1. 静态:网页内容任何人在任何时间访问都是不变的;
HTML/CSS/JS/Flash/视频音频....
2. 动态:网页内容不同人在不同时间访问可能是不同的;
JSP=HTML+Java:功能强大可靠,适合大型企业级项目。
PHP=HTML+PHP:简单易用,适合互联网项目。
ASP.NET=HTML+C#:易用,适合Windows平台。
Node.js=HTML+"JS":性能好,适合于服务器端IO密集型项目,不适合CPU密集型项目。
Node.js不是JS,是一种服务器端技术,它的竞争对手是PHP/JSP/ASP.NET,历史上第一次有一种语言可以通吃前后台!
1. 单线程逻辑处理;
2. 非阻塞;
3. 异步I/O处理;
4. 事件驱动编程;
1. 交互模式,一般用于临时测试;
REPL:Read Evaluate Print Loop,输入一行代码执行一行。
注意:交互模式自带输出功能,不必写console.log,在交互模式下,声明的全局变量是global的成员,全局污染严重。
node 回车
2. 脚本模式,正式项目中使用的方式;
把要执行的所有语句编写的一个文本文件中,一次性提交给node解释器执行,在脚本模式下,声明的全局变量不是global的成员,避免了全局对象的污染。
node 完整路径名/x.js 回车
提示:只要安装完Node.js,重启一下WebStorm,WS可以自动发现node.exe解释器程序,记得新建的项目一定要修改默认的文件编码方式为UTF-8。
Modal:模态框 Model:模型 Module:模块
一个Web项目功能可以分为很多不同的“模块”,如商品管理模块、用户管理模块、支付模块、促销模块、商家管理模块。
Node.js按照功能的不同,可以把函数、对象分处到不同的文件、目录下,这些文件目录在Node.js中就称为“Module“。
Node.js中每个模块都是一个独立构造函数,解释器会为每个.js文件添加如下代码:

每个模块都可以使用自己的require()函数引入另一个模块,底层本质就是创建了指定模块的一个对象实例。
require('./模块文件名');
每个模块可以使用exports对象向外导出/公开一些自己内部的成员供其它模块使用。
exports.成员名= 成员值;
二者都可以用于向外界导出自己内部的成员,但Node.js底层有代码:
exports = module.exports,所以真正导出的是module.exports。
module变量指代当前模块对象,未经封装的零散对象可以用exports导出,如exports.s=size,因为它只是给exports对象添加新成员,等价于给module.exports添加新成员,导入应用时不用实例化。
给封装的构造函数导出时必须用module.exports,如module.exports=circle,如果写成exports=circle则相当于修改了exports的指向,导出则不会产生实质的作用,使用构造函数导入应用时要用new实例化才能使用。
Node开发者建议导出对象用module.exports,导出多个方法和变量用exports。
1. Node.js官方提供的模块;
安装在解释器内部global、util、url、fs、http、querystring、Buffer。
2. 第三方编写的模块mysql、oracle、express;
3. 用户自定义的模块 , 文件模块和目录模块;
(1). 文件模块;
circle.js:exports.size = fn;
app.js: require('./circle');
(2). 目录模块;
node_modules/mysql/package.json: { "main":"./index.js" };
node_modules/mysql/index.js: exports.conn = fn;
app.js:require('mysql');
该模块可以直接使用,而无需引入。
1. exports:用于向外部导出当前模块内部的成员;
2. module:用于指代当前模块;
3. require:用于引入其他模块;
4. __filename:返回当前模块的文件全名;
5. __dirname:返回当前模块文件所在的目录全名;
6. console:指代控制台对象,注意该对象与Chrome中console不同;
7. setInterval( fn,time) :设置定时器;
8. setTimeout(fn,time) :设置延时定时器;
9. setImmediate(fn) :等价于setTimeout(fn,0);
1. 文件模块;
创建一个js文件,假设名为m3,导出需要公开的数据,其它模块可以require('./m3')模块;
2. 目录模块;
(1). 创建一个目录,假设名为m4,其中创建名为index.js的文件,导出需要公开的数据,其它模块可以require('./m4')模块;
(2). 创建一个目录,假设名为m5,其中创建package.json文件,其中声明main属性指定默认执行的启动js文件,如m5.js,其中导出需要公开的数据,其它模块可以require('./m5')模块;
(3). 创建一个目录,必须名为node_modules,其中再创建目录模块,假设名为module_6,其中创建package.json文件,其中声明main属性指定默认执行的启动js文件,如6.js,其中导出需要公开的数据,其它模块可以require('module_6')模块,导入时不用指定路径;
3. 模块查找的顺序;
(1). 文件/目录模块的缓存;
(2). 原生模块的缓存;
(3). 原生模块;
(4). 文件/目录模块;
Node Package Manager:Node.js的第三方模块/包管理器,可用于下载、更新、删除、维护包依赖关系的工具。
npm工具默认到 www.npmjs.org 网站下载所需的第三方模块包。
使用NPM工具下载一个新的软件包:
安装:cmd里定位要安装的目录下
npm install 包名(加-g会安装到默认npm下)。
卸载::cmd里定位要安装的目录下
npm uninstall 包名。
更多的NPM命令参数可以使用 npm -h 进行查看。
包是一个目录,它应该位于当前目录或者父目录下的node_modules文件夹下,引用时会由近及远依次查找,目录应遵循以下规范。
1. 目录中包含一个package.json(npm init)包说明文件,存放于包顶级目录下;
2. 目录中包含js文件,如有index.js,可以放到包顶级目录下,其它js文件,放到lib目录下;
3. 二进制文件放到bin目录下;
4. 文档放到doc目录下;
5. 单元测试文件放到test目录下;
该模块用于处理HTTP请求URL中的查询字符串。
1. qs.parse(str) ,把查询字符串解析为JS对象;
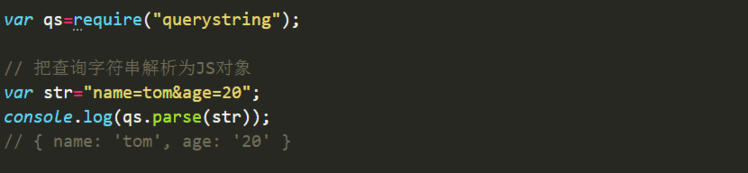
2. qs.stringify(obj) ,把JS对象转换为查询字符串,参数1为一个数据对象,可选参数2指定键值对之间的分隔符,默认为&,可选参数3指定键和值之间的分隔符;

