PaddleX数据标注与Halcon数据标注与转换
- 一、简介
- 二、PaddleX数据标注
- 2.1Labelme数据标注
- 2.2json数据转换
- 三、Halcon数据标注
- 3.1MVTec Deep Learning Tool下载安装
- 3.2数据标注与导出
- 四、Halcon中使用PaddleX标注的数据
- 4.1PaddleX标注的数据转换为Halcon标注数据
- 4.2Labelme标注的数据转换为Halcon标注数据
- 参考文档
一、简介
PaddleX为百度飞浆开发的一种开源的深度学习架构,可用于目标检测、语义分割等任务,相较于TensorFlow、Pytorch两种开源架构搭建、训练模型简单,代码量少,易上手。
Halcon作为一款商业机器视觉软件开发包,可用于图像处理与深度学习,使用效果要优于多数开源软件。
本文主要记录了在语义分割任务中PaddleX与Halcon数据标注的实现流程,及在Halcon中使用PaddleX标注的数据的方法和相应代码。
二、PaddleX数据标注
PaddleX中数据标注工具为labelme,labelme支持标注矩形框和多边形,可分别应用于目标识别与语义分割任务,且为语义分割任务标注的多边形还可应用于目标识别任务,无需二次标注。
下面介绍在语义分割任务中PaddleX数据标注。
2.1Labelme数据标注
labelme运行在python环境中,使用前需进行安装。
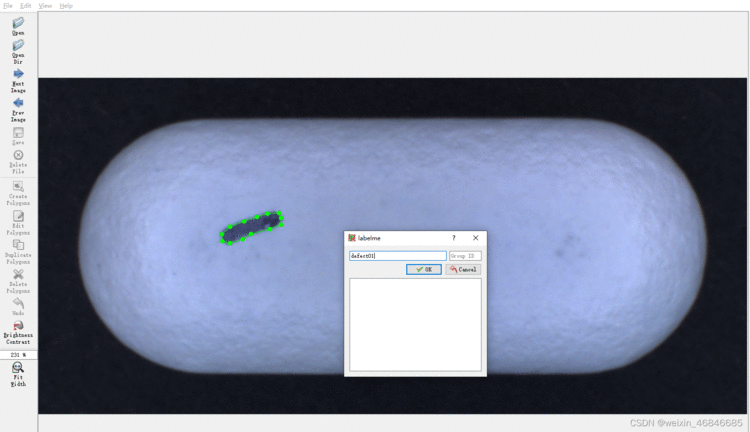
上图为labelme标注药片表面缺陷示意图,标注完成后会在图片同路径下生成一个json文件,文件中包含标签名、标注的多边形坐标点及原始图片base64编码。

2.2json数据转换
PaddleX中语义分割任务训练需要使用的数据包含两部分,一部分为原始图片,一部分为标注图片,标注图片为只包含以一定颜色填充的标注区域的图片。而labelme标注后得到的是json数据,因此需要进行转换,在PaddleX中提供了转换工具,转换命令如下:
paddlex --data_conversion --source labelme --to SEG --pics ./ --annotations ./ --save_dir ./data
生成文件如下:

JPEGImages文件夹中存储原始图片,Annotations中存储标注图片,如下:
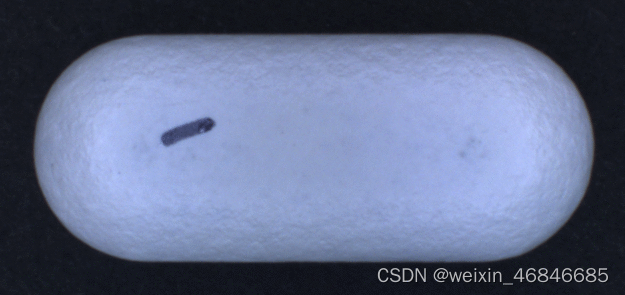

PaddleX数据标注完成。
三、Halcon数据标注
Halcon数据标注一般使用官方给出的标注工具:MVTec Deep Learning Tool,该工具未集成在Halcon软件中,需单独进行下载。
3.1MVTec Deep Learning Tool下载安装
官网下载地址为https://www.mvtec.com/downloads/deep-learning-tool,官网提供免费下载,但下载需要填写邮箱、姓名、电话等信息进行账户注册,需提供真实邮箱以接收验证码。
