识别效果图依赖安装opencv-pythonopencv-contrib-pythontensorflowPillownumpypip3installopencv-python4
识别效果图

依赖安装 opencv-python opencv-contrib-python tensorflow Pillow numpy
pip3 install opencv-python==4.5.1.48 -i https://pypi.tuna.tsinghua.edu.cn/simple --default-timeout=10000
pip3 install opencv-contrib-python==4.5.1.48 -i https://pypi.tuna.tsinghua.edu.cn/simple --default-timeout=10000
pip3 install tensorflow==2.4.1 -i https://pypi.tuna.tsinghua.edu.cn/simple --default-timeout=10000
pip3 install -U pillow==8.1.2
pip3 install numpy==1.19.4 -i https://pypi.tuna.tsinghua.edu.cn/simple --default-timeout=10000
头像目标锁定资源文件 haarcascade_frontalface_default.xml 如果觉得慢,可以从 csdn 资源中下载
项目结构
采集数据 collection.py 采集完成之后可以通过肉眼删除误差较大的数据
# 头像数据采集
import cv2 as cv
import uuid# 数据集收集
def split_image(frame, set_path):# 图片转灰度frame_gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)# 加载人脸分类识别器face_detector = cv.CascadeClassifier(r'../data/haarcascade_frontalface_default.xml')faces = face_detector.detectMultiScale(frame_gray)for x, y, w, h in faces:# 头像标注# cv.rectangle(frame, (x, y), (x + w, y + h), color=(0, 255, 0), thickness=1)# 头像切割保存,分类型保存 frame_gray 为灰度图片 frame 为原始图片,选择灰度图片作为训练集cv.imwrite(set_path + str(uuid.uuid1()) + '.jpg', frame_gray[y:y + h, x:x + w])if __name__ == '__main__':# 数据保存路径,不能有中文set_path = "C:/Users/Administrator/Desktop/data"label = 0 # 当前数据的标签stream_address = "../data/one.mp4" # 读取视频文件# stream_address = 0;//获取摄像头stream = cv.VideoCapture(stream_address) # 转化为流set_path = set_path + "/" + labelwhile True:status, frame = stream.read() # 读取帧图片数据if status:print("获取到图片数据,规格为:", frame.shape)else:print('没有检查到图像数据')breaksplit_image(frame, set_path) # 截取头部数据信息cv.destroyAllWindows()stream.release()
训练模型 train.py
# 训练模型
import numpy as np
from PIL import Image
import cv2 as cv
import os# 加载训练数据
def get_train_data(data_path, image_width, image_high):train_data_array = [] # 训练集,灰度图片label_array = [] # 标签 必须是整数,数值型从0开始包括0,后续识别可以通过标签索引获取数组字典,数组从0开始listdir = os.listdir(data_path)for label in listdir:label_path = data_path + "/" + labelfiles = os.listdir(label_path)for file_name in files:file_path = label_path + "/" + file_nameimg_numpy = np.array(Image.open(file_path).convert('L'), 'uint8')img_format = cv.resize(img_numpy, (image_width, image_high), interpolation=cv.INTER_CUBIC) # 图片大小格式化train_data_array.append(img_format)label_array.append(int(label))return label_array, train_data_array# 训练模型
def training():print("人脸训练中 ...")data_path = "C:/Users/Administrator/Desktop/data" # 训练数据路径label_array, train_data_array = get_train_data(data_path, 128, 128) # 指定图片格式化大小# 创建LBPH识别器并开始训练,当然也可以选择Eigen或者Fisher识别器recognizer = cv.face.LBPHFaceRecognizer_create()# 传入训练集与标签recognizer.train(train_data_array, np.array(label_array))# 保存训练信息recognizer.write('../model/trainer.yml')print("{0} 训练分类数为2,已完成".format(len(np.unique(label_array))))if __name__ == '__main__':training()
视频识别 distinguish.py
# 识别
import cv2 as cvdef distinguish():# 加载算法 创建LBPH识别器并开始识别,当然也可以选择Eigen或者Fisher识别器recognizer = cv.face.LBPHFaceRecognizer_create()# 加载模型recognizer.read('../model/trainer.yml')face_detector = cv.CascadeClassifier(r"../data/haarcascade_frontalface_default.xml")font = cv.FONT_HERSHEY_SIMPLEX# 特征值对应的姓名映射names = ['one', 'two']cap = cv.VideoCapture("../data/one.mp4") # 加载视频文件数据# cap = cv.VideoCapture(0) # 加载摄像头数据while True:status, frame = cap.read()if status:print("获取到图片数据,规格为:", frame.shape)else:print('没有检查到图像数据')break# 图片转灰度frame_gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)faces = face_detector.detectMultiScale(frame_gray)for x, y, w, h in faces:cv.rectangle(frame, (x, y), (x + w, y + h), color=(0, 255, 0), thickness=1)# 识别feature_id, value = recognizer.predict(frame_gray[y:y + h, x:x + w])print("当前识别分类为", feature_id, "得分为", value)if value > 100:feature_id = "unknown"reliability = "100%"else:feature_id = names[feature_id] # 将识别的结果特征数值映射成姓名reliability = "{0}%".format(round(100 - value, 2))cv.putText(frame, str(feature_id), (x + 5, y - 5), font, 1, (0, 0, 255), 1)cv.putText(frame, str(reliability), (x + 5, y + h - 5), font, 1, (0, 255, 0), 1)cv.imshow("distinguish", frame)if ord('q') == cv.waitKey(10):breakcv.destroyAllWindows()cap.release()if __name__ == '__main__':distinguish()
采集头像数据示例

