众所周知,OpenCV中的Adaboost级联分类是树状结构,如图1,其中每一个stage都代表一级强分类器。当检测窗口通过所有的强分类器时才被认为是目标,否则拒绝。实际上,不仅强分类器是树状结构,强分类器中的每一个弱分类器也是树状结构。
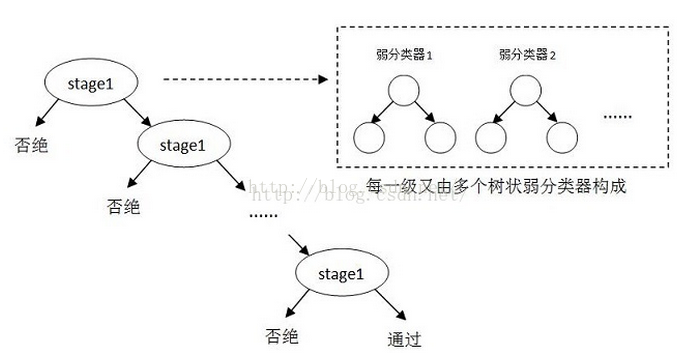

图1 强分类器和弱分类器示意图
这篇文章将结合OpenCV-2.4.11中自带的haarcascade_frontalface_alt2.xml文件介绍整个级联分类器的结构。需要说明,自从2.4.11版本后所有存储得XML分类器都被替换成新式XML,所以本文对应介绍新式分类器结构。
(一)XML的头部
在了解OpenCV分类器结构之前,先来看看存储分类器的XML文件中有什么。图2中注释了分类器XML文件头部信息,括号中的参数为opencv_traincascade.exe训练程序对应参数,即训练时设置了多少生成的XML文件对应值就是多少(如果不明白,可以参考我的前一篇文章)。
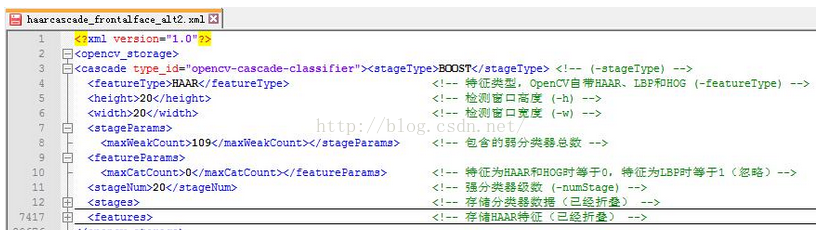
图2 分类器XML文件头部含义
(二)弱分类器结构
之前看到有一部分文章将Haar特征和弱分类器的关系没有说清楚,甚至有些还把二者弄混了。其实Haar特征和弱分类器之间的关系很简单:
一个完整的弱分类器包含:Haar特征
+leftValue + rightValue + 弱分类器阈值(threshold)
这些元素共同构成了弱分类器,缺一不可。haarcascade_frontalface_alt2.xml的弱分类器深度为2,包含了2种形式,如图3。图3中的左边形式包含2个Haar特征、1个leftValue、2个rightValue和2个弱分类器阈(t1和t2);左边形式包括2个Haar特征、2个leftValue、1个rightValue和2个弱分类器阈。
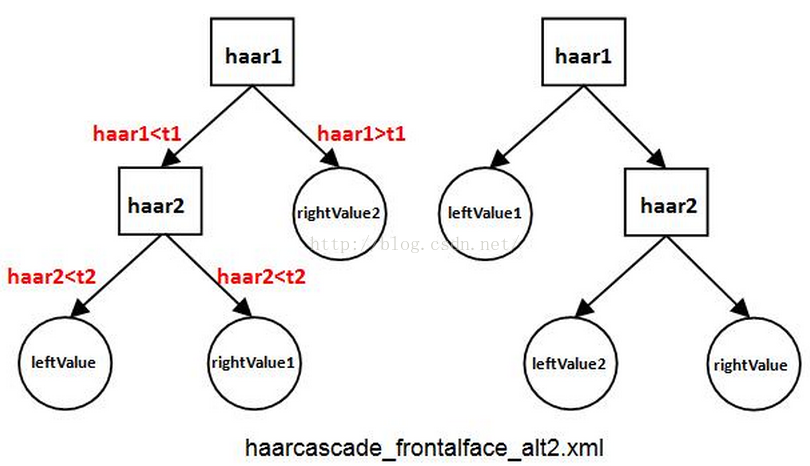
图3 OpenCV树状弱分类器示意图
看图3应该明白了弱分类器的大致结构,接下来我们了解树状弱分类器是如何工作的。还是以图3左边的形式为例:
1.计算第一个Haar特征的特征值haar1,与第一个弱分类器阈值t1对比,当haar1t1时,该弱分类器输出rightValue2并结束。
2.计算第二个Haar特征值haar2,与第二个弱分类器阈值t2对比,当haar2t2时输出rightValue1。
即通过上述步骤计算弱分类器输出值,这与OpenCV的cascadedetect.hpp文件中的predictOrdered()函数代码对应(这里简单解释一下,在OpenCV中所有弱分类器的leftValue和rightValue都依次存储在一个一维数组中,代码中的leafOfs表示当前弱分类器中leftValue和rightValue在该数组中存储位置的偏移量,idx表示在偏移量leafOfs基础上的leftValue和rightValue值的索引,cascadeLeaves[leafOfs
