为了应对海量大数据处理的商业场景,品友大数据团队对多款数据库均有深入的分析和研究。今天,我们将从性能、实现、功能几方面对ClickHouse和Palo进行比较,为大家提炼最新最前沿的大数据技术干货。
去年6月,俄罗斯的“百度”,Yandex公司开源了一款高性能的分布式数据库ClickHouse,采用列式存储、多核并行化处理和向量化,它相比MySQL快数百倍,比Hive快200倍以上,比Vertica快5倍,支持实时数据写入,能够支持万亿级别的数据量。ClickHouse覆盖了俄语搜索超过68%的市场,可以说有俄语的地方就有Yandex。
今年8月,中国的“Yandex”,百度公司终于开源了分布式数据分析数据库Palo,该产品已经服务百度内部数十个项目。它基于列式存储、向量化执行、MVCC的实现,并且结合了谷歌mesa以及Impala的优势,号称比大部分数据库有5 到 10 倍的性能提升。
既生瑜,何生亮?ClickHouse与Palo到底谁的性能更好呢?
1. Palo Vs ClickHouse
1.1) 测试场景:
硬件配置
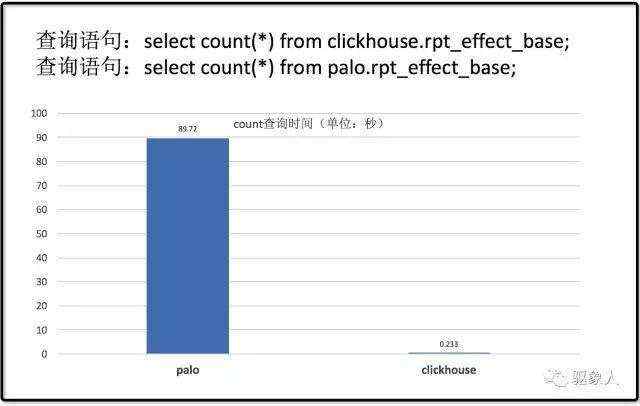
1.2)Count 查询
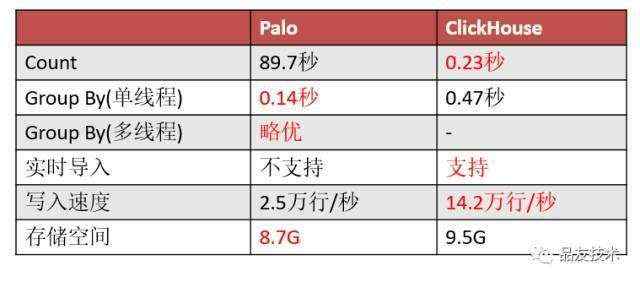
20亿原始数据灌入Plao和ClickHouse,聚合后剩下2亿,ClickHouse和Palo各3个节点,测试发现ClickHouse的count查询性能会远优于Palo,同样的查询ClickHouse只需要0.2秒,Palo查询时间接近90秒。
从以上测试结果可以看出在count查询上Palo的表现落后于ClickHouse,这点可能是Plao的count查询是全表扫描造成的瓶颈。不过在sum查询和并发查询下Palo的优势还是比较突出的。期待后面对count查询的性能优化也会有所突破。毕竟count查询是一个非常常用的语法。
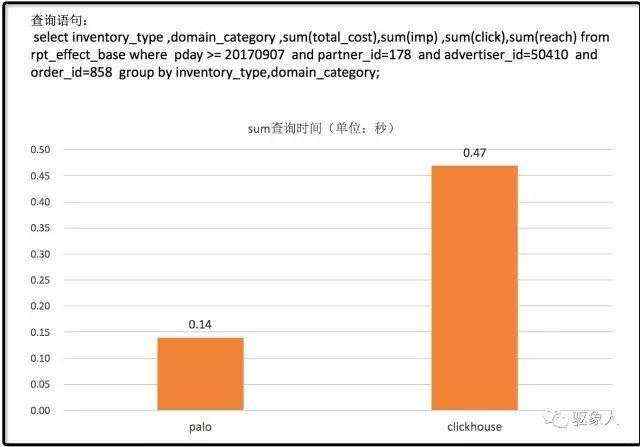
1.3) 聚合查询
聚合查询场景下Plao与ClickHouse的表现如下,单查询情况下,Palo的性能还是不错,比ClickHouse要快。
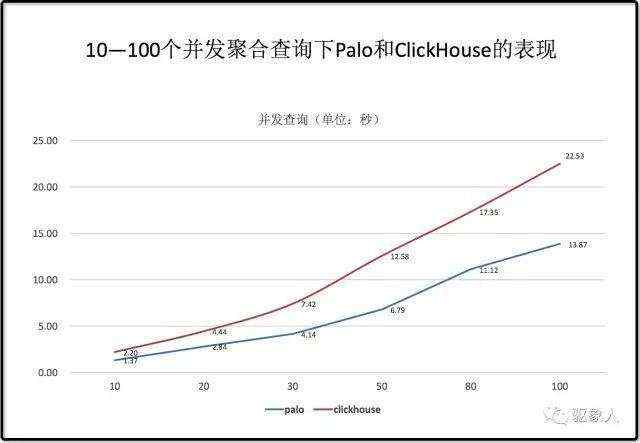
1.4)并发查询
经过多次测试发现并发查询的场景下Palo的性能优势就非常明显。而且在并发场景下Palo可以扩充FE、BE来支持更多的业务查询。
备注:在测试前已经对Palo的相关查询创建Rollup Index,如果创建Rollup后查询依然很慢,可以排查下查询是否开启预聚合,另外针对不同的使用场景使用合理的建表、分区规则会更利于Palo发挥性能优势。