进入下载界面后,选择DEEP LEARNING TOOL最新版本即可,该版本与使用的Halcon版本不存在对应关系,本文下载的版本为DEEP LEARNING TOOL 22.10,使用的Halcon版本为19.05。
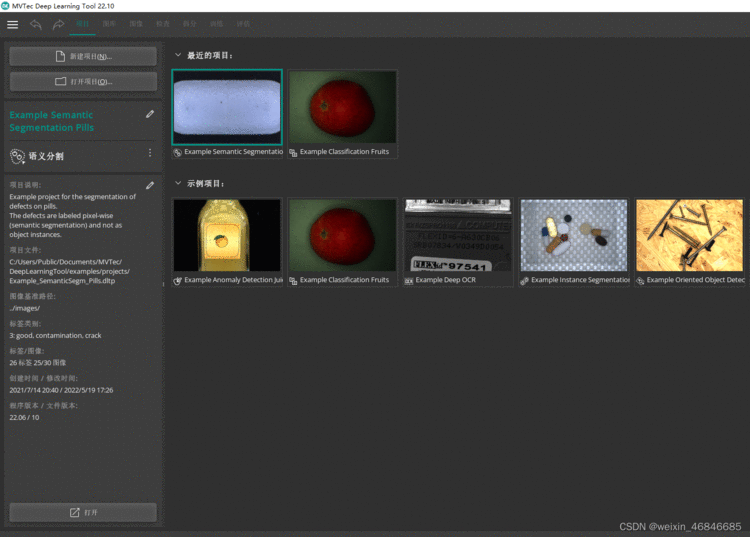
下载后进行安装,需要注意的是该工具安装界面为网页,即在网页上进行软件安装,安装之后打开软件,主界面如下:
3.2数据标注与导出
打开软件后,选择创建新项目,选择深度学习方法,可以看到支持图像分类、对象检测、语义分割、实例分割等任务,这里选择语义分割,输入项目名称与保存路径进行创建。
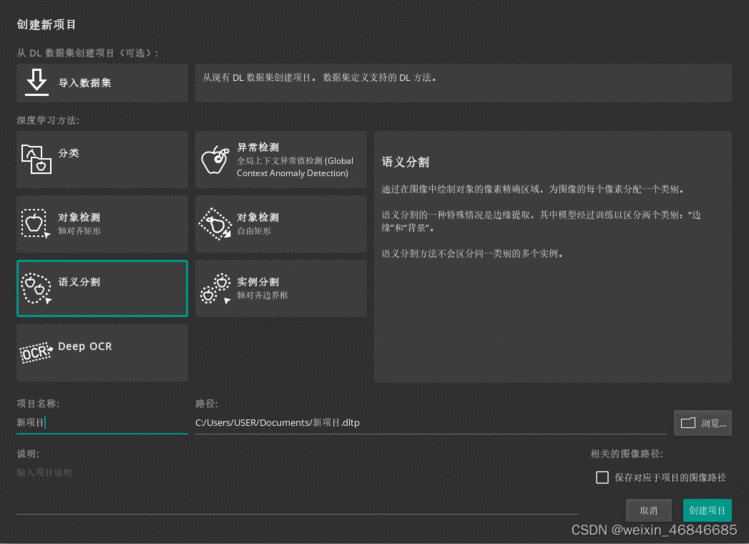
创建项目后,添加图像,点击菜单栏的“图像”,开始标注:
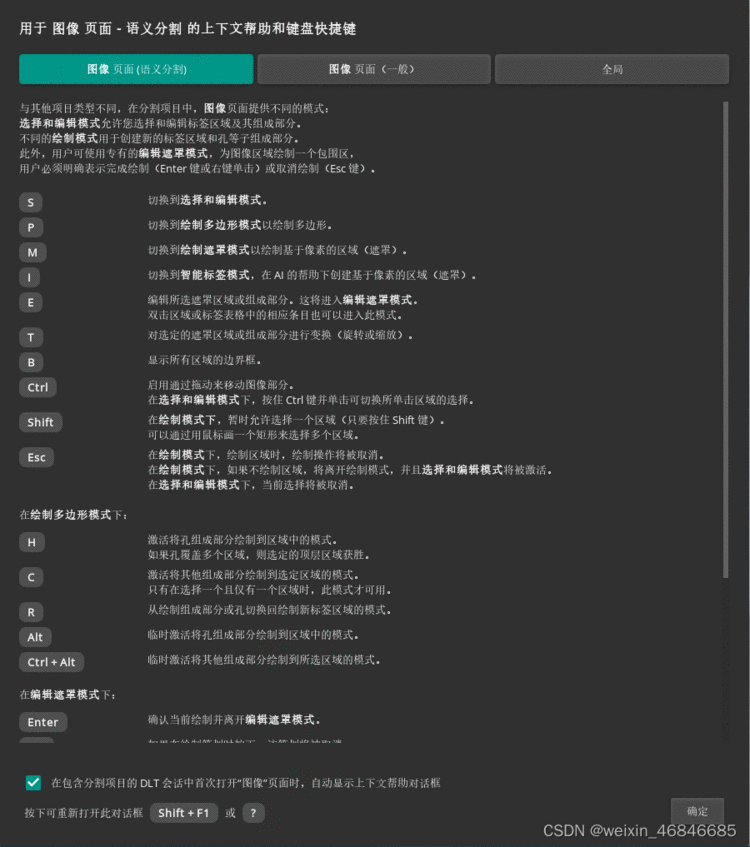
首先单击标签类别旁边的加号+,添加标签,输入类别名称,选择需要的高亮颜色。在Halcon中除自己添加的标签类别外还有一个自动生成的背景类别标签,导出数据时,每个未标注的像素都将属于背景。
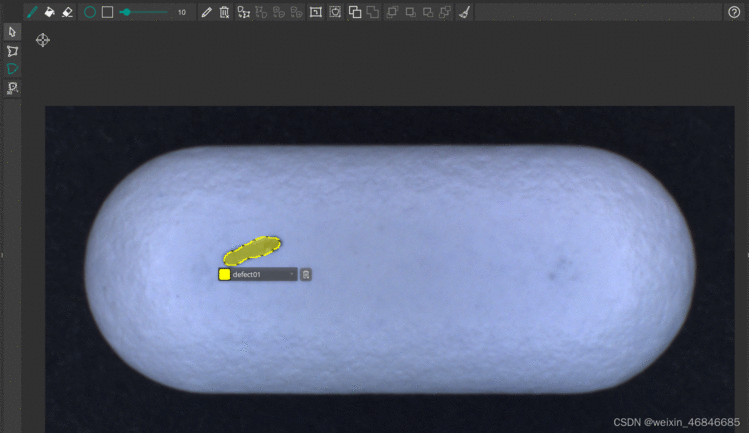
在图片上标注时可以选择多边形或遮罩,视待标注对象的性质而定,其中一种方法可能更适用。 根据经验,如果对象的标签由较大的边缘平整的区域组成,则使用多边形;如果对象较小或需要修正某现有标签,则使用遮罩。但是,多边形或遮罩始终可以相互转换。
完成标注后选择菜单栏的导出数据集。
导出时勾选“将图像复制到文件夹…”。
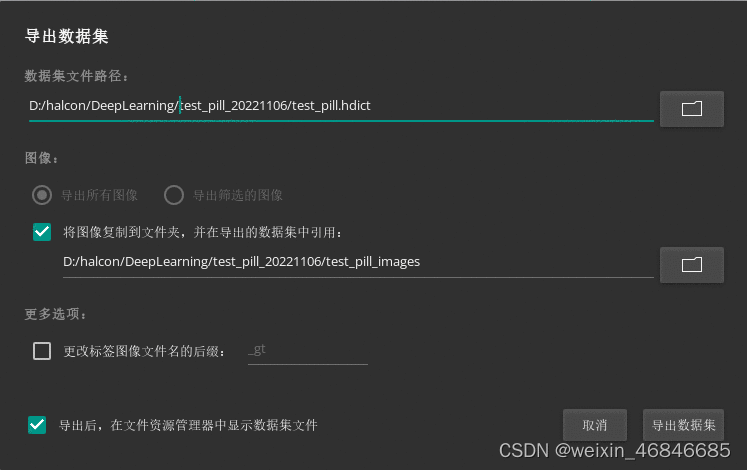
导出完成后会生成两个文件夹和一个hdict文件,如下图:
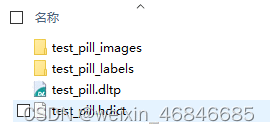
test_pill_images文件夹保存原始图片,test_pill_labels保存标注图片,需要注意的是打开标注图片后,会发现标注区域不可见,原因是Halcon导出时是使用标签类别的索引值如1作为灰度值填充,而不像是PaddleX中以可见灰度值如128填充。

Halcon数据标注完成。
四、Halcon中使用PaddleX标注的数据
在进行语义分割时数据标注过程费时费力,如果使用多个架构进行试验而只需进行一次标注,那么工作效率就会大幅度提升。
4.1PaddleX标注的数据转换为Halcon标注数据
将PaddleX标注的数据转换为Halcon标注数据,其实就是将PaddleX标注图片中的灰度值转换为Halcon中以标签类别的索引值写入的灰度值,主要涉及到像素灰度值读写,下面给出以opencv实现的python代码,值得注意的是标签类别索引以1开始,因为0默认为背景:
def SetImagePixelValues(FilePathList):
for i in range(len(FilePathList)):
for dirpath,dirnames,filenames in os.walk(FilePathList[i]):
filenames=filter(lambda filename:filename[-4:]=='.png',filenames)
