threading.Thread):
def __init__(self,num):
super().__init__
self.num = num
def run(self):#定义每个线程要运行的函数
print("running on number:%s" %self.num)
time.sleep(3)
if __name__ == ‘__main__‘:
t1 = MyThread(1)
t2 = MyThread(2)
t1.start()
t2.start()
二、 阻塞线程和守护线程
join():
在子线程完成运行之前,这个子线程的父线程将一直被阻塞。
setDaemon(True):
将线程声明为守护线程,必须在start() 方法调用之前设置, 如果不设置为守护线程程序会被无限挂起。这个方法基本和join是相反的。
当我们 在程序运行中,执行一个主线程,如果主线程又创建一个子线程,主线程和子线程 就分兵两路,分别运行,那么当主线程完成
想退出时,会检验子线程是否完成。如 果子线程未完成,则主线程会等待子线程完成后再退出。但是有时候我们需要的是 只要主线程
完成了,不管子线程是否完成,都要和主线程一起退出,
1 #!/usr/bin/env python
2 # encoding: utf-8
3
4 """
5 @version: python37
6 @author: Geoffrey
7 @file: 多线程复习.py
8 @time: 18-10-27 上午9:48
9 """
10
11 import threading
12 from time import ctime,sleep
13
14
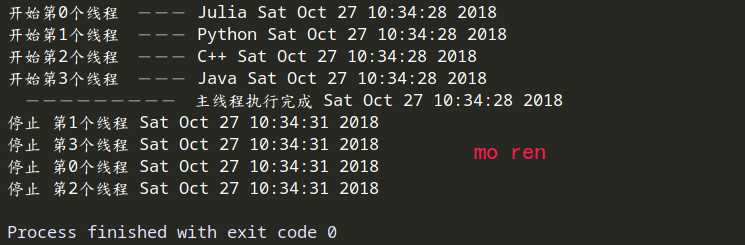
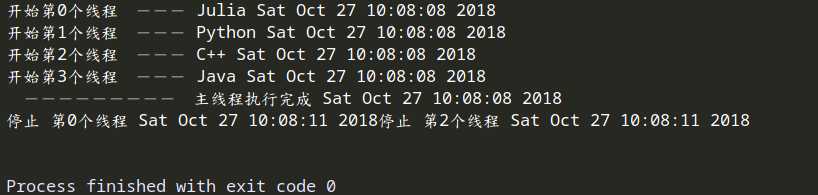
15 def func(name, i):
16 print (f"开始第{i}个线程 --- {name} {ctime()}")
17 sleep(3)
18 print(f"停止 第{i}个线程 {ctime}")
19
20
21 threads = []
22
23 t0 = threading.Thread(target=func,args=(‘Julia‘,0))
24 t1 = threading.Thread(target=func,args=(‘Python‘,1))
25 t2 = threading.Thread(target=func,args=(‘C++‘,2))
26 t3 = threading.Thread(target=func,args=(‘Java‘,3))
27
28 threads.append(t0)
29 threads.append(t1)
30 threads.append(t2)
31 threads.append(t3)
32
33 if __name__ == ‘__main__‘:
34
35 for i,t in enumerate(threads):
36 37 t.setDaemon(bool(i))# 将线程声明为守护线程,必须在start() 方法调用之前设置,如果不设置为守护线程程序会被无限挂起。
