作者:胡慧君孟勋欣怡 | 来源:互联网 | 2023-07-01 14:38
最好的建议,是将图片之类的保存在一个文件夹中所以可以进行以下操作 思路如下 Xpath解析再xml文档中搜索内容的一门语言html是xml的一个子集 被
最好的建议,是将图片之类的保存在一个文件夹中
所以可以进行以下操作

思路如下

Xpath解析
再xml文档中搜索内容的一门语言
html是xml的一个子集

被包含的是包含的子节点,包含的是被包含的父节点,同级之间为兄弟节点
需要使用lxml模块


网上随便找的xml可能用不了,因为xml只能有一个根目录,没有就自己套一个
xpath并不会直接弹出,但是也可以写出来并使用

/*/可以理解为任意孙节点中包含nick的

最后一句相对于寻找book中所有包含有nick/text()的
错误代码:
Opening and ending tag mismatch:

绿色部分为解决方法,原因是:该方法默认使用的是“XML”解析器,所以如果碰到不规范的html文件时就会解析错误
使用xpath需要注意相对查找这种东西,应用场景是从中获取一定的路径时

利用xpath获取属性值

进行 相应的筛选,xpath中所有的索引号是从1开始的

使用xpath的原因之一,是可以偷懒
实战:猪八戒网
没学明白
正常来说,一个网站内的id是不能够重复的
request进阶:
1.模拟浏览器登录->处理COOKIE
2.防盗链处理->抓取梨视频数据
3.代理->防止被封IP(尽量少用,灰色地带)
COOKIE的作用,处理那些登录前后显示不同界面的网站

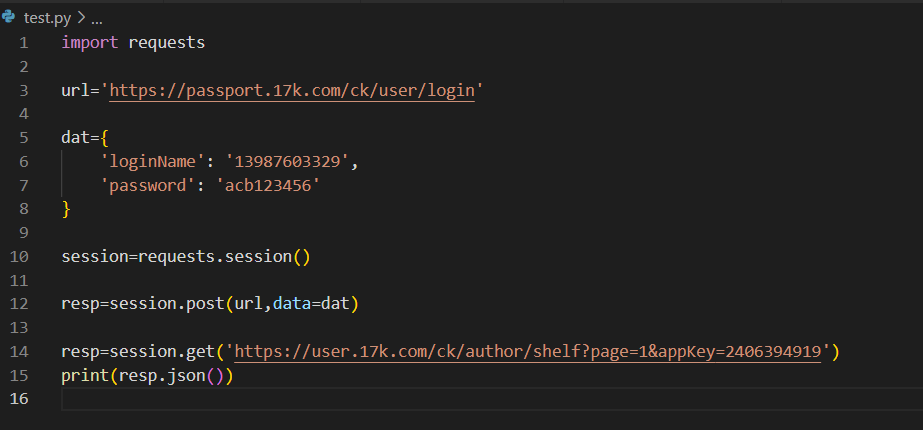
实战,获得17K小说网的阅读记录
需求:

由于需要操作联系,使用session,一连串的请求,在这个过程中COOKIE不会消失
session的作用是获得会话


首先,找到传输账号密码的网站
先让自己能够登录

然后,找到包含书架信息的url
此时不应该直接用get,因为这个新的get是不知道刚才登录后的本机的COOKIE的,所以要用session
具体操作如上
当让也可以直接用request

爬取梨视频
通过F12可以发现视频链接,但是,在视频源代码中却找不到视频链接,所以可以推断出,视频链接是后期通过二次加载的形式放进网页的,所以认定为电脑使用了反爬机制
F12看到的网页代码是实时的
所以,开启抓包,刷新网页,选择xhr,看看能得到什么

但该url却不能设置为视频,所以进行比较

可以认定为是对传到的链接进行了一次加工
防盗链:
如果要打开一个页面,那理所当然的应该打开其之前一个页面,但是爬虫会直接访问后一个页面,所以,会被检测出来,于是,需要在request中的header里,加入需要的refer
从json中获取想要的东西