该模块用于解析一个HTTP请求地址,获取其中各个不同的部分。
1. url.parse( str ) , 把一个URL字符串解析为一个对象;

2. url.parse( str, true ) ,把一个URL字符串解析为一个对象,并把其中的查询字符串也解析为对象;

3. url.format( obj ) ,把对象反向格式化为url格式;

4. url.resolve( str1,str2 ), 根据基地址和相对地址,解析出目标地址,参数1为基地址,参数2为相对地址;

该模块提供了对文件路径进行相关操作的方法。
1. path.parse( str ) ,解析一个路径为对象;

2. path.format( obj ) ,解析一个对象为路径;

3. path.join(str1 ,str2,str3…)使用当前系统路径分隔符连接路径(字符串);

4. path.resolve(str1,str2)根据第一个基础路径(字符串),基础路径不能有文件名,解析第二个目标路径(字符串)的绝对路径,第二个目标路径含有文件名;

5. path.relative(str1,str2)根据第一个基础路径(字符串),基础路径不能有文件名,获取第二个目标路径(字符串)与其相对路径, 第二个目标路径含有文件名;

该模块提供了域名和IP地址的双向解析功能。
1. lookup(“域名”,fn(err,address,family ){}),把一个域名解析成一个IP地址,从操作系统缓存查询;

2. resolve(“域名”,fn(err,address){}),把一个域名解析为一个DNS的记录解析数组,从DNS服务器中查询;

3. reverse(“IP地址”,fn(err,hostnames){}),把一个ip地址反向解析为一个域名(国内网络执行效果不好);

1. format( “名称:%s,价格:%d,%j”, obj.name,obj.price, obj ) ;
使用带占位符的方式格式化字符串(%s 代表字符串,%d 代表数字,%j 代表对象)。
2. inspect( obj ) ;
返回一个对象的字符串表示。
3. inherits( fn1,fn2 ) ;
实现构造方法之间的继承,fn1为当前的函数,fn2为要继承的函数。
本质是一块内存区域,用于暂存以后要用到的数据(可能是数字、字符串、二进制图片/音视频等),该区域就称为“缓存”,Buffer是global成员,使用时无须require,但要new。
1. 分配一个5字节大小的缓冲区;
var buf1 = new Buffer ( 5 );//
2. 用数字数组创建一个缓冲区,大小为3字节(存入10进制,底层为2进制,输出为16进制);
var buf2 = new Buffer ( [1, 3, 5] );//
3. 使用一个字符串创建一个缓冲区,大小为4字节;
var buf3 = new Buffer ( 'abcd' );//
4. 把一个缓冲区中的数据转换为字符串(ASCLL码);
var str = buf3.toString( );// abcd
5. 使用带中文的字符串按utf8的格式转为缓冲区(utf8中一个中文3字节);
var buf4=new Buffer(“AB一二”,“utf8”);//
该模块提供了对文件系统中的文件/目录进行增删改查、读写的功能。
常用方法如下:
1. fs.readFile( file, function(err, data){} );
异步读取文件中的内容,异步都有回调函数,没有完成会静默失败,需要手工处理。

