
主从复制,是指将一台 Redis 服务器的数据,复制到其他的 Redis 服务器。前者称为主节点(Master),后者称为从节点(Slave);数据的复制是单向的,只能由主节点到从节点。
默认情况下,每台 Redis 服务器都是主节点;且一个主节点可以有多个从节点 (或没有从节点),但一个从节点只能有一个主节点。
环境准备:
| 服务器类型 | 系统和IP地址 | 需要安装的组件 | 其他 |
|---|---|---|---|
| master服务器 | CentOS7.4(64 位) 192.168.80.100 | redis-5.0.7.tar.gz | 需要使用yum在线源 |
| slave服务器1 | CentOS7.4(64 位) 192.168.80.20 | redis-5.0.7.tar.gz | 需要使用yum在线源 |
| slave服务器2 | CentOS7.4(64 位)192.168.80.30 | redis-5.0.7.tar.gz | 需要使用yum在线源 |
1.首先要搭建redis

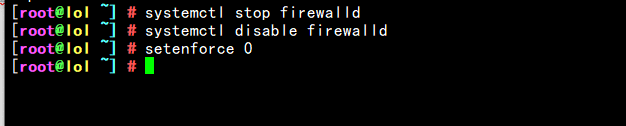
2.关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
3.修改master主配置文件
-----------修改Redis 配置文件(Master节点操作) ----------
vim /etc/redis/6379.conf
bind 0.0.0.0 #70行,注释掉bind项,或修改为0.0.0.0,默认监听所有网卡
daemonize yes #137行,开启守护进程
logfile /var/log/redis_6379.log #172行,指定日志文件目录
dir /var/lib/redis/6379 #264行,指定工作目录
appendonly yes #700行,开启AOF持久化功能/etc/init.d/redis_6379 restart


重启

4.修改slave1和slave2主配置文件
-----------修改Redis 配置文件(Slave节点操作)------------
vim /etc/redis/6379.conf
bind 0.0.0.0 #70行,修改监听地址为0.0.0.0
daemonize yes #137行,开启守护进程
logfile /var/log/redis_6379.log #172行,指定日志文件目录
dir /var/lib/redis/6379 #264行,指定工作目录
replicaof 192.168.80.10 6379 #287行,取消注释并指定要同步的Master节点IP和端口
appendonly yes #700行,开启AOF持久化功能/etc/init.d/redis_6379 restart



重启

slave2一样

5.验证主从效果
-------------验证主从效果-------------
在Master节点上看日志:
tail -f /var/log/redis_6379.log在Master节点上验证从节点:
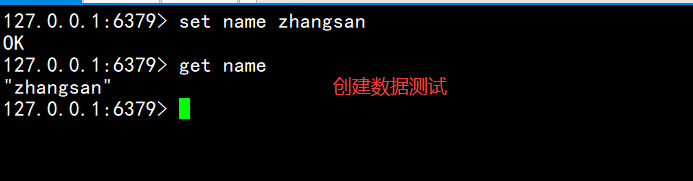
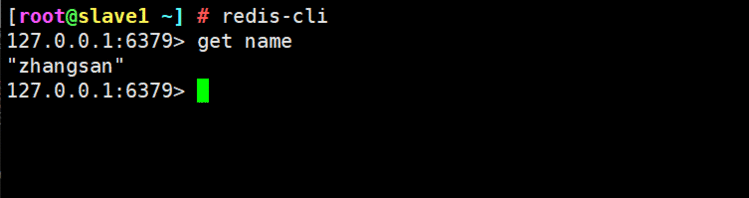
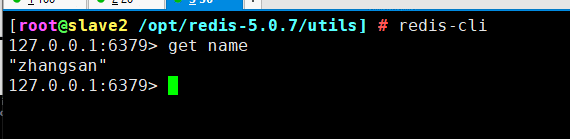
redis-cli
127.0.0.1:6379> info replication