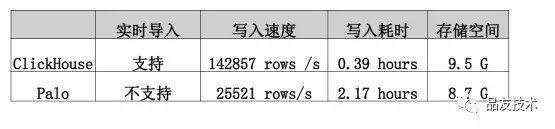
1.5导入数据和文件存储大小比较
写入速度方面ClickHouse表现更出色,比Palo接近快7倍。并且ClickHouse可以支持实时倒入。存储空间上面同样2亿数据ClickHouse占用9.5G,Plao占用8.7G,水平非常接近.
1.6 比较总结
以下表格总结了两者的性能,总体来说,Palo的查询性能比较优秀,虽然在一些实时性和写入能力方面,还不够完善。
2. Palo技术介绍
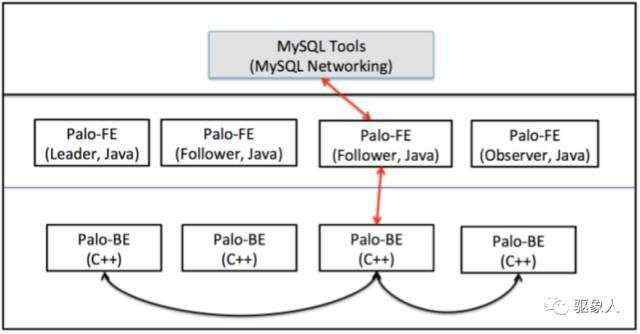
Palo是一个新生物,简单介绍一下Plao的技术实现以及使用经验,方便大家对Palo有个快速的了解。 Palo采用MPP架构来支持高并发交互式查询,与其他Sql-On-Hadoop系统不同的是Plao易用性更强、架构设计简单,自身不依赖于其他系统,不像Kylin、Presto、Impala依赖于Hbase、Mysql和Hive,使用时需要额外维护一两套系统。
Palo由frontend和backend组成(以下简称fe和be)。其中fe负责元数据管理、接收client的查询请求,be负责底层数据存储和查询计划的执行。为了支持高并发、高可用、低延迟。fe和be都可以进行动态扩展部署多个实例。
高并发与一致性之间的选择:通过扩充fe和be节点可以提高查询的并发度和查询效率,Palo默认支持最终一致性(leader保证强一致性,follower、observer保证单调一致性)。如果要求客户端通过任意fe节点查询的数据都是一致的,可以通过保证fe节点之间的强一致性:所有fe节点更新成功才算成功,但是这样可能会降低fe的可用性。这点满足CAP定理(任何分布式系统在可用性、一致性、分区容错性方面,不能兼得,最多只能得其二) 需要用户根据具体使用场景平衡一下。
高并发查询与高吞吐量的保障:
【小经验】几种数据导入方式
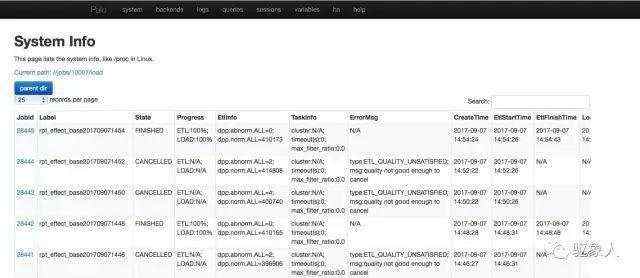
导入任务查看
通过 http://fehost:8030界面可以查看导入进度,由于暂不支持直接通过kafka导入实时数据,测试时我们通过hdfs方式导入,从kafka中接入数据用sparkstreaming将数据聚合后写入到hdfs,再用jdbc执行load命令进行数据加载。
【小经验】 记录一下导入数据时遇到的一些问题:
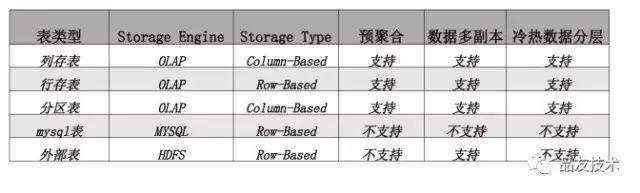
选择合适的表类型
可以根据实际需要选择合适的表类型,自定义存储引擎、副本数和存储介质。
多表数据导入原子性
