
你还在头疼于经典模型的复现吗?
不知何处可以得到全面可参照的Benchmark?
为了让开发者可以快速复现顶尖的精度和超高的性能,NVIDIA与飞桨团队合作开发了基于ResNet50的模型示例,并将持续开发更多的基于NLP和CV等领域的经典模型,后续陆续发布的模型有BERT、PP-OCR、PP-YOLO等,欢迎持续关注。
深度学习模型是什么?
深度学习包括训练和推理两个环节。训练是指通过大数据训练出一个复杂的神经网络模型,即用大量标记过的数据来“训练”相应的系统,使之可以实现特定的功能。推理是指利用训练好的模型,基于新数据推理出各种结论。深度学习模型是在训练工作过程中生成,并被保存用于推理当中。
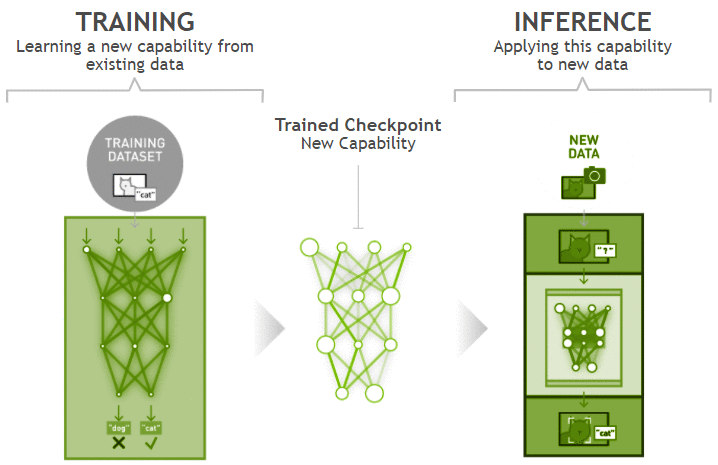
图1: 深度学习训练推理示意图
NVIDIA Deep Learning Examples仓库
全新上线飞桨ResNet50
NVIDIA Deep Learning Examples仓库上线了基于飞桨实现的ResNet50模型的性能优化结果,该示例全面适配各类NVIDIA GPU和各种硬件拓扑(单机单卡、单机多卡),性能极致优化。值得一提的是,Deep Learning Examples中飞桨ResNet50模型训练速度已超过对应的PyTorch版ResNet50。
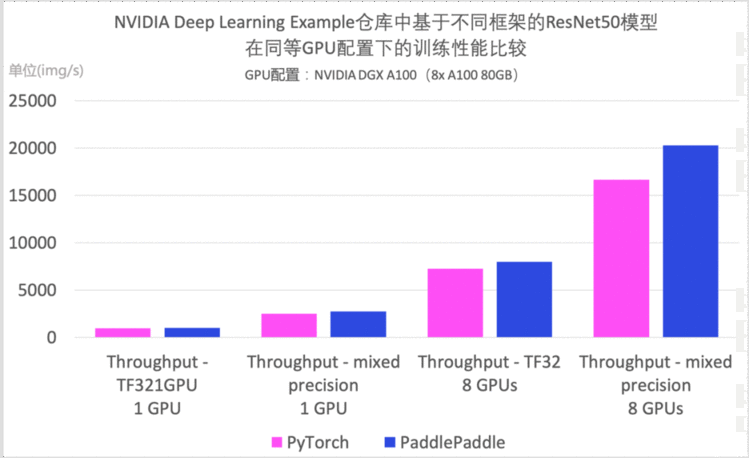
图2: NVIDIA Deep Learning Examples仓库中基于飞桨与PyTorch的ResNet50模型在同等GPU配置下的训练性能比较,GPU配置为NVIDIA DGX A100(8x A100 80GB)。 *数据来源:[1][2]
NVIDIA Deep Learning Examples仓库中
飞桨ResNet50有哪些优势?
NVIDIA Data Loading Library(DALI)专注于使用GPU加速深度学习应用中的数据加载和预处理。深度学习数据预处理涉及到复杂的、多个阶段的处理过程,如ResNet50模型训练过程中,在CPU上处理图片的加载、解码、裁剪、翻转、缩放和其他数据增强等操作会成为瓶颈,限制训练和推理的性能和可扩展性。DALI将这些操作转移到GPU上,最大限度地提高输入流水线的吞吐量,并且其中数据预取、并行执行和批处理的操作对用户是透明的。
飞桨内置支持AMP(自动混合精度)及ASP(自动稀疏化)模块。AMP模块可在模型训练过程中,自动为算子选择合适的计算精度(FP32/FP16),充分利用Tensor Cores的性能,在不影响模型精度的前提下,大幅加速模型训练。
ASP模块实现了一个工作流将深度学习模型从稠密修剪为2:4的稀疏模式,经过重训练之后,可恢复到与稠密模型相当的精度。稀疏模型可以充分利用A100 Tensor Core GPU的加速特性,被修剪的权重矩阵参数存储量减半,并且可以获得理论上2倍的计算加速,从而大幅提高推理性能。
飞桨推理集成了TensorRT,称为Paddle-TRT。它可以把部分模型子图交给TensorRT加速,而其他部分仍然用飞桨执行,从而达到最佳的推理性能。
NVIDIA Deep Learning Examples仓库中
有哪些Benchmark?
NVIDIA Deep Learning Examples仓库中的Benchmark主要包含训练精度结果、训练性能结果、推理性能结果、Paddle-TRT性能结果几个方面。
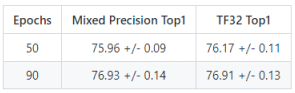
图3:训练精度:
NVIDIA DGX A100 (8x A100 80GB) 数据来源:[1]

图4:集成ASP的提高精度:
NVIDIA DGX A100 (8x A100 80GB) 数据来源:[1]

图5:训练性能:
NVIDIA DGX A100 (8x A100 80GB) 数据来源:[1]

图6:集成ASP的训练性能:
NVIDIA DGX A100 (8x A100 80GB) 数据来源:[1]
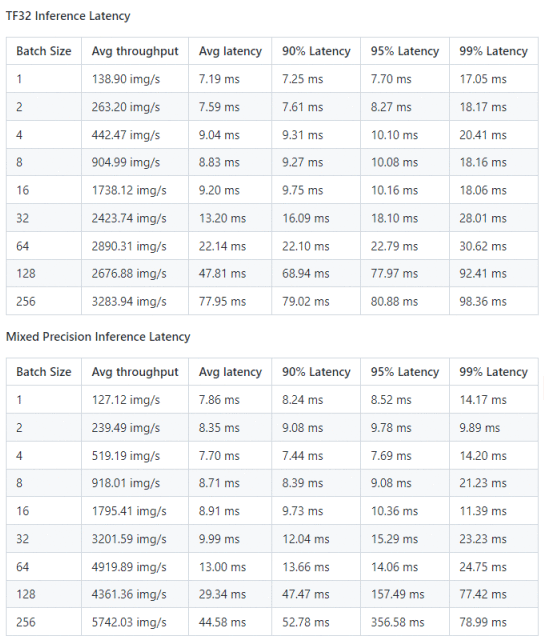
图7:推