作者:回忆回忆194567 | 来源:互联网 | 2023-09-04 17:34
搜索了很久也没有找到批量识别海量pdf文件的方法,结果在adobe的官方找到了“动作”
这个功能。
adobe acrobat pro是全世界最好的识别中文的软件,没有之一。
走的弯路比如用myocrpdf,命令行进行识别,效果比前者还是差(如下图),但是基本可用。

但前者不支持命令行,也没找到调用的API。
用automate自动操作程序?或appscript模拟点击按钮?
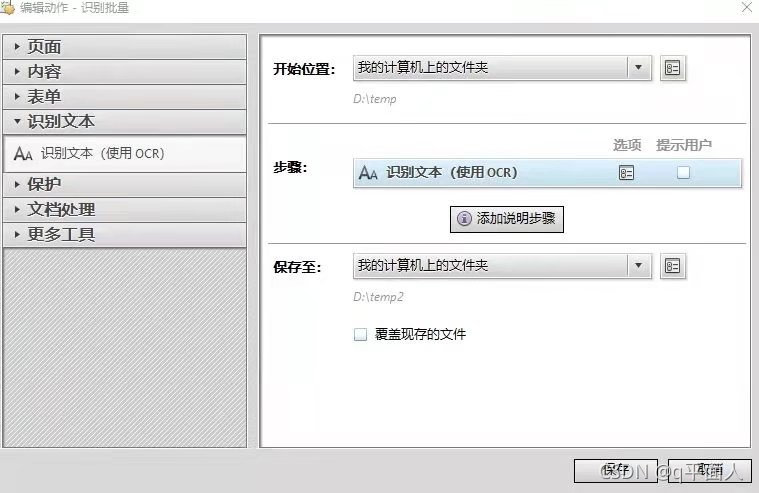
用adobe acrobat pro的“动作”,如下图去设置即可。设置好动作,文件夹内的所有pdf都会识别,保存到另外一个文件夹了。




 京公网安备 11010802041100号
京公网安备 11010802041100号