作者:男人着责任 | 来源:互联网 | 2023-08-20 10:06
爬取流程
- 先找到浏览器标识头(User-Agent也可以网上搜这个头子)
红圈是头,复制出来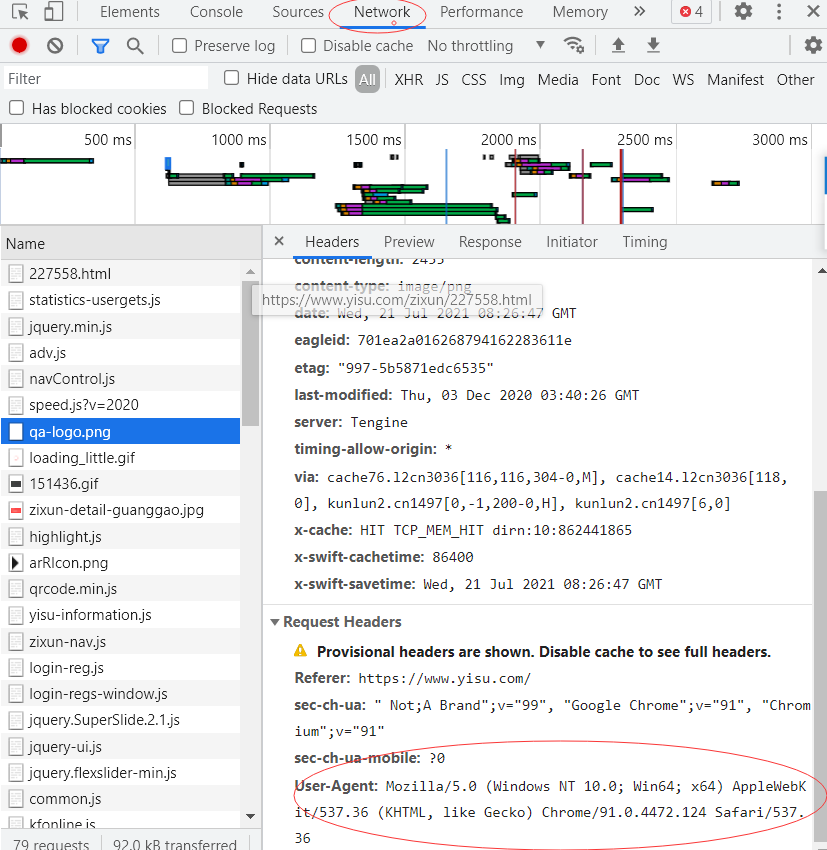
- (关键)找传回数据的url
目标网站:b站搜索
爬取这个:
开始我直接通过网页渲染数据爬取框内内容,发现这些内容是ajax请求渲染,网站加载完成才渲染出数据,不能第一时间爬取到,然后我开始另辟蹊径。。。找了好久终于找到
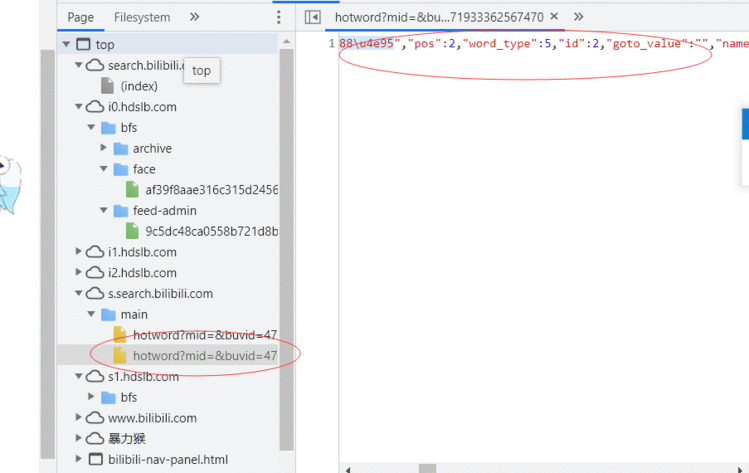
找到传回数据后面就好办了。。。。 - 代码实现
先导需要的库 ,mysql连python用到: pip install pymysql
import requests
import json
import pymysql.cursors
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36'
}product=[]
resp=requests.get('https://s.search.bilibili.com/main/hotword?mid=&buvid=98E676EF-F586-403E-8440-52A6836FA68713451infoc&jsonp=jsonp&callback=jsonCallback_bili_58910703464582290',headers=headers)rest=resp.text.replace('jsonCallback_bili_58910703464582290(','').replace(')','')json_data=json.loads(rest)comments=json_data["list"]
proDict=[]
for item in comments:proDict.append(item['keyword']+' ')
product.extend(proDict)
p=''.join(proDict)print(p)
conn = pymysql.connect(host='127.0.0.1',port=3306,user='root',passwd='root',db='bilidb',charset='utf8',cursorclass=pymysql.cursors.Cursor,)cur=conn.cursor()
for item in proDict:cur.execute("replace into hot(hotword) values('%s')" %(item))
try: conn.commit()
except AttributeError:print("错误")
cur.close()
数据库结构
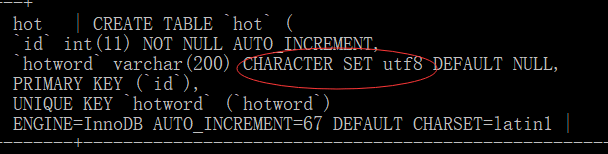
数据库上记得把字段设置编码方式为utf-8,以解决中文乱码问题。





 京公网安备 11010802041100号
京公网安备 11010802041100号