时间:2020年8月5日09:51:45
一、mysql优化概述
页面静态化的内容,memcache,减少数据库的访问,提高网站的访问速度,无论如何优化,还是要操作数据库的,要从数据库的角度来优化,提高访问速度。
设计角度:存储引擎的选择,字段类型选择,范式
利用mysql自身的特性:索引,查询缓存,分区分表,存储过程,sql语句优化配置,
部署大负载架构体系:主从复制,读写分离。
硬件升级:
二、分析需要优化的语句
要 查找执行速度比较慢的sql语句,
1、使用mysql里面的 慢查询日志,
慢查询日志,是由mysql提供的,用于记录sql执行时间超过了某个时间界限,该时间界限我们可以自己设定,比如我们设定的时间界限为0.5秒,开启慢查询日志后,会自动记录执行时间超过0.5秒的sql语句。慢查询日志默认没有开启,默认的时间界限是10秒。
(1)如何开启慢查询日志,
方式一:打开mysql的配置文件,my.ini,添加如下语句:修改完成后,要重启mysql服务


(2)开始测试,是否记录执行时间超过0.5秒 的sql语句。
select benchmark(执行次数,表达式);

在慢查询日志文件里面查看是否记录


2、使用profiles机制
该机制开启后,会记录每个sql语句的执行时间,精确到小数点后8位。
如果开启:set profiling=1|0 值为1则是开启,为0则是关闭。
查看sql语句的执行时间:show profiles

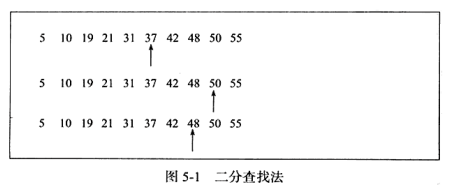
三、索引
索引:利用字段的某些属性,快速 的定位数据(磁盘,柱面,磁道,扇区)
1、索引 的类型
唯一索引(unique key):字段数据是唯一的,数据内容里面能否为null,在一张表里面,是可以添加多个唯一索引。
主键索引(primary key ):数据记录里面不能有null,数据内容不能重复,在一张表里面不能有多个主键索引。
普通索引(index ):使用字段关键字建立的索引,主要是提高查询速度。
全文索引(fulltext index):在比较老的版本中,只有myisam引擎支持全文索引,在最新的版本中(可能是mysql.5.6)innodb引擎也支持全文索引,在mysql中全文索引不支持中文。
2、如何创建索引
(1)在创建表的时候,同时创建索引,
create table stu(
id int primary key auto_increment,
name varchar(32) not null,
age tinyint unsigned not null,
email varchar(32) not null,
intro text,
unique key (name),
index (email),
fulltext index (intro)
)engine myisam charset utf8;
(2)在修改表的时候,添加索引
create table stu1(
id int primary key auto_increment,
name varchar(32) not null,
age tinyint unsigned not null,
email varchar(32) not null,
intro text
)engine myisam charset utf8;
alter table stu1 add unique key (name), add index (email), add fulltext index (intro);
3、删除索引
主键索引的删除,在删除主键 索引时,要删除到auto_increment属性,
alter table 表名 drop primary key
普通索引的删除:alter table 表名 drop index 索引名称 (如果索引名称没有指定则是索引的字段名称)
删除唯一索引:alter table 表名 drop index 索引名称
4、查询索引:
show index form 表名
show indexes from 表名
desc 表名,
show create table 表名
5、创建索引的注意事项
(1)较频繁的作为查询条件字段应该创建索引
select * from emp where empno = 1
唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
select * from emp where sex = '男‘
更新非常频繁的字段不适合创建索引
select * from emp where logincount = 1
(2)不会出现在WHERE子句中字段不该创建索
四、索引结构
查看索引的类型,是BTREE结构。


