大家好,我是痞子衡,是正经搞技术的痞子。今天痞子衡给大家介绍的是MbedTLS算法库纯软件实现与i.MXRT上DCP,CAAM硬件加速器实现性能差异。
近期有 i.MXRT 客户在集成 OTA SBL 项目去实现产品的 2nd bootloader 时遇到了 MbedTLS 库算法性能问题,客户想知道 MbedTLS 纯软件实现和使用 i.MXRT 芯片里的硬件加速器实现,在性能上差距有多大。借着客户这个问题,我们今天就在 i.MXRT 上实测看一下两个方式的性能差异。
客户使用的是 i.MXRT1170,这个型号上的硬件加速器是 CAAM,相比前一代架构 i.MXRT10xx 系列上的 DCP 有升级,我们今天把 DCP 和 CAAM 同时测一下。
一、mbedtls算法库简介
MbedTLS(前身 PolarSSL)是一个开源的 SSL/TLS 算法库,最早由 ARM 公司开源和维护,现在已经移交 TrustedFirmware 社区维护。MbedTLS 开源仓库地址为:
- 项目地址:https://github.com/ARMmbed/mbedtls
MbedTLS 代码由 C 语言写成,其以最小的编码占用空间实现了 SSL/TLS 功能及各种加密算法,易于理解、使用、集成和扩展,方便开发人员轻松地在嵌入式产品中使用 SSL/TLS 功能。
MbedTLS 软件包主要提供了如下支持:
1. 完整的 SSL v3、TLS v1.0、TLS v1.1 和 TLS v1.2 协议实现
2. X.509 证书处理
3. 基于 TCP 的 TLS 传输加密
4. 基于 UDP 的 DTLS(Datagram TLS)传输加密
5. 其它加解密库实现
二、i.MXRT上的硬件加速器简介
2.1 i.MXRT10xx系列上的DCP
DCP 是 Data Co-Processor 的简称,从名字上看是个通用数据协处理器。在 i.MXRT1060 Security Reference Manual 中有一张系统整体安全架构简图,这个简图中标出了 DCP 模块的主要功能:CRC-32算法、AES算法、Hash算法、类DMA数据搬移。关于进一步用法,见痞子衡两篇旧文 《i.MXRT10xx DCP使用时密钥注意事项》、《i.MXRT10xx DCP使用时Cache注意事项》 。
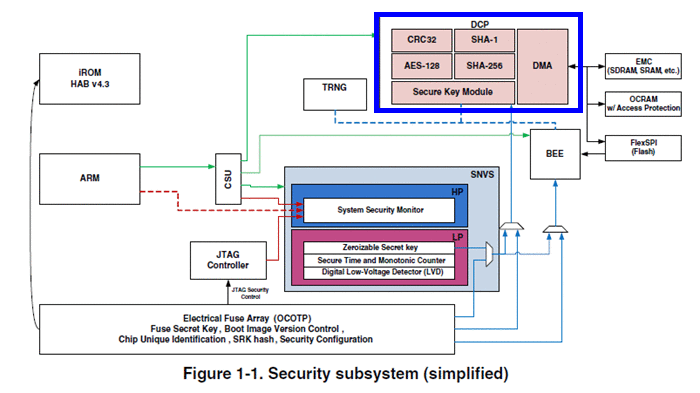
2.2 i.MXRT11xx系列上的CAAM
CAAM 是 Cryptographic Acceleration and Assurance Module 的简称,是个超全功能的安全算法加速器。在 i.MXRT1170 Security Reference Manual 中有一张系统整体安全架构简图,这个简图中标出了 CAAM 模块的主要功能,其在 DCP 已有功能上做了进一步扩展,丰富了算法支持。

三、对比常见算法的软硬件实现性能差异
3.1 官方SDK例程简介
想要在 MCU 上跑 MbedTLS 算法,正常是需要先移植 MbedTLS 源码的。但是恩智浦 i.MXRT 官方 SDK 包里已经做好了移植,源码就放在 \SDK_2.11.0_MIMXRT1xxx-EVK\middleware\mbedtls 下面,所以我们省去了移植步骤。注:在 SDK 2.11 版本里移植的是 MbedTLS 2.27.0。
此外官方 SDK 里还提供给了如下两个关于 MbedTLS 的基础例程,其中 mbedtls_selftest 是遍历全部算法,检测算法执行正确性;mbedtls_benchmark 则是提供全部算法的实际运行性能数据(编解码速率 KB/s)。
\SDK_2.11.0_MIMXRT1xxx-EVK\boards\evkmimxrt1xxx\mbedtls_examples\mbedtls_selftest
\SDK_2.11.0_MIMXRT1xxx-EVK\boards\evkmimxrt1xxx\mbedtls_examples\mbedtls_benchmark
3.2 在i.MXRT1060上实测
我们现在在 MIMXRT1060-EVK 板子上实测算法性能,就用 mbedtls_benchmark 例程,选择 debug build,即让代码跑在 TCM 里,这样可以达到最好性能,不让存储器性能成瓶颈从而影响算法性能数据。此外 i.MXRT1060 内核频率也是配到了最高 600MHz。
mbedtls_benchmark 例程默认是启用硬件加速器 DCP 来实现算法的,因为我们要对比 MbedTLS 纯软件实现和 DCP 硬件实现性能差异,所以在测试纯软件方式时需要在工程源文件 MIMXRT1062_features.h 里将下面这个宏临时设为 0,这时候工程可能会编译不通过(代码链在 128KB ITCM 里),因为纯软件方式代码相比硬件驱动方式代码要大得多,此时可以在 benchmark.c 或者 ksdk_mbedtls_config.h 注释掉一些算法执行来减少最终代码体(保留你感兴趣的算法)。
/* @brief DCP availability on the SoC. */
#define FSL_FEATURE_SOC_DCP_COUNT (0)
算法性能数据跟 IDE 以及编译优化选项也有关系,我们这里选择了 IAR,优化选项分别测试了 None 以及 High Speed,No Size constraints 两种,因为算法特别多,我们就摘比较常用的 SHA 和 AES,其对比结果如下:
| 测试算法项 | 测试结果(IAR v9.10) | |||
|---|---|---|---|---|
| Opt-None SW-mbedtls | Opt-HighSpeed SW-mbedtls | Opt-None HW-DCP | Opt-HighSpeed HW-DCP | |
