As usual I’m going to be profiling on my machine that has the following specs:
So let’s begin by looking at the profile. Just like last time this is profiling from frame two the first 1000 frames on the Elemental demo.
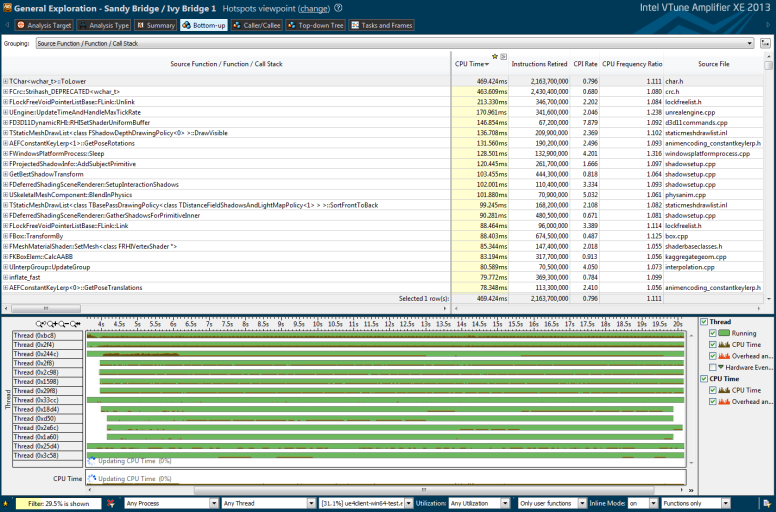
As you can see a lot of time is being spent on the ToLower() function, something I already optimized but it wasn’t included on this profile because I profile change by change on its own. So the approach this time is to reduce the number of calls to the function. So looking at the callstacks I found out that a lot of the calls were coming from the AsyncIOSystem thread.
As the name says the AsyncIOSystem is an asynchronous IO system. It is cross-platform and single-threaded runnable. What is a runnable on Unreal Engine 4 you ask, here is the answer:
/** * Interface for "runnable" objects. * * A runnable object is an object that is "run" on an arbitrary thread. The call usage pattern is * Init(), Run(), Exit(). The thread that is going to "run" this object always uses those calling * semantics. It does this on the thread that is created so that any thread specific uses (TLS, etc.) * are available in the contexts of those calls. A "runnable" does all initialization in Init(). * * If initialization fails, the thread stops execution and returns an error code. If it succeeds, * Run() is called where the real threaded work is done. Upon completion, Exit() is called to allow * correct clean up. */
New IO requests can be queue up from any thread where and those requests can be cancelled as well. Whenever a new request is sent the following data is stored in the given order:
| Type | Name | Description |
| uint64 | RequestIndex | Index of the request. |
| int32 | FileSortKey | NOT USED. File sort key on media, INDEX_NONE if not supported or unknown. |
| FString | FileName | Name of file. |
| int64 | Offset | Offset into file. |
| int64 | Size | Size in bytes of data to read. |
| int64 | UncompressedSize | Uncompressed size in bytes of original data, 0 if data is not compressed on disc. |
| void* | Dest | Pointer to memory region used to read data into. |
| ECompressionFlags | CompressionFlags | Flags for controlling decompression. Valid flags are no compression, zlib compression, and specific flags related to zlib compression |
| FThreadSafeCounter* | Counter | Thread safe counter that is decremented once work is done. |
| EAsyncIOPriority | Priority | Priority of request. Allows minimum, low, below normal, normal, high, and maximum priority. |
| uint32 | bIsDestroyHandleRequest : 1 | True if this is a request to destroy the handle. |
| uint32 | bHasAlreadyRequestedHandleToBeCached : 1 | True if the caching of the handle was already requested. |
So the most obvious culprit of the performance drain must be the FileName. So let’s look at where it is used:
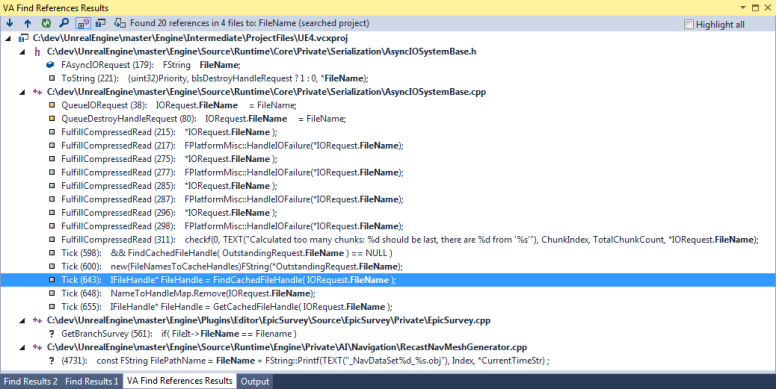
The use in the Tick function caught my attention right away, it lined up properly with the callstack that I knew was flooding my output window. The Tick function of FAsyncIOSystem does the following things in order:
- Create file handles for the outstanding requests.
- Creates a copy of the next request that should be handled based on a specific platform criteria such as the layout on disc or the highest set priority.
- Fulfill the pending request.
- Which can be a request to destroy the handle or retrieve/create a handle to fulfill a a compressed or uncompressed read.
To determine if a request handle needs to be created or retrieved from the cache there is a name to handle map that maps the FString of the name of an iFileHandle*. If the filename is in the map then it means that there is a cached handle for it. To do that it does a FindRef() on the TMap which calls FindId(), here is the code:
/**
* Finds an element with the given key in the set.
