原标题:Node.js躬行记(26)——接口拦截和页面回放实验
最近在研究 Web自动化测试,之前做了些实践,但效果并不理想。
对于 QA 来说,公司的网页交互并不多,用手点点也能满足。对于前端来说,如果要做成自动化,就得维护一堆的脚本。
当然,这些脚本也可以 QA 来维护,但前提是得让他们觉得做这件事的 ROI 很高,依目前的情况看,好像不高。
所以在想,做一个平台,在这个平台中可以保存些数据,并且在旁边提供个小窗口,呈现要测试的 H5 网页,如下图所示(画图工具是excalidraw)。
在修改相关数据后,可以直接看到网页的变化。
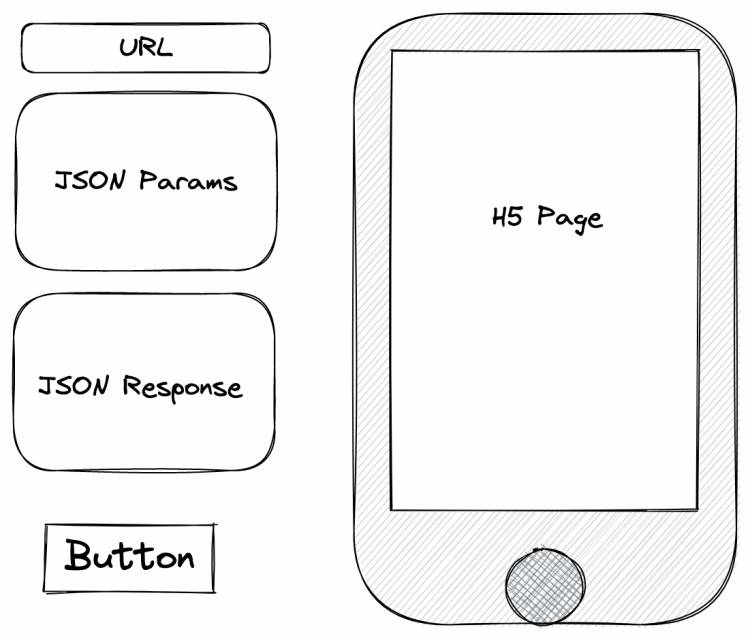
QA 或前端可以不用再写脚本代码,就能实现自动化测试。
目前想到两块,第一块是拦截请求,mock 响应;第二块是记录页面行为,然后自动回放,最后截图,和上一次的截图做对比分析,看是否相同。
一、拦截请求
拦截请求就是将响应 mock 成自己想要的数据,然后查看页面的呈现。
这样就能模拟各种场景,毕竟测试环境的业务数据肯定不能满足所有场景,所以需要自己造。
有了平台后,就能将造的数据保存在数据库中,可随时调取查看页面呈现。
1)拦截
现在就要实现拦截,我首先想到的就是注入脚本,然后在 XMLHttpRequest 或 fetch() 埋入拦截代码。
以 XMLHttpRequest 为例,在 monitorXHR() 函数中就可以让请求转发到代理处。
var _XMLHttpRequest = window.XMLHttpRequest; // 保存原生的XMLHttpRequest
// 覆盖XMLHttpRequest
window.XMLHttpRequest = function (flags) {
var req = new _XMLHttpRequest(flags); // 调用原生的XMLHttpRequest
monitorXHR(req); // 埋入我们的“间谍”
return req;
};
例如将所有的请求都 post 到 test/proxy 接口,这是一个 Node 接口,代码如下。
代码比较简单,没有考虑各种请求,例如自定义的 header、COOKIE 等。因为没有经过实践,只是展示下思路,所以肯定存在着 BUG。
思路就是将整理好的请求地址、参数等信息转发过来后,先从数据库中查看是否有指定的 mock 数据。
如果有就直接返回,若没有,就再去请求原接口。
router.post("/test/proxy", async (ctx) => {
const { id, method, url, params } = ctx.request.body;
// 通过ID查找存储在 MongoDB 中的拦截记录
const row = await swww.yii666.comervices.app.getOne(id);
if (row) {
ctx.body = row.response;
return;
}
// 没有拦截就请求原接口
const { data } = await axios[method](url, params);
ctx.body = data;
});
理论上,是完成了拦截,但是现在还有个很重要的问题,那就是 XMLHttpRequest 或 fetch() 那段间谍脚本该怎么注入。
2)注入脚本
暂时想到了三个方法,第一个是通过控制 iframe 在页面中注入脚本。
因为那张 H5 示例页面,可以放到 iframe 中呈现,所以这种注入方式理论上可行。
只需要读取 HTMLIFrameElement 中的 contentDocument 属性就能得到页面中的 document。
document.getElementById('inner').contentDocument.body.innerHTML
但是 iframe 有个同源限制,必须是同源的才能通过脚本读取到 contentDocu文章来源地址19351.htmlment。
况且注入的时机也比较讲究,必须在发起请求之前,改写 XMLHttpRequest 或 fetch(),若用 Javascript 添加 script 元素,恐怕不够及时。
那么第二个方法,就是在构建的时候将脚本注入,当然,在上线后,这些脚本都是要去除掉的,仅限测试的时候使用。
不过这种方法不够自动化,需要研发配合,像我们这种小公司,就那么几个项目,倒也问题不大。
第三个方法是用无头浏览器(例如 puppeteer)将脚本注入(如下所示),然后再把新的页面结构作为响应返回。
await page.evaluate(async 文章来源地址19351.html() => {
const img = new Image();
img.src = "xxx.png";
document.body.appendChild(img);
});
// 获取 HTML 结构