哨兵的核心功能:在主从复制的基础上,哨兵引入了主节点的自动故障转移。
哨兵(sentinel):是一个分布式系统,用于对主从结构中的每台服务器进行监控,当出现故障时通过投票机制选择新的Master,并将所有Slave 连接到新的Master。所以整个运行哨兵的集群的数量不得少于3个节点。
哨兵结构由两部分组成:哨兵节点和数据节点。
哨兵的启动依赖于主从模式,所以须把主从模式安装好的情况下再去做哨兵模式,所有节点上都需要部署哨兵模式,哨兵模式会监控所有的Redis 工作节点是否正常,当Master 出现问题的时候,因为其他节点与主节点失去联系,因此会投票,投票过半就认为这个 Master 的确出现问题,然后会通知哨兵间,然后从Slaves中选取一个作为新的 Master。
需要特别注意的是:客观下线是主节点才有的概念;如果从节点和哨兵节点发生故障,被哨兵主观下线后,不会再有后续的客观下线和故障转移操作。
1.所有节点修改哨兵模式的配置文件
--------修改Redis哨兵模式的配置文件(所有节点操作) --------
vim /opt/redis-5.0.7/sentinel.conf
protected-mode no #17行,关闭保护模式
port 26379 #21行,Redis哨兵默认的监听端口
daemonize yes #26行,指定sentinel为后台启动
logfile "/var/log/sentinel.log" #36行,指定日志存放路径
dir "/var/lib/redis/6379" #65行,指定数据库存放路径
sentinel monitor mymaster 192.168.80.10 6379 2 #84行, 修改
指定该哨兵节点监控192.168.80.10:6379这个主节点,该主节点的名称是mymaster,最后的2的含义与主节点的故障判定有关:至少需要2个哨兵节点同意,才能判定主节点故障并进行故障转移
sentinel down-after-milliseconds mymaster 30000 #113行,判定服务器down掉的时间周期,默认30000毫秒(30秒)
sentinel failover-timeout mymaster 180000 #146行,故障节点的最大超时时间为180000 (180秒 )





2.启动哨兵模式
----------启动哨兵模式-----------------
注意:先启master,再启slave
cd /opt/redis-5.0.7/
redis-sentinel sentinel.conf &

3.查看哨兵信息
-----------查看哨兵信息------------------
redis-cli -p 26379 info Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=192.168.80.10:6379,slaves=2,sentinels=3
4.故障模拟
---------故障模拟--------------
#查看redis-server进程号(在Master 上进行):
ps -ef | grep redis
root 16913 1 0 19:12 ? 00:00:20 /usr/local/redis/bin/redis-server 0.0.0.0:6379
root 18991 1 0 22:37 ? 00:00:02 redis-sentinel *:26379 [sentinel]
root 19141 16668 0 22:50 pts/1 00:00:00 grep --color=auto redis#杀死 Master 节点上redis-server的进程号
kill -9 57521 #Master节点上redis-server的进程号

5.验证master是否切换
#验证结果,查看master是转换至从服务器
tail -f /var/log/sentinel.log#在Slave1上查看是否转换成功
redis-cli -p 26379 INFO Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=192.168.80.20:6379,slaves=2,sentinels=3



集群,即 Redis Cluster, 是Redis 3. 0开始引入的分布式存储方案。
集群由多个节点(Node) 组成,Redis 的数据分布在这些节点中。
集群中的节点分为主节点和从节点;只有主节点负责读写请求和集群信息的维护;从节点只进行主节点数据和状态信息的复制。
. Redis集群引入了哈希槽的概念
. Redis集群有 16384 个哈希槽( 编号0-16383)
. 集群的每个节点负责一部分哈希槽
. 每个Key 通过 CRC16 校验后对16384取余来决定放置哪个哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作
集群中具有A、B、C三个节点,如果节点B失败了,整个集群就会因缺少5461-10922这个范围的槽而不可以用。
为每个节点添加一个从节点A1、B1、C1整个集群便有三个Master节点和三个slave节点组成,在节点B失败后,集群选举B1位为主节点继续服务。当B和B1都失败后,集群将不可用。
环境准备工作:
| 服务器类型 | 系统和IP地址 | 需要安装的组件 | 节点端口 |
|---|---|---|---|
| master服务器 | CentOS7.4(64 位) 192.168.80.10 | redis-5.0.7.tar.gz | 6001 |
| master服务器 | CentOS7.4(64 位) 192.168.80.20 | redis-5.0.7.tar.gz | 6002 |
| master服务器 | CentOS7.4(64 位) 192.168.80.30 | redis-5.0.7.tar.gz | 6003 |
| slave服务器 | CentOS7.4(64 位) 192.168.80.40 | redis-5.0.7.tar.gz | 6004 |
| slave服务器 | CentOS7.4(64 位) 192.168.80.50 | redis-5.0.7.tar.gz | 6005 |
| slave服务器 | CentOS7.4(64 位) | 192.168.80.60 | redis-5.0.7.tar.gz |
1.创建目录复制配置文件到对应的节点上
redis的集群一般需要6个节点, 3主3从。方便起见,这里所有节点在同一台服务器上模拟:
以端口号进行区分: 3个主节点端口号: 6001/6002/6003, 对应的从节点端口号: 6004/6005/6006cd /etc/redis/
mkdir -p redis-cluster/redis600{1..6}for i in {1. .6}
do
cp /opt/redis-5.0.7/redis.conf /etc/redis/redis-cluster/redis600$i
cp /opt/redis-5.0.7/src/redis-cli /opt/redis-5.0.7/src/redis-server /etc/redis/redis-cluster/redis600$i
done