像这样的具有防爬虫机制的网页,需要找到该网页所想要获得资源和原网页拥有的联系,然后替换后找到原网页
很多时候F12得到的页面和网站源代码的内容是不匹配的
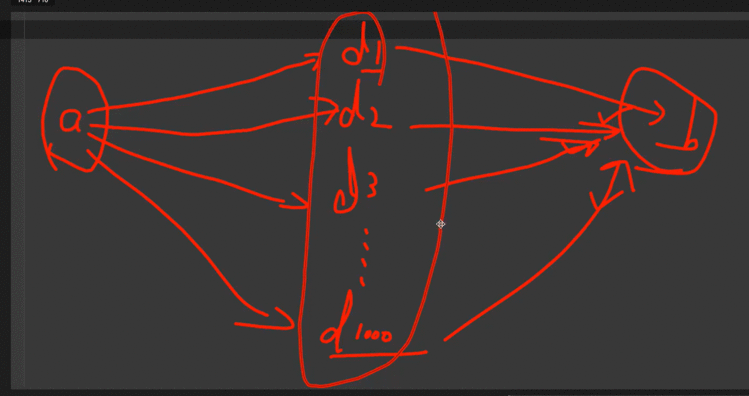
代理:
具有法律边界问题,一般情况下不建议使用
原理是,通过第三方的机器去发送请求
因为有些网站,如果发现请求次数很多的时候,会封你IP
代理相当于还是你去请求,但是你每次换一个IP去做你想做的事情
使用步骤,
1,先写出一个正常的爬虫
2,找到想要使用的代理IP
代理IP格式:代理IP:端口号
常说的透明的好用

综合实战:
抓取网易云热评
像网易云这样的大公司,在网易云的网页版中可以发现,能找到两套源代码
因为那个大网页是由多个小网页嵌套在一起的


在这个抓包到的东西中可以发现,真实数据已经被加密了

需求如上
这时,需要我们考虑,如何才能获得未加密的参数,如何获得加密过程,由于是post,所以,这些参数都是在本机(浏览器上进行相应操作的)
 是在启动器/Initator可以看到,顺序是从下往上
是在启动器/Initator可以看到,顺序是从下往上
从最后一个开始看(数据在这一层被上传到网易服务器)

由于是发送了东西,我们也就想要找到我们想要的网页里面的get

第一个send里面没有
不断执行断点,直到内容中出现我们想要的为止


找到了data,开始往回看
回看是看启动器里面的下一个启动器,看参数是在那一层被加密的‘
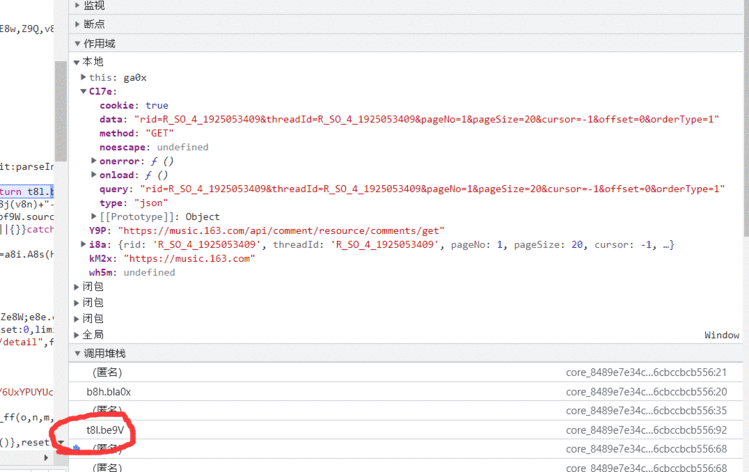
可见,我们的参数在进入这一层之前都是正常的
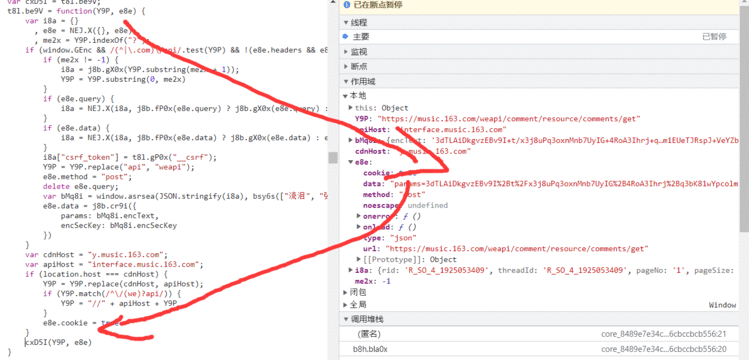
所以可以认为,代码在是在这一层被加密的
在该方法中施加断点,然后每次一步,看看是在哪一步进行加密的
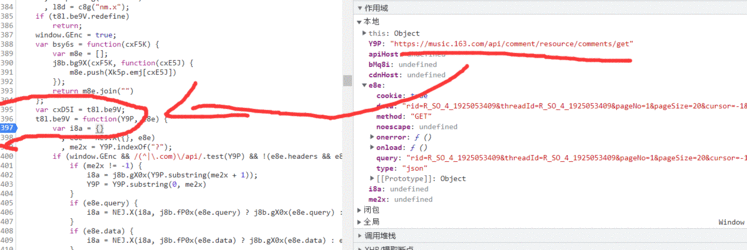
按这个方式,找到最后的原始数据(下一步就进行加密)