const html = await page.content();
但有个地方要注意,输出页面结构的域名要和之前相同(需要运维配合),否则那些脚本很有可能因为跨域而无法执行了。
二、记录页面行为
网页就是一棵 DOM 树,要记录页面行为,其实就是记录发生动作的 DOM 元素以及相关的动作参数。
脚本注入的方式可以参考上面的 3 种方法,平台的布局也与上面的类似,只是表单中的参数可能略有不同。
1)保存 DOM 元素
DOM 元素是不能直接 JSON 序列化的,所以需要将其映射成一个指定结构的对象,如下所示。
{
"type": "scrollTo",
"rect": {
"top": 470,
"left": 8,
"width": 359,
"height": 400
},
"scroll": {
"top": 189.5,
"left": 0
},
"tag": "div"
}
tag 是元素类型,例如 div、button、window 等;type 是事件类型,例如点击、滚动等;rect 是坐标和尺寸,scroll 是滚动距离。
这种结构就可以顺利存储到数据库中了。
2)监控行为
目前实验,就只监控了点击和滚动两种行为。
为 body 元素绑定 click 事件,采用捕获的事件传播方式。
/**
* 监控 body 内的点击行为
*/
document.body.addEventListener('click', (e) => {
behaviors.push({
type: 'click',
rect: offsetRect(e.target),
tag: e.target.tagName.toLowerCase()
});
}, true);
rect 的尺寸和坐标本来是通过 getBoundingClientRect() 获取的,但是该方法参照的是视口的左上角,也就是说会随着滚动而改变坐标。
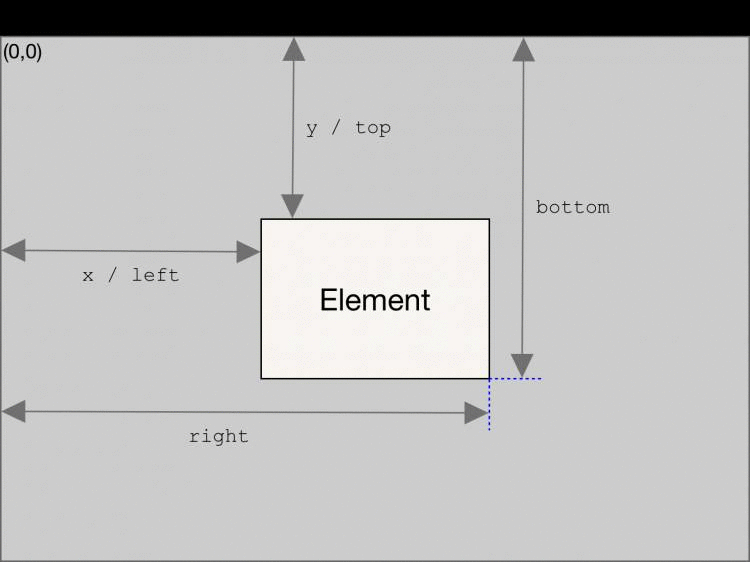
所以就换了一种能更加精确获取坐标的方法,如下所示,nodeMap 是一个 Map 数据结构,key 可以是一个元素对象,用于缓存计算过的元素坐标。
// 元素缓存
const nodeMap = new Map();
/**
* 读取元素真实的坐标
*/
function offsetRect(node) {
// 从缓存中读取node信息
const exist = nodeMap.get(node);
if(exist) {
return exist;
}
let top = 0, left = 0;
const width = node.offsetWidth
const height = node.offsetHeight;
while (node) {
top += node.offsetTop;
left += node.offsetLeft;
node = node.offsetParent;
}
const rect = { top, left, width, height };
nodeMap.set(node, rect); // 缓存node信息
return rect;
}
下面是对滚动的监控代码,throttle() 是一个节流函数,不节流会影响滚动的性能。
在 startScroll() 函数中会计算滚动条距离顶部和左边的距离,window 和元素读取的属性略有不同。
/**
* 节流
*/
function throttle(fn, wait) {
let start = 0;
return (e) => {
const now = +new Date();
if (now - start > wait) {
fn(e);
start = now;
}
};
}
/**
* 对滚动节流
*/
const startScroll = throttle((e) => {
const target = e.target;
let tag, rect, scroll;
if(target.defaultView === window) {
tag = 'window';
scroll = {
top: window.pageYOffset,
left: window.pageXOffset
};
}else {
tag = target.tagName.toLowerCase();
scroll = {
top: target.scrollTop,
left: target.scrollLeft
};
rect = offsetRect(target);
}
behaviors.push({
type: 'scrollTo',
rect,
scroll,
tag
});
}, 100);
/**
* 监控页面的滚动行为
*/
window.addEventListener('scroll', (e) => {
startScroll(e);
}, true);
3)还原