* @param Key - The key to search for.
* @return The id of the set element matching the given key, or the NULL id if none matches.
*/
FSetElementId FindId(KeyInitType Key) const
{
if(HashSize)
{
for(FSetElementId ElementId = GetTypedHash(KeyFuncs::GetKeyHash(Key));
ElementId.IsValidId();
ElementId = Elements[ElementId].HashNextId)
{
if(KeyFuncs::Matches(KeyFuncs::GetSetKey(Elements[ElementId].Value),Key))
{
// Return the first match, regardless of whether the set has multiple matches for the key or not.
return ElementId;
}
}
}
return FSetElementId();
}
The ElementId is generated by the GetTypedHash() function which for our type it generates a CRC32 hash, this is where all the time in FCrc::Strihash_DEPRECATED
static FORCEINLINE bool Matches(KeyInitType A,KeyInitType B)
{
return A == B;
}
While that looks pretty reasonable for fundamental integral types, for comparisons of FStrings it does a call to Stricmp to do a lexicographical comparison. This is where the ToLower() call is made:
templatestatic inline int32 Stricmp( const CharType* String1, const CharType* String2 ) { // walk the strings, comparing them case insensitively for (; *String1 || *String2; String1++, String2++) { CharType Char1 = TChar ::ToLower(*String1), Char2 = TChar ::ToLower(*String2); if (Char1 != Char2) { return Char1 - Char2; } } return 0; }
So now we know what it implies to find something in the cache, but how often does that happen? The answer is in the FAsyncIOSystemBase::Tick() function which shows that it happens once per outstanding request, and then once more when a request if a request is pending. I measured the number of request done before the very first frame was rendered, there were 2096 requests queued. Considering that the AsyncIOSystem thread has an above normal priority and it can happen pretty often. The numbers add up pretty quickly. We need to fix this.
To fix this I took a rather simple approach which is to make sure that finding something in the cache involves comparisons between integral types. The easiest way was to add another field to the IO request data which is a 32-bit hash of the filename. The hash is generated whenever a new IO request is queued up (be it an IO request or a file handle destroy request), and then that hash is used to find cached file handles. To generate the hash I decided to use something already found in the engine rather than integrating something like FNV-1 or xxHash, so I used a CRC32 hash.
So after doing that change let’s look at the profile:
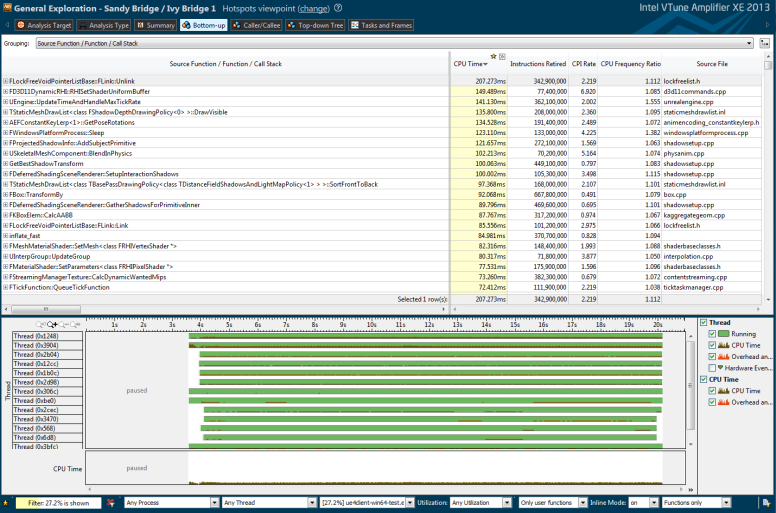
Pretty impressive, the call to ToLower() isn’t there anymore because only 0.030ms are spent in all the 1000 frames. The call to FCrc::Strihash_DEPRECATED
The lessons this time is related to the tendency of developers to hide complexity under very generic functions which have huge performance relevance. In particular performance was suboptimal because of it isn’t obvious that a A == B in KeyFuncs::Matches would imply a Stricmp call for an FString. That’s why in my own code I tend not to override operators, they usually hide complexity when as programmers we need to be fully aware of the complexity of what we ship. Programmers also forget that our main objective isn’t to create generic solutions that solve problems that we may have in the future. Our main objective is to ship the best experience to the end user, and that means writing code that solve the actual problem we need to solve, with the available hardware resources, and with the available time to write it. If you care a lot about the future of your code then worry about making optimizable code rather that making a grand design to abstract complexities using ten different design patterns. The truth is that the end user doesn’t care if you use 10 different patterns in a generic design, but they do care if the load times are high.
And knowing your performance data is critical. In the case of the Elemental demo 2096 IO requests were done and fulfilled before the first frame was rendered. I think being aware of that is critical to making the proper design and performance decisions. In fact given that data I would be inclined to further optimize this by changing the AoS nature of the FAsyncIORequest and move it to a SoA so that hashes are all stored together to optimize to reduce the CPI in the Tick function, but I will leave that up to you.

![扫描线三巨头 hdu1928hdu 1255 hdu 1542 [POJ 1151]](https://img.php1.cn/3c972/245b5/42f/19446f78530d3747.jpeg)

 京公网安备 11010802041100号
京公网安备 11010802041100号