前言
要想确保品牌之下统一的口感和定制化的茶饮口味服务,在这背后就少不了中台系统的强大算力。数字化中台是聚焦连接前台业务和后台 ERP 基干系统,建立以用户为中心的现代商业中最核心竞争力:敏捷的用户响应力。
业务中台建设就是帮助零售客户解决全渠道整合交易不通和数据不准,以及各种供应链之间连接不灵活的问题。
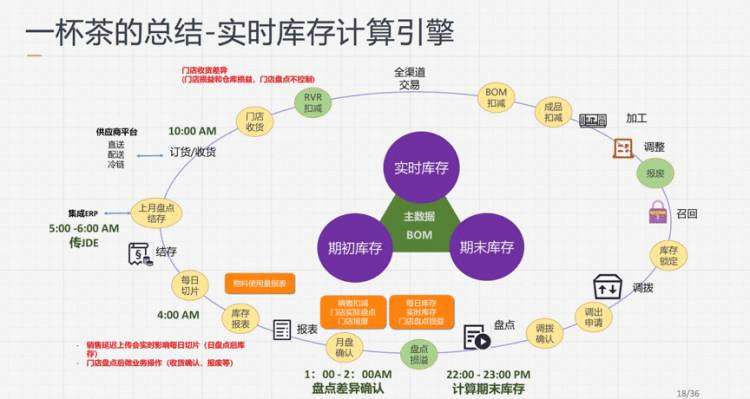
一杯茶的背后:
动态配方计算 & 实时库存扣减
一杯茶复杂的意义:
全渠道订单履约 & 商业协同
合阔在大数据场景下的数据库历程
第一阶段:数据库上云
第二阶段:热数据冷数据
第三阶段:Mongo/ElasticSearch
第四阶段:Greenplum
胜利的曙光:Kyligence
业务数据库使用的是 OLTP 型数据库,为了查询快使用了很多的索引,导致整体存储占用比较高
Kyligence 使用的是 Hive 数据源云 BLOB 存储,数据压缩存放,而且CUBE构建后的数据远远小于 OLTP 型数据库索引。
未来计划
关于合阔智云
合阔智云(Hex Cloud)是一家专注于为大中型零售连锁行业提供全渠道业务中/前台产品和解决方案,通过合阔智云系列产品、数据分析和智能引擎帮助零售企业敏捷响应客户需求和持续提升零售运营效率,建立以消费者为中心的全渠道交易和敏捷供应链的新一代零售运营协同平台。
点击“阅读原文”下载 PPT















 京公网安备 11010802041100号
京公网安备 11010802041100号