urllib库的简单使用 && 一个简单的Python爬虫示例
本篇文章,介绍urllib.request库的简单使用以及注意的问题。最后实现一个Python爬虫的示例。
本文是基于Python3.6.2实现的。urllib.request相当于Python2.7中的urllib2的库的一部分。
urllib.request库的简单使用
respOnse= urllib.request.urlopen('http://www.baidu.com/')
result = response.read()
print(result)
print(type(result))
with open('baidu.html','wb') as f:
f.write(result)
通过浏览器打开baidu.html文件,实际和浏览器输出http://www.baidu.com/结果是一样的。
其实上面的程序还不够好,因为我们直接通过urlopen(url)发送请求,实际上在http的请求头中有一个User-Agnet字段会标记为Python-urllib/3.6。如下面的http的headers是通过fiddler抓包获取的。
GET http://www.baidu.com/ HTTP/1.1
Accept-Encoding: identity
Host: www.baidu.com
User-Agent: Python-urllib/3.6
Connection: close
浏览器访问的header信息如下:
GET https://www.baidu.com/ HTTP/1.1
Host: www.baidu.com
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36
...
我们通过爬虫程序访问的第三方服务器,服务器就能知道你是通过爬虫程序访问的。因为你的http的请求头信息User-Agent字段出卖了你。所以我们需要修改请求头的User-Agent字段信息,防止ip被禁。
url = 'http://www.baidu.com/'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36'}
request = urllib.request.Request(url,headers = headers)
respOnse= urllib.request.urlopen(request)
result = response.read()
with open('baidu.html','wb') as f:
f.write(result)
当获取响应的response对象时,我们可以获取响应码,响应体等信息,如:
# 获取响应码
response.getcode()
# 获取请求的url
response.geturl()
# 获取响应头信息
response.info()
在url的get请求,url会有中文的问题,这时的中文需要转码成urlencode编码。我们需要通过quote()处理中文字符的问题。
# 将中文转成urlencode编码
result = urllib.request.quote('薛之谦')
# 输出,结果:%E8%96%9B%E4%B9%8B%E8%B0%A6
print(result)
# 将urlencode编码的数据,进行解码
result = urllib.request.unquote('%E8%96%9B%E4%B9%8B%E8%B0%A6')
# 输出,结果:薛之谦
print(result)
一个简单的Python爬虫示例
该爬虫爬取的网站是百度贴吧。具体入下:
创建一个tieba.py的文件,代码如下:
import urllib.request
def load_page(request):
"""
加载网络的页面信息
:param request: 请求参数
:return:返回服务端的响应信息
"""
return urllib.request.urlopen(request)
def write_page(response, filename):
"""
将响应返回的信息,写入文件保存
:param response:服务器返回的响应信息
:param filename:保存的文件名
:return:
"""
cOntent= response.read()
with open(filename, 'wb') as f:
f.write(content)
def spider(url, headers, startPage, endPage):
"""
爬取网页的方法
:param url: 请求的url
:param headers:自定义的请求头信息
:param startPage:请求的开始页面
:param endPage:请求的结束页面
:return:
"""
for page in range(startPage, endPage + 1):
page = (page - 1) * 50
fullUrl = url + '&pn=' + str(page)
print(fullUrl)
request = urllib.request.Request(fullUrl, headers=headers)
respOnse= load_page(request)
filename = '第' + str(int(page / 50 + 1)) + "页.html"
write_page(response, filename)
if __name__ == '__main__':
url = 'https://tieba.baidu.com/f?'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36'}
keyword = input('请输入关键字:')
keyword = urllib.request.quote(keyword)
fullUrl = url + "kw=" + keyword
startPage = int(input("输入起始页:"))
endPage = int(input('输入结束页:'))
spider(fullUrl, headers, startPage, endPage)
运行tieba.py文件,在控制台会让你输入:请输入关键字:等。如图:
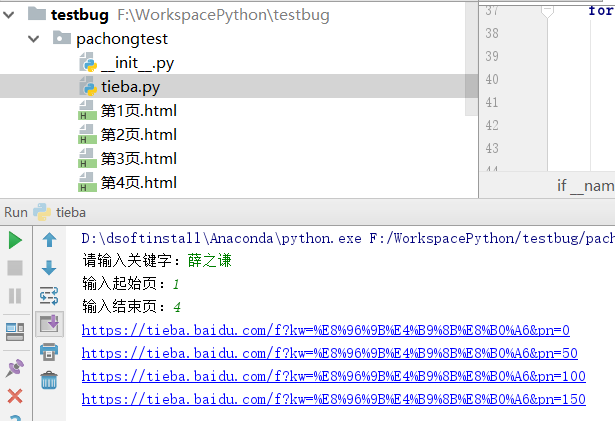







 京公网安备 11010802041100号
京公网安备 11010802041100号