2.修改主配置文件,设置开启群集功能
#其他5个文件夹的配置文件以此类推修改,注意6个端口都要不一样。
cd /etc/redis/redis-cluster/redis6001
vim redis.conf
#bind 127.0.0.1 #69行,注释掉bind项,默认监听所有网卡
protected-mode no #88行,修改,关闭保护模式
port 6001 #92行,修改,redis监听端口
daemonize yes #136行,开启守护进程,以独立进程启动
appendonly yes #699行,修改,开启AOF持久化
cluster-enabled yes #832行,取消注释,开启群集功能
cluster-config-file nodes-6001.conf #840行,取消注释,群集名称文件设置
cluster-node-timeout 15000 #846行,取消注释群集超时时间设置#可以写一个for循环将6001的文件复制给6002~6006,这样就不需要全部一个一个文件进行修改了
for i in {2..6}
do
/usr/bin/cp -f /etc/redis/redis-cluster/redis6001/redis.conf /etc/redis/redis-cluster/redis600$i/redis.conf
done#之后稍微修改文件即可(修改以下两个配置项):
92行,修改,redis监听端口
840行,取消注释,群集名称文件设置
3.启动redis节点
# 启动redis节点(方法一)
分别进入那六个文件夹,执行命令: redis-server redis.conf,来启动redis节点
cd /etc/redis/redis-cluster/redis6001
redis-server redis.conf## 使用for循环一键启动所有节点(方法二)
for d in {1..6}
do
cd /etc/redis/redis-cluster/redis600$d
redis-server redis.conf
doneps -ef | grep redis
4.启动集群
#启动集群
redis-cli --cluster create 127.0.0.1:6001 127.0.0.1:6002 127.0.0.1:6003 127.0.0.1:6004 127.0.0.1:6005 127.0.0.1:6006 --cluster-replicas 1#六个实例分为三组,每组一主一从,前面的做主节点,后面的做从节点。下面交互的时候需要输入yes 才可以创建。
-replicas 1 #表示每个主节点有1个从节点。
5.测试集群
#测试群集
redis-cli -p 6001 -c #加-c参数,节点之间就可以互相跳转
127.0.0.1:6001> cluster slots #查看节点的哈希槽编号范围
1) 1) (integer) 54612) (integer) 10922 #哈希槽编号范围3) 1) "127.0.0.1" .2) (integer) 6003 #主节点IP和端口号3) " fdca661922216dd69a 63a7c9d3c4540cd6baef44"4) 1) "127.0.0.1"2) (integer) 6004 #从节点IP和端口号3) "a2c0c32aff0f38980accd2b63d6d952812e44740"
2) 1) (integer) 02) (integer) 54603) 1) "127.0.0.1"2) (integer) 60013) "0e5873747a2e2 6bdc935bc76c2ba fb19d0a54b11"4) 1) "127.0.0.1"2) (integer) 60063) "8842ef5584a85005e135fd0ee59e5a0d67b0cf8e"
3) 1) (integer) 10923 2) (integer) 163833) 1) "127.0.0.1"2) (integer) 60023) "81 6ddaa3d14 69540b2f fbcaaf9aa867646846b30"4) 1) "127.0.0.1"2) (integer) 60053) "f847077bfe6722466e96178ae8cbb09dc8b4d5eb"127.0.0.1:6001> set name zhangsan
-> Redirected to slot [5798] located at 127.0.0.1: 6003
OK127.0.0.1:6001> cluster keyslot name #查看name键的槽编号
(integer) 5798






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 
