作者:徐毛毛的大猫儿 | 来源:互联网 | 2023-08-16 03:34
fromurllib.requestimporturlopenfromurllib.errorimportURLError,HTTPErrorurlhttp:sou.
from urllib.request import urlopen
from urllib.error import URLError,HTTPError
url = 'http://sou.zhaopin.com/jobs/searchresult.ashx?jl=%E8%A5%BF%E5%AE%89&kw=python&sm=0&p=1'
def download(url,num_retries=3):
print('download... %s' % url)
try:
res = urlopen(url)
code_ = res.info()['Content-Type'].split('=')[-1]
html = res.read().decode(code_)
except HTTPError as e:
print(e.code)
html = None
if num_retries > 0:
print('[E]Http Error!Try Downlooad %d times' % (3-num_retries))
if hasattr(e,'code') and 500 <= e.code <= 600:
html = download(url,num_retries-1)
else:
print('[E]Failed!')
except URLError as e:
html = None
print('[e]Unloacted URL!',url)
return html
if __name__ == '__main__':
download(url,3)
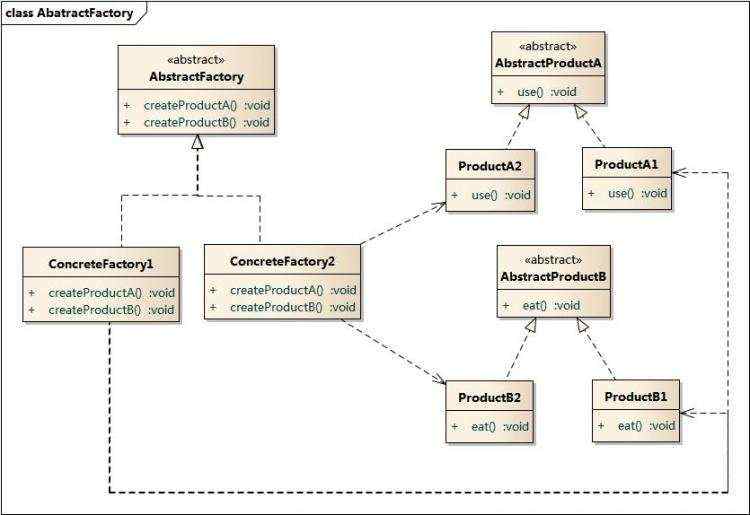
爬虫的套路
下载页面
深度,广度访问站点 链接爬虫
解析,抓取数据
性能分析
缓存优化
数据存储
验证COOKIE
验证码
邮箱验证,手机验证
爬虫陷阱
windows python3.6 SublimeText3
import urllib
urllib.request.urlopen()
urlopen 函数就是打开网页
HTTPs http ftp等协议
urlopen函数来处理
urlopen(url,data, timeout,ca…)
超时
url uri
post 提交
get 获取
返回:
Response
read() 返回一个链接的对应HTML源码
解码 decode() 脱掉衣服
编码 encode() 穿上衣服
#utf-8 utf-16
#处理中文
#gbk gb2312
info() 可以获取相应
getcode() 返回Http状态码
geturl() 返回访问的页面地址
HTTPError
处理错误码
400-500 不管
500-600 尝试重新下载
4xx 没有机会挽救了
404 服务器没有这个页面
403 服务器内部错误
401 没权限
5xx 可以挽救的
500 服务器内部错误
503 服务暂不可用
3xx
服务器重定向
200
服务器正常返回
urllib.error
urllib.error.HTTPError:HTTP Error 500: Internal Server Error
urllib.error.URLError:
错误大致分成了两种
URLError
- 本机没网
- 服务器压根不存在
- 被墙了



 京公网安备 11010802041100号
京公网安备 11010802041100号