为了解决导入的原子性的需求,比如RTB报表中经常需要通过查看地域、domain、APP等维度的竞价、曝光、点击、转化等效果指标来优化广告投放效果
域名维度
app维度
地域维度
如果采用宽表的方式一张表同时存地域、domain、app等维度和指标,由于地域、domain、app维度的基数大,加上时间、广告主、投放计划等更多维度后,采用Palo的olap表二次聚合之后数据量依然会非常大,会严重影响交互式查询的效率,常规的做法可以将地域、domain、app等基数较大的维度单独拆分成多张表,将同一份数据拆分成多张表,这样会额外增加多张表数据一致性的维护成本。Palo为了解决导入原子性和一致性的问题,废弃了实时导入,通过小批量导入的方式可以将同一份数据源同时导入到多张表,导入时要么同时成功,要么同时失败。避免数据不一致的问题。
【小经验】加速查询Rollup Index
针对查询比较频繁的维度和指标建立rollup index可以加速查询,测试发现导入2亿原始数据,有些查询时间原本在分钟级别通过创建rollup index后可以数秒内返回。
但是也不推荐创建太多的rollup index,导入数据时会增量累加rollup index中的数据,创建过多会影响导入数据的性能
【小经验】数据修复
另外值得一提的是Palo对于错误数据的恢复方式也比较简单,支持delete语句,可以通过sql删除指定分区的数据重新导入即可;如果通过hdfs方式导入了一批错误的数据可以通过负导入的方式恢复到导入之前的状态
查询测试
Palo支持mysql jdbc接口,数据导入成功后通过Navicat等数据库客户端工具或者在程序中使用mysql jdbc driver查询表数据。
查询时遇到的问题:查询时碰到了Memory limit exceeded. Tablet: 57198.的错误,原因是Plao防止用户单个查询消耗资源过大,将执行计划分片使用的内存限制在2G以内,用户可以根据需要适当增大exec_mem_limit的值。
3. Palo总结
最后总结一下,除了在实时性、数据导入速度方面ClickHouse的表现会比Palo更优秀。从查询性能、易用性和使用时的灵活性角度出发,Palo的表现非常优秀,当然由于Palo刚开源还是会存在一些问题,比如监控工具还不太完善,没有方便的后台管理界面,不支持kafka实时数据倒入。相信如果Palo能够在这些方面有所突破未来一定会吸引更多的用户。
在此,我也特别感谢百度Palo研发团队给力的大力支持,他们曾经第一时间周末加班解决我们发现的技术问题,并且来到品友进行大数据技术交流。
来源:品友技术











 京公网安备 11010802041100号
京公网安备 11010802041100号