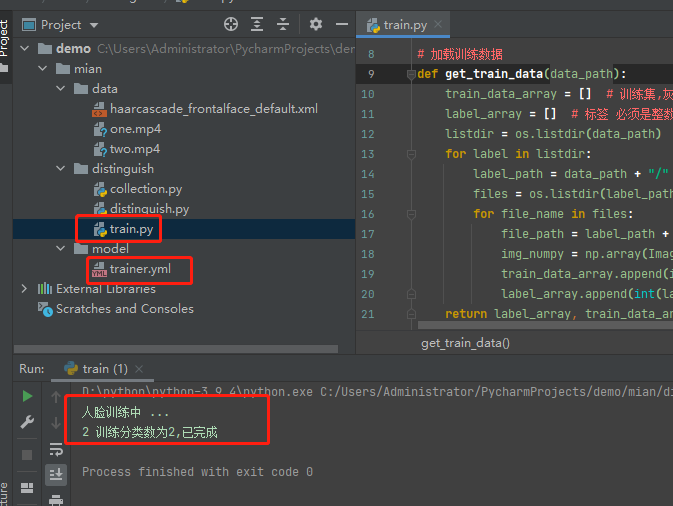
训练完之后会在mian/model目录下生成训练文件
校验模型的准确度 check.py
# 模型校验
import cv2 as cv
import os# 数据结构
class CheckResult:accuracy = 0 # 正确数error = 0 # 正确数unknown = 0 # 未知数total = 0 # 总数accuracy_list = [] # 正确详细数据error_list = [] # 错误详细数据unknown_list = [] # 未知详细数据accuracy_rate = None # 正确率error_rate = None # 错误率unknown_rate = None # 未知率accuracy_reliability = 0 # 正确平均可信度error_reliability = 0 # 错误平均可信度def msg(self):return "正确识别数:{0},正确率:{1},错误识别数:{2},错误率:{3},未知识别数:{4},未知率:{5},正确可信度:{6},错误可信度:{7}".format(self.accuracy,self.accuracy_rate,self.error,self.error_rate, self.unknown,self.unknown_rate,self.accuracy_reliability,self.error_reliability)# 加载校验数据
def get_test_data(data_path):# 加载算法 创建LBPH识别器并开始校验,当然也可以选择Eigen或者Fisher识别器recognizer = cv.face.LBPHFaceRecognizer_create() # 加载模型recognizer.read('../model/trainer.yml')face_detector = cv.CascadeClassifier(r"../data/haarcascade_frontalface_default.xml")test_data_array = [] # 校验集listdir = os.listdir(data_path)for label in listdir:label_path = data_path + "/" + labelfiles = os.listdir(label_path)for file_name in files:file_path = label_path + "/" + file_nameframe = cv.imread(file_path, 3)# 图片转灰度frame_gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)faces = face_detector.detectMultiScale(frame_gray)for x, y, w, h in faces:cv.rectangle(frame, (x, y), (x + w, y + h), color=(0, 255, 0), thickness=1)# 识别feature_id, value = recognizer.predict(frame_gray[y:y + h, x:x + w])if value > 100:feature_id = "unknown"reliability = 1else:reliability = 100 - valuetest_data_array.append({"path": file_path, "feature": feature_id, "reliability": reliability, "label": int(label)})return test_data_array# 校验模型
def calc_result(test_data_array):result = CheckResult()for x in test_data_array:if x["feature"] == x["label"]:result.accuracy += 1result.accuracy_list.append(x)result.accuracy_reliability += x["reliability"]elif x["feature"] == 'unknown':result.unknown += 1result.unknown_list.append(x)else:result.error += 1result.error_list.append(x)result.error_reliability += x["reliability"]result.total = len(test_data_array)if result.total == 0:result.accuracy_rate = "0.00%"result.error_rate = "0.00%"result.unknown_rate = "0.00%"else:result.accuracy_rate = str(round(result.accuracy * 100 / result.total, 2)) + "%"result.error_rate = str(round(result.error * 100 / result.total, 2)) + "%"result.unknown_rate = str(round(result.unknown * 100 / result.total, 2)) + "%"result.accuracy_reliability = str(round(result.accuracy_reliability / result.total, 2)) + "%"result.error_reliability = str(round(result.error_reliability / result.total, 2)) + "%"return resultdef checking():print("模型校验中 ...")data_path = "C:/Users/Administrator/Desktop/data" # 校验数据路径test_data_array = get_test_data(data_path)result = calc_result(test_data_array)print(result.msg())# 校验模型准确度
if __name__ == '__main__':checking()
校验结果










 京公网安备 11010802041100号
京公网安备 11010802041100号