-idx]就是该弱分类器的输出):
- do
- {
- CascadeClassifier::Data::DTreeNode& node = cascadeNodes[root + idx];
- double val =featureEvaluator(node.featureIdx);
- idx &#61; val < node.threshold ?node.left : node.right;
- }
- while( idx > 0 );
- sum &#43;&#61; cascadeLeaves[leafOfs -idx];
看到这里&#xff0c;你应该明白了弱分类器的工作方式&#xff0c;即通过计算出的Haar特征值与弱分类器阈值对比&#xff0c;从而选择最终输出leftValue和rightValue值中的哪一个。
那么第三个问题来了&#xff0c;这些Haar特征、leftValue、rightValue和弱分类器阈值t都是如何存储在xml文件中的&#xff1f;不妨来看haarcascade_frontalface_alt2.xml文件中的第一级的第三个弱分类器&#xff0c;如图4。图4中的弱分类器恰好是图3中左边类型&#xff0c;包含了和两个标签。其中标签中的3个浮点数由左向右依次是rightValue2、leftValue和rightValue1&#xff08;具体顺序参考下文图示&#xff09;&#xff1b;而中有6个整数和2个浮点数&#xff0c;其中2个浮点数依次分别是弱分类器阈值t1和t2&#xff0c;剩下的6个整数容我慢慢分解。
首先来看两个浮点数前的整数&#xff0c;即4和5。这两个整数用于标示所属本弱分类器Haar特征存储在标签中的位置。比如数值4表示该弱分类器的haar1特征存储在xml文件下面标签中第4个位置&#xff0c;即为&#xff1a;
&#xff08;标签里面的5个数对应Haar特征的&#xff0c;请参考上一篇文章&#xff09;。的其他4个整数1、0、-1和-2则用于控制弱分类器树的形状&#xff0c;即OpenCV会把1赋值给当前的node.left&#xff0c;并把0赋值给node.right。请注意do-while代码中的条件&#xff0c;只有idx<&#61;0时才停止循环&#xff0c;参考图3应该可以理解这4个整数的含义。如此&#xff0c;OpenCV通过这些巧妙的数值和结构&#xff0c;控制了整个分类器的运行&#xff08;当然我举的例子alt2的弱分类器树深度为2&#xff0c;相对比较复杂&#xff0c;其他如alt等深度为1的分类器则更加简单&#xff09;。其他弱分类器请类推。

图4 OpenCV弱分类器运行示意图
可以看到&#xff0c;每个弱分类器内部都是类似于这种树状的“串联”结构&#xff0c;所以我称其为“串联组成的的弱分类器”。&#xff08;需要说明&#xff0c;本文为了介绍原理&#xff0c;选用了深度为2的分类器。而深度为1的分类器&#xff0c;如haarcascade_frontalface_alt.xml&#xff0c;则相比较简单&#xff0c;可以通过类比了解&#xff0c;不再赘述&#xff09;&#xfeff;&#xfeff;