for filename in filenames:
img_color=cv2.imread(dirpath+"/"+filename,cv2.IMREAD_UNCHANGED)
img_gray=cv2.cvtColor(img_color,cv2.COLOR_RGB2GRAY)
imgWidth=img_gray.shape[1]
imgHeight=img_gray.shape[0]
for j in range(imgWidth):
for k in range(imgHeight):
value=img_gray[k,j]
if value > 0:
img_gray[k,j]=(i+1)
cv2.imwrite(dirpath+"/"+filename,img_gray)
print(dirpath+"/"+filename)
这里传入的FilePathList变量是存放各类标签图片的文件夹路径列表。
4.2Labelme标注的数据转换为Halcon标注数据
将labelme标注的数据转换为Halcon标注数据,分为两步,第一步是将json数据转换为图片数据,labelme中有单个数据转换的程序示例,加以改动为多个数据转换即可,但程序中未显式设置转换后的标注区域灰度值,所以需要进行第二步,第二步即4.1节所述。
json数据转换为图片数据python代码如下:
def main(JsonFilePathlist, label_name_to_value):
for i in range(len(JsonFilePathlist)):
jsonfiles=[]
jsonfilenames=[]
out_dir=JsonFilePathlist[i]
if not osp.exists(out_dir+"/images"):
os.mkdir(out_dir+"/images")
if not osp.exists(out_dir+"/labels"):
os.mkdir(out_dir+"/labels")
for dirpath,dirnames,filenames in os.walk(JsonFilePathlist[i]):
filenames=filter(lambda filename:filename[-5:]=='.json',filenames)
filenames01=copy.deepcopy(filenames)
jsonfilenames.extend(filenames01)
filenames=map(lambda filename:os.path.join(dirpath,filename),filenames)
jsonfiles.extend(filenames)
for j in range(len(jsonfiles)):
data = json.load(open(jsonfiles[j]))
imageData = data.get("imageData")
if not imageData:
imagePath = os.path.join(os.path.dirname(jsonfiles[j]), data["imagePath"])