innodb索引的索引结构,innodb的索引叫聚簇索引。
innodb的主索引文件上 直接存放该行数据,称为聚簇索引,非主索引指向对主键的引用
注意: innodb来说,
1: 主键索引 既存储索引值,又在叶子中存储行的数据
2: 如果没有主键, 则会Unique key做主键
3: 如果没有unique,则系统生成一个内部的rowid做主键.
4: 像innodb中,主键的索引结构中,既存储了主键值,又存储了行数据,这种结构称为”聚簇索引”
在插入大量的数据的时候,造成频繁的页分裂.
五、explain(执行计划)工具的使用
主要用于分析sql语句的执行情况(并不执行sql语句)得到sql语句是否使用了索引,使用了哪些索引。
语法:explain sql语句\G 或 desc sql语句\G
在mysql之前的版本中,explain只支持select语句,但是在最新的5.6版本中,它支持 explain update/delete了。
建表完成测试:
create table user(
id int primary key auto_increment,
name varchar(32) not null default '',
age tinyint unsigned not null default 0,
email varchar(32) not null default '',
classid int not null default 1
)engine myisam charset utf8;
insert into user values(null,'xiaogang',12,'gang@sohu.com',4),
(null,'xiaohong',13,'hong@sohu.com',2),
(null,'xiaolong',31,'long@sohu.com',2),
(null,'xiaofeng',22,'feng@sohu.com',3),
(null,'xiaogui',42,'gui@sohu.com',3);
创建一个班级表:
create table class(
id int not null default 0,
classname varchar(32) not null default ''
)engine myisam charset utf8;
insert into class values(1,'java'),(2,'.net'),(3,'php'),(4,'c++'),(5,'ios');

六、使用执行计划,完成sql语句索引执行情况查询;
复合索引,有多列组合成一个索引。比如如下,建立一个name和age的一个复合索引。
mysql> alter table user add index (name,age);
Query OK, 5 rows affected (0.05 sec)
Records: 5 Duplicates: 0 Warnings: 0
1、多列索引:
(1)对于创建的多列(复合)索引,只要查询条件使用了最左边的列,索引一般就会被使用。
因为组合索引是需要按顺序执行的,比如c1234组合索引,要想在c2上使用索引,必须先在c1上使用索引,要想在c3上使用索引,必须先在c2上使用索引,依此。

2、对于使用like的查询,查询如果是”%aaa”,不会使用到索引,‘aaa%’会使用到索引。
比如:根据电影的剧情查找电影的名称,根据歌词查找歌名。like ‘%爱请%’
可以使用第三方查询工具,sphinx
3、如果条件中有or,则要求or的索引字段都必须有索引,否则不能用到索引。

4、如果列类型是字符串,一定要在条件中将数据使用引号引用起来,否则不使用索引。
5、优化group by语句。
默认情况下, mysql对所有的group by col1,col2进行排序。这与在查询中指定order by col1,col2类型,如果查询中包括group by 但用户想要避免排序结果的消耗,则可以使用order by null禁止排序。
6、当取出的数据量超过表中数据的20%,优化器就不会使用索引,而是全表扫描。
七、索引覆盖
索引覆盖是指:如果查询的列恰好是索引的一部分,那么查询只需要在索引文件上进行,不需要回行到磁盘再找数据,这种查询速度非常快,称为“索引覆盖”
案例1,如下对name字段添加了普通索引,要查询name字段信息

八、前缀索引,
利用字段数据的前部分作为索引,称为前缀索引。减少索引长度,提高索引效率。
比如:统计密码的前7个字符,作为不相同匹配条件,几乎可以做到1:1
此时,就可以利用前7个字符做索引关键字即可(离散程度高)

九、翻页优化
翻页的sql语句:
select * from table_name limit offset N
使用如上语句,在翻页时,翻到最后,越来越慢,
原因:并不是跨过offset行,取出n条,
是取出offset+N条数据,舍弃前面的offset行,只取出n条数据。