在得到数据结构后,就得让其还原,呈现完成一系列动作后的页面。
我写的算法比较简单,还有很大的优化空间。目前就是遍历存储的行为数组,然后深度优先搜索 body 内的所有子元素。
当坐标和尺寸满足条件时,返回元素。不过这种方式非常依赖这两个参数,因此只要结构发生变化,那么动作就无法完成。
function revert(behaviors) {
let isFind = false;
// 深度优先遍历
const dfs = (node, target) => {
if (!node) return;
const rect = offsetRect(node);
const tag = node.tagName.toLowerCase();
// console.log(node, rect, target)
// 根据坐标定位元素
if (target.tag === tag &&
target.rect.top === rect.top &&
target.rect.left === rect.left &&
target.rect.width === rect.width &&
ta文章来源站点https://www.yii666.com/rget.rect.height === rect.height) {
target.node = node; //记录元素
isFind = true;
return;
}
node.children && Array.from(node.children).forEach((value) => {
if (isFind) { return; }
dfs(value, target);
});
};
behaviors.forEach(item => {
isFind = false;
// window对象单独处理
if(item.tag === 'window') {
item.node www.yii666.com= window;
}else {
dfs(document.body, item);
}
const { node } = item;
// 没有找到符合要求的元素
if(!node) return;
switch(item.type) {
case 'scrollTo': // 滚动
node.scrollTo({
...item.scroll,
behavior: 'smooth'
});
break;
default: // 其他事件
node[item.type]();
break;
}
});
}
scrollTo() 是一个滚动的方法,smooth 是一种平滑选项,奇怪的是,当我去掉此选项时,滚动就无法完成了。
4)截图
本来是计划用脚本来实现截图的,可选的库是 dom-to-image 和 html2canvas。
但是测试下来得到的截图结果都不是很理想,于是就仍然采用 puppeteer 来实现截图。
先将行为脚本注入,然后等几秒,最后再截图。这种截图得到的结果比较准确,但就是执行过程有点慢,经常需要十几秒甚至更长。
await page.evaluate(async () => {
const scrpt = document.createElement("script");
scrpt.src = "xx.js";
document.body.appendChild(scrpt);
});
await page.waitForTimeout(2000);
await page.screenshot({
path: `xx/1.png`,
type: "png"
});
两张截图的对比可以通过 pixelmatch 完成,下面是官方提供的 node.js 使用示例,pngjs 是一个 png 图像编解码器。
const fs = require('fs');
const PNG = require('pngjs').PNG;
const pixelmatch = require('pixelmatch');
const img1 = PNG.sync.read(fs.readFileSync('img1.png'));
const img2 = PNG.sync.read(fs.readFileSync('img2.png'));
const {width, height} = img1;
const diff = new PNG({width, height});
pixelmatch(img1.data, img2.data, diff.data, width, height, {threshold: 0.1});
fs.writeFileSync('diff.png', PNG.sync.write(diff));
来源于:Node.js躬行记(26)——接口拦截和页面回放实验









 京公网安备 11010802041100号
京公网安备 11010802041100号