经过以上分析,可以得出最初始的参数是
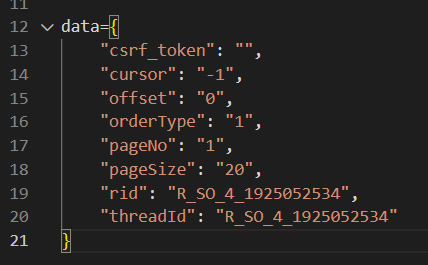
是经过函数

才变成

的,到此为止,我们已经能成功找到原始数据,接下来,我们需要处理加密过程

通过加密函数名,我们找到了加密函数的原始位置
第一项是数据,也就是data
第二项在命令行中操作后得到010001
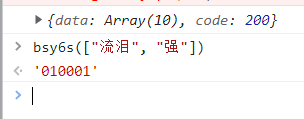
第三项也是给定值

第四项也是定值

知道了这些值的含义以后,打开复制下加密的程序代码,理解并对该代码使用python重构
只需要构建有用的
放开思路,很多时候,如果一个参数的输入为一个随机数,那结果也一定是随机,但如果把这个随机值定死,那么,这个结果也是固定的

根据之前已知,efg是固定的定值,所以,如果i也是定值(c中并没有随机值)那么encSecKey的值就是固定的(神来之笔)
再看entext

使用了AES加密
可以使用

由于要对加密后的东西进行编码需要引入一个新的库

最后重构出的如图所示:

由于需要对加密出来的东西进行传送,需要对其进行编码,步骤如上

运行即可得到当前歌曲的信息
经过我修改之后,现在只需要输入歌曲网站地址,就能得到热门评论。
import requests
from Crypto.Cipher import AES
from base64 import b64encode
import json
import re
domain=input("请输入歌曲网站的url: ")
url='https://music.163.com/weapi/comment/resource/comments/get?csrf_token='
sOngID=str(domain).split('=')[1]
data={
"csrf_token": "",
"cursor": "-1",
"offset": "0",
"orderType": "1",
"pageNo": "1",
"pageSize": "20",
"rid": "R_SO_4_"+songID,
"threadId": "R_SO_4_"+songID
}
def get_params(data):
first=enc_params(data, g)
secOnd=enc_params(first, i)
return second
def enc_params(data,key):
iv="0102030405060708"
data=to_16(data)
aes=AES.new(key=key.encode('utf-8'),IV=iv.encode('utf-8'),mode=AES.MODE_CBC)
bs=aes.encrypt(data.encode('utf-8'))
return str(b64encode(bs),'utf-8')
def to_16(data):#由于aes加密的要求,需要这么做
pad=16-len(data)%16
data+= chr(pad)*pad
return data
e='010001'
f='00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7'
g='0CoJUm6Qyw8W8jud'
i='yRb6vQKULFtYpStG'
encSecKey="8e71223d1f141eaa3b17f68d3028cf9a5e910a8f0e2e4b21b7b14e6f7ae4f6bc95f494f526bf79e3ef823afe6785c0ca646ffb795a2996cc4652a2c88e75746ce80d74aff4f8a5bac0ce8d502fae35e575607573e59fa6cf1e65d9ba781fa3fc66a1806c62b5f47ba0847a2666ff15f471cc83b9086a698c7365274a1438e008"
resp=requests.post(url,data= {
"params":get_params(json.dumps(data)),
"encSecKey":encSecKey
})
key1=re.compile(r'"content":"(?P.*?)","status"',re.S)
key0=re.compile(r'"hotComments":(?P.*?):null}]}}',re.S)
abc=key0.search(resp.text)
abc=key1.finditer(abc.group())
with open('file.txt',mode='w')as f:
for i in abc:
f.writelines(i.group('get'))
f.writelines('\n')
如上










 京公网安备 11010802041100号
京公网安备 11010802041100号