&#xff08;三&#xff09;强分类器结构
在OpenCV中&#xff0c;强分类器是由多个弱分类器“并列”构成&#xff0c;即强分类器中的弱分类器是两两相互独立的。在检测目标时&#xff0c;每个弱分类器独立运行并输出cascadeLeaves[leafOfs
-idx]值&#xff0c;然后把当前强分类器中每一个弱分类器的输出值相加&#xff0c;即&#xff1a;
sum&#43;&#61; cascadeLeaves[leafOfs - idx];&#xfeff;&#xfeff;
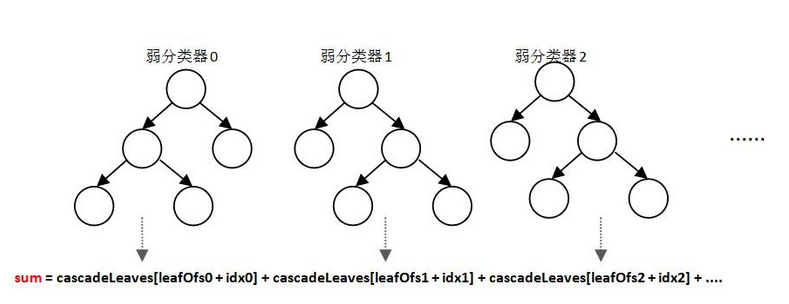
图5 OpenCV强分类器运行示意图
之后与本级强分类器的stageThreshold阈值对比&#xff0c;当且仅当结果sum>stageThreshold时&#xff0c;认为当前检测窗口通过了该级强分类器。当前检测窗口通过所有强分类器时&#xff0c;才被认为是一个检测目标。
可以看出&#xff0c;强分类器与弱分类器结构不同&#xff0c;是一种类似于“并联”的结构&#xff0c;我称其为“并联组成的强分类器”。
&#xff08;四&#xff09;级联分类器
通过之前的介绍&#xff0c;到这应该可以理解OpenCV中&#xff1a;由弱分类器“并联”组成强分类器&#xff0c;而由强分类器“串联”组成级联分类器。那么还剩最后一个内容&#xff0c;那就是检测窗口大小固定&#xff08;例如alt2是20*20像素&#xff09;的级联分类器如何遍历图像&#xff0c;以便找到在图像中大小不同、位置不同的目标。
1. 为了找到图像中不同位置的目标&#xff0c;需要逐次移动检测窗口&#xff08;随着检测窗口的移动&#xff0c;窗口中的Haar特征相应也随着窗口移动&#xff09;&#xff0c;这样就可以遍历到图像中的每一个位置&#xff1b;
2. 而为了检测到不同大小的目标&#xff0c;一般有两种做法&#xff1a;逐步缩小图像or逐步放大检测窗口。缩小图像就是把图像长宽同时按照一定比例&#xff08;默认1.1 or 1.2&#xff09;逐步缩小&#xff0c;然后检测&#xff1b;放大检测窗口是把检测窗口长宽按照一定比例逐步放大&#xff0c;这时位于检测窗口内的Haar特征也会对应放大&#xff0c;然后检测。一般来说&#xff0c;如果用软件实现算法&#xff0c;则放大检测窗口相比运行速度更快。




![[大整数乘法] java代码实现](https://img1.php1.cn/3cd4a/24c6f/9f3/0133bb25da242824.jpeg)






 京公网安备 11010802041100号
京公网安备 11010802041100号