主要代码
package cn.nanxiuzi.kafka.kafka2mysql;import cn.nanxiuzi.kafka.KafkaDic;import com.google.common.collect.Lists;import org.apache.flink.api.common.functions.MapFunction;import org.apache.flink.api.common.serialization.SimpleStringSchema;import org.apache.flink.streaming.api.CheckpointingMode;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.api.functions.windowing.ProcessAllWindowFunction;import org.apache.flink.streaming.api.windowing.time.Time;import org.apache.flink.streaming.api.windowing.windows.TimeWindow;import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import org.apache.flink.util.Collector;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.util.ArrayList;import java.util.List;import java.util.Properties;/** * 读取kafka之后写入mysql */public class Kafka2Mysql { public static final Logger logger = LoggerFactory.getLogger(Kafka2Mysql.class); public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //checkpoint的设置 //每隔10s进行启动一个检查点【设置checkpoint的周期】 env.enableCheckpointing(10000); //设置模式为:exactly_one,仅一次语义 env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); //确保检查点之间有1s的时间间隔【checkpoint最小间隔】 env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1000); //检查点必须在10s之内完成,或者被丢弃【checkpoint超时时间】 env.getCheckpointConfig().setCheckpointTimeout(10000); //同一时间只允许进行一次检查点 env.getCheckpointConfig().setMaxConcurrentCheckpoints(1); //表示一旦Flink程序被cancel后,会保留checkpoint数据,以便根据实际需要恢复到指定的checkpoint //env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); //设置statebackend,将检查点保存在hdfs上面,默认保存在内存中。这里先保存到本地// env.setStateBackend(new FsStateBackend("file:///Users/temp/cp/")); Properties ppt = new Properties(); ppt.setProperty("bootstrap.servers", KafkaDic.Kafka_ADDRESS_COLLECTION); ppt.setProperty("group.id", KafkaDic.CONSUMER_GROUP_ID); ppt.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); ppt.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); FlinkKafkaConsumer
Kafka生产者代码
package cn.nanxiuzi.kafka;import org.apache.kafka.clients.producer.KafkaProducer;import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;public class MyKafkaProducer { public static void main(String[] args) { Properties props = new Properties(); props.put("bootstrap.servers", KafkaDic.Kafka_ADDRESS_COLLECTION); props.put("acks", "all"); props.put("retries", 0); props.put("batch.size", 16384); props.put("linger.ms", 1); props.put("buffer.memory", 33554432); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); KafkaProducer
DBConnectUtil
package cn.nanxiuzi.kafka.kafka2mysql;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.sql.DriverManager;import java.sql.SQLException;import java.sql.Connection;/** * Created with IntelliJ IDEA. * User: zzy * Date: 2019/5/28 * Time: 8:58 PM * To change this template use File | Settings | File Templates. */public class DBConnectUtil { private static final Logger log = LoggerFactory.getLogger(DBConnectUtil.class); /** * 获取连接 * * @param url * @param user * @param password * @return * @throws SQLException */ public static Connection getConnection(String url, String user, String password) throws SQLException { Connection conn = null; try { Class.forName("com.mysql.jdbc.Driver"); } catch (ClassNotFoundException e) { log.error("获取mysql.jdbc.Driver失败"); e.printStackTrace(); } try { conn = DriverManager.getConnection(url, user, password); log.info("获取连接:{} 成功...",conn); }catch (Exception e){ log.error("获取连接失败,url:" + url + ",user:" + user); } //设置手动提交 //conn.setAutoCommit(false); return conn; } /** * 提交事物 */ public static void commit(Connection conn) { if (conn != null) { try { conn.commit(); } catch (SQLException e) { log.error("提交事物失败,Connection:" + conn); e.printStackTrace(); } finally { close(conn); } } } /** * 事物回滚 * * @param conn */ public static void rollback(Connection conn) { if (conn != null) { try { conn.rollback(); } catch (SQLException e) { log.error("事物回滚失败,Connection:" + conn); e.printStackTrace(); } finally { close(conn); } } } /** * 关闭连接 * * @param conn */ public static void close(Connection conn) { if (conn != null) { try { conn.close(); } catch (SQLException e) { log.error("关闭连接失败,Connection:" + conn); e.printStackTrace(); } } }}
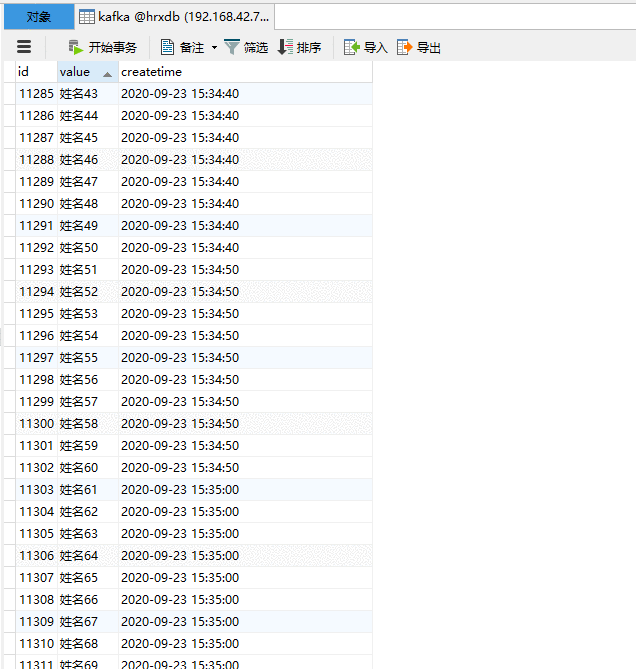
输出


pom.xml



 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有