38 t.start()
39 # t.join() # 设置为阻塞线程
40
41 print (" --------- 主线程执行完成 %s" %ctime())
1、Cpython的GIL解释器锁的工作机制
在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势。需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。Python同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。像其中的JPython就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。CPython是Python的一种,GIL不是Python语言的缺陷。所以明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL。
1.2 GIL的介绍
GIL本质就是一把互斥锁,既然是互斥锁,所有互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。可以肯定的一点是:保护不同的数据的安全,就应该加不同的锁。要想了解GIL,首先确定一点:每次执行python程序,都会产生一个独立的进程。例如python test1.py,python test2.py,python test3.py会产生3个不同的python进程。
1.3 GIL原理
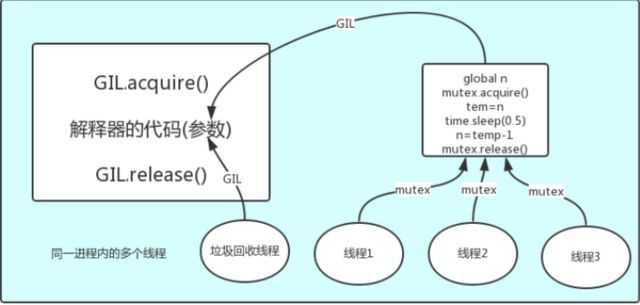
第一点:
所有数据都是共享的,这其中,代码作为一种数据也是被所有线程共享的(test.py的所有代码以及Cpython解释器的所有代码)例如:test.py定义一个函数work(代码内容如下图),在进程内所有线程都能访问到work的代码,于是我们可以开启三个线程然后target都指向该代码,能访问到意味着就是可以执行。
第二点:
所有线程的任务,都需要将任务的代码当做参数传给解释器的代码去执行,即所有的线程要想运行自己的任务,首先需要解决的是能够访问到解释器的代码。
总结:
解释器的代码是所有线程共享的,所以垃圾回收线程也可能访问到解释器的代码而去执行,这就导致了一个问题:对于同一个数据100,可能线程1执行x=100的同时,而垃圾回收执行的是回收100的操作,解决这种问题没有什么高明的方法,就是加锁处理,即GIL,保证python解释器同一时间只能执行一个任务的代码。
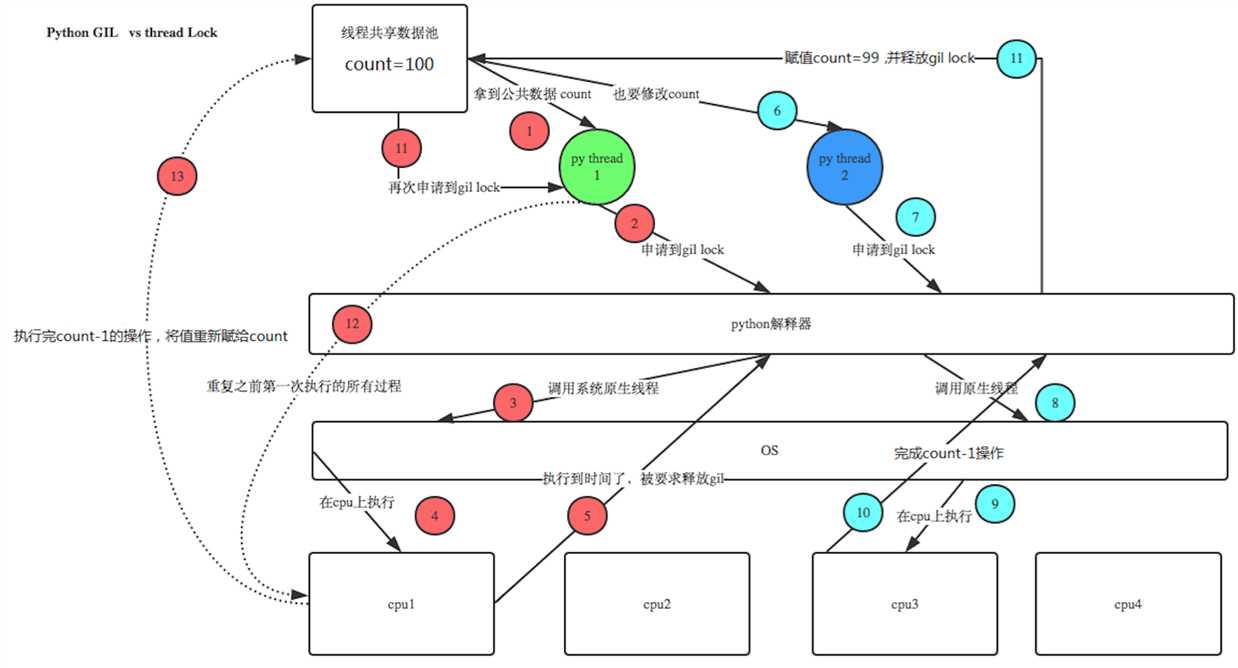
1.4 GIL和Lock
锁的目的是为了保护共享的数据,同一时间只能有一个线程来修改共享的数据。保护不同的数据就应该加不同的锁。所以,解释就是GIL 与Lock是两把锁,保护的数据不一样,前者是解释器级别的(当然保护的就是解释器级别的数据,比如垃圾回收的数据),后者是保护用户自己开发的应用程序的数据,很明显GIL不负责这件事,只能用户自定义加锁处理,即Lock。如下图:







 京公网安备 11010802041100号
京公网安备 11010802041100号