with open(imagePath, "rb") as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode("utf-8")
img = utils.img_b64_to_arr(imageData)
for shape in sorted(data["shapes"], key=lambda x: x["label"]):
label_name = shape["label"]
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
lbl, _ = utils.shapes_to_label(
img.shape, data["shapes"], label_name_to_value
)
label_names = [None] * (max(label_name_to_value.values()) + 1)
for name, value in label_name_to_value.items():
label_names[value] = name
lbl_viz = imgviz.label2rgb(
label=lbl, img=imgviz.asgray(img), label_names=label_names, loc="rb"
)
PIL.Image.fromarray(img).save(osp.join(out_dir, "images/"+jsonfilenames[j][0:-5]+".png"))
utils.lblsave(osp.join(out_dir, "labels/"+jsonfilenames[j][0:-5]+".png"), lbl)
logger.info(jsonfiles[j])
这里传入的JsonFilePathlist变量是存放各类标签json文件的文件夹路径列表,label_name_to_value是标签类别名称与标签类别索引的字典,包括背景,示例定义如下:
label_name_to_value={}
label_name_to_value["_background_"]=0
label_name_to_value["Label01"]=1
label_name_to_value["Label02"]=2
label_name_to_value["Label03"]=3
label_name_to_value["Label04"]=4
label_name_to_value["Label05"]=5
label_name_to_value["Label06"]=6
label_name_to_value["Label07"]=7
label_name_to_value["Label08"]=8
参考文档
Halcon深度学习2 – 标注工具Deep Learning Tool下载安装
如何通过labelme标注将json文件转为png的label









 京公网安备 11010802041100号
京公网安备 11010802041100号