| SHA-1 | 15967.90 KB/s 36.02 cycles/byte | 19260.52 KB/s 30.13 cycles/byte | 55207.68 KB/s 10.09 cycles/byte | 66164.77 KB/s 8.54 cycles/byte |
| SHA-256 | 6141.10 KB/s 94.83 cycles/byte | 15473.87 KB/s 37.57 cycles/byte | 60976.40 KB/s 9.09 cycles/byte | 74910.71 KB/s 7.51 cycles/byte |
| SHA-512 | 4723.55 KB/s 123.51 cycles/byte | 7428.60 KB/s 78.55 cycles/byte | 4720.28 KB/s 123.61 cycles/byte | 7430.49 KB/s 78.56 cycles/byte |
| AES-CBC-128 | 6731.48 KB/s 86.55 cycles/byte | 10957.42 KB/s 53.18 cycles/byte | 58411.12 KB/s 9.52 cycles/byte | 61560.47 KB/s 9.17 cycles/byte |
3.3 在i.MXRT1170上实测
与上一节同样的方法,在 MIMXRT1170-EVK 板子上也测一下,同样 mbedtls_benchmark 例程 debug build,注意 i.MXRT1170 是双核芯片,我们在 Cortex-M7 下做测试,将内核频率配到最高 996MHz。
测试 i.MXRT1170 上纯软件方式时仅需要在工程选项预编译宏里将 CRYPTO_USE_DRIVER_CAAM 去掉即可,当然也可以在 MIMXRT1176_cm7_features.h 里将下面这个宏临时设为 0,这时候没有代码空间顾虑,i.MXRT1170 上默认 ITCM 是 256KB。最终测试结果如下:
/* @brief CAAM availability on the SoC. */
#define FSL_FEATURE_SOC_CAAM_COUNT (0)
| 测试算法项 | 测试结果(IAR v9.10) | |||
|---|---|---|---|---|
| Opt-None SW-mbedtls | Opt-HighSpeed SW-mbedtls | Opt-None HW-CAAM | Opt-HighSpeed HW-CAAM | |
| SHA-1 | 13156.48 KB/s 72.45 cycles/byte | 14298.92 KB/s 66.73 cycles/byte | 20981.07 KB/s 44.78 cycles/byte | 27023.34 KB/s 34.61 cycles/byte |
| SHA-256 | 7206.51 KB/s 133.46 cycles/byte | 12208.04 KB/s 78.36 cycles/byte | 20970.20 KB/s 44.84 cycles/byte | 27007.46 KB/s 34.62 cycles/byte |
| SHA-512 | 5897.39 KB/s 163.43 cycles/byte | 8238.67 KB/s 116.73 cycles/byte | 5894.95 KB/s 163.57 cycles/byte | 8227.76 KB/s 116.91 cycles/byte |
| AES-CBC-128 | 5419.23 KB/s 178.02 cycles/byte | 6352.19 KB/s 151.85 cycles/byte | 39786.80 KB/s 22.96 cycles/byte | 41433.36 KB/s 22.04 cycles/byte |
| AES-CBC-192 | 5059.84 KB/s 190.79 cycles/byte | 6064.90 KB/s 159.10 cycles/byte | 36596.29 KB/s 25.08 cycles/byte | 38127.75 KB/s 24.15 cycles/byte |
| AES-CBC-256 | 4745.47 KB/s 203.54 cycles/byte | 5803.56 KB/s 166.32 cycles/byte | 34012.50 KB/s 27.11 cycles/byte | 35229.83 KB/s 26.17 cycles/byte |
3.4 性能测试总结
- 结论1:使用硬件加速器CAAM模块/DCP模块,相比 MbedTLS 纯软件实现,对于大部分算法性能都会有提升,但具体提升比例因算法本身复杂度而异。
- 结论2:硬件加速器方式提升比例较大的是 3DES/DES(近10倍)、AES/ECDSA/ECDHE(近7倍)、RSA(3-5倍)、SHA-1/256(近2倍)。
- 结论3:硬件加速器方式对于部分算法,测试数据长度越大(默认1KB buffer,比如调到10KB),性能提升更明显。
- 结论4:编译器优化等级设置对 MbedTLS 纯软件和硬件加速器方式都有一定影响。
- 结论5:CAAM模块比DCP模块在算法支持度上要高很多,但编解码速度性能上并没有显著提升。
至此,MbedTLS算法库纯软件实现与i.MXRT上DCP,CAAM硬件加速器实现性能差异痞子衡便介绍完毕了,掌声在哪里~~~
欢迎订阅
文章会同时发布到我的 博客园主页、CSDN主页、知乎主页、微信公众号 平台上。
微信搜索"痞子衡嵌入式"或者扫描下面二维码,就可以在手机上第一时间看了哦。











 京公网安备 11010802041100号
京公网安备 11010802041100号