如何解决?
(1)从业务上去解决:
办法:不允许翻过100页,
以百度为例,一般翻页到70页左右,谷歌40页左右
(2)不用offset,用条件查询,条件中使用id查询,使用到了索引,
select * from user limit 10000,10;
select * from user where id>10000 limit 10;
下一页:select * from user where id>10000+10 limit 10
该种方式要注意:如果有数据被删除,会导致select * from user limit 10000,10;
和select * from user where id>10000 limit 10;语句取出的结果不一样,。
(3)假如不能使用限制翻页到100页,数据有删除,还要求翻页,速度不能受影响。
思路:通过翻页,先取出id(主键),在根据id取出数据。
select name,age,email from user inner join (select id from user limit 10000,10) as tmp on tmp.id=user.id
非要物理删除,还要用offset精确查询,还不限制用户分页,怎么办
我们现在必须要查,则只查索引,不查数据,得到id
再用id去查具体条目,这种技巧就是延迟索引。
十、碎片整理
比如建表测试:

当delete from ceshi where id=1,应该容量减去三分之一,但是并没有被删除。
需要把里面的一些碎片给释放掉。
使用optimize table 表名;或alter table 表名 engine myisam(innodb)
执行optimize table 表名,命令后,把原来的碎片空间给释放掉

注意:修复表的数据及索引碎片,就会把所有的数据文件重新整理一遍,使之对齐,这个过程,如果表的行数比较大,也是比较耗费资源的操作,所以,不能频繁的修复。
如果表的update操作很频繁,可以按周月来修复
十一、锁机制讲解
场景:
下订单:
库存 为100,买一件:
(1)取出库存的数量 100
(2)库存减去1 99
(3)把剩余的库存再写入到表里面。 99
如果是两个人同时操作:
刘备:
100-1=99
99
曹操:
100-1=99
99
锁机制,
mysql 的锁有以下几种形式:
表级锁:开销小,加锁快,发生锁冲突的概率最高,并发度最低。myisam引擎属于这种类型。
行级锁:开销大,加锁慢,发生锁冲突的概率最低,并发度也最高。innodb属于这种类型。
1、表锁的演示:
对myisam表的读操作(加读锁),不会阻塞其他进程对同一表的读请求,但会阻塞对同一表的写请求。只有当读锁释放后,才会执行其他进程的操作。
对myisam表的写操作(加写锁),会阻塞其他进程对同一表的读和写操作,只有当写锁释放后,才会执行其他进程的读写操作。
read:所有人都只可以读,只有释放锁之后才可以写。
write:只有锁表的客户可以操作这个表,其他客户读都不能读。
语法:
lock table 表名 read|write,
解锁:
unlock table
读锁的演示:

要注意:对表添加锁定后,只能操作锁定的表,如果想要操作其他表,则可以在锁定表时,一次性锁定多张表。语法:lock table 表1 read,表2 read;
2、行锁的演示:
是innodb支持的一种锁,在使用时,要添加条件限制是要操作哪行数据。
语法:
begin;
执行语句;
commit;
文件锁,flock_file
十二、分区分表技术
基本概念,把一个表,从逻辑上分成多个区域,便于存储数据。
采用分区的前提:数据量非常大。

1、分区类型:
list :条件值为一个数据列表。
通过预定义的列表的值来对数据进行分割
例子:假如你创建一个如下的一个表,该表保存有全国20家分公司的职员记录,这20家分公司的编号从1到20.而这20家分公司分布在全国5个区域,如下表所示:
职员表:
id name store_id(分公司的id)
北部 1,4,5,6,17,18
南部 2,7,9,10,11,13
东部 3,12,19,20
西部 8,14,15,16
id name store_id(分公司的id)
1 李小龙 3
2 大刀王五 8
北部 1,4,5,6,17,18
南部 2,7,9,10,11,13
东部 3,12,19,20
西部 8,14,15,16
create table emp(
id int,
name varchar(32),
store_id int
)engine myisam charset utf8
partition by list (store_id)(
partition p_north values in (1,4,5,6,17,18),
partition p_east values in(2,7,9,10,11,13),
partition p_south values in(3,12,19,20),
partition p_west values in(8,14,15,16)
);


====================================================================================
2020年8月5日15:51:51 原创发布。







 京公网安备 11010802041100号
京公网安备 11010802041100号