2. fs.readFileSync( file );
同步读取文件中的内容,服务器启动必须先读某个文件才能运行就要用同步读取功能。

3. fs.writeFile( file, str/buf, function(err){ } );
异步向文件中写入内容(删除已有内容)

4. fs.writeFileSync( file, str/buf );
同步向文件中写入内容(删除已有内容)

5. fs.appendFile(file, str/buf , function(err){ });
异步向文件中追加写入内容(不删除已有内容)

6. fs.appendFileSync( file, str/buf );
同步向文件中追加写出内容(不删除已有内容)

7. fs.stat(path, function(err, stats){});
异步返回一个文件或目录的统计信息对象,常用于判断是文件还是文件夹

8. fs.statSync(path);
同步返回一个文件或目录的统计信息对象,常用于判断是文件还是文件夹

9. fs.unlink(path,function(err){ });
异步删除文件

10. fs.unlinkSync(path);
同步删除文件

11. fs.mkdir(path, function(err){ });
异步创建一个目录

12. fs.mkdirSync(path);
同步创建一个目录

13. fs.rmdir ( path, function(err){ });
异步删除一个目录

14. fs.rmdirSync ( path);
同步删除一个目录

15. fs.rename(oldFile,newFile,function(err){ });
异步重命名文件

16. fs.renameSync(oldFile,newFile);
同步重命名文件

17. fs.readdir(path,function(err,list ){ });
异步读取目录下的内容

18. fs.readdirSync(path);
同步读取目录下的内容

19. fs.createReadStream(path);
以文件流的方式读取数据

20. fs.createWriteStream(path);
以文件流的方式写入数据

21. readerStream.pipe(writeStream);
管道提供了一个输出流到输入流的机制,通常我们用于从一个流中获取数据并将数据传递到另外一个流中。

如上面的图片所示,我们把文件比作装水的桶,而水就是文件里的内容,我们用一根管子(pipe)连接两个桶使得水从一个桶流入另一个桶,这样就慢慢的实现了大文件的复制过程。

该模块可用于编写基于HTTP协议的客户端程序(即浏览器);也可以编写基于HTTP协议的服务器端程序(即Web服务器)
htttp常用的类:
1. http.ClientRequest 常用的两个函数 http.get 和 http.request,功能是作为客户端向http服务器发起请求;
常用的方法如下:
(1). setEncoding( ) 设置响应格式;
(2). setTimeout(time,fn) 设置请求超时;
(3). abort( ) 终止请求;
(4). write( ) 向服务器提交请求数据,仅用于POST请求;
(5). end( ) 链接结束;
常用的事件如下:
(1). data 收到数据后的响应事件;
(2). err 链接产生错误时的事件;
GET请求方法

POST请求方法

2. http.Server 编写服务器端程序;
常用的方法如下:
(1). listen( ) 启动服务器,监听指定的服务器端口;
(2). setHeader( ) 设置请求头的值,常用于跨域请求, 如response.setHeader('Access-Control-Allow-Origin','*');
当使用 setHeader( )设置响应头时,它们将与传给 writeHead( ) 的任何响应头合并, 其中writeHead( ) 的响应头优先。
(3). writeHead( ) 向请求发送响应头;
(4). write( ) 输出响应消息;
(5). end( ) 链接结束,如果不用write( ) ,也可将需要返回的数据当作参数传给此事件返回客户端;
常用的事件如下:
(1). data 收到请求数据后的响应事件;
(2). end 获取请求数据结束的响应事件;
(3). err 链接产生错误时的事件;

为了精简Node.js解释器,官方没有提供访问任何数据库相关模块,使用npm工具下载mysql模块:npm i mysql ,连接方法有以下三种:
1. 使用createConnection()方法创建连接对象;

2. 通过createPool()使用连接池连接;
数据库连接是一种有限且能够显著影响到整个应用程序的伸缩性和健壮性的资源,在多用户的网页应用程序中体现得尤为突出。
数据库连接池正是针对这个问题提出来的,它会负责分配、管理和释放数据库连接,允许应用程序重复使用一个现有的数据库连接,而不是重新建立一个连接,释放空闲时间超过最大允许空闲时间的数据库连接,以避免因为连接未释放而引起的数据库连接遗漏,数据库连接池能明显提高对数据库操作的性能。

3. 使用poolCluster连接池集群连接;
数据库集群(Cluster)是利两台或者多台数据库服务器,构成一个虚拟单一数据库逻辑映像,并像单数据库系统那样,向客户端提供透明的数据服务。

Settings配置(图一)

MySqlNodeConfig配置(图二)

getQuery方法(图三)

postQuery方法(图四)

1. 客户端请求静态HTML页面;
2. 服务器返回客户端请求的静态资源(express.static中间件);
3. 客户端加载完成,异步请求必需的动态数据;
4. 服务器返回动态数据(一般都是JSON格式);
5. 客户端异步读取动态数据,解析出来,挂载到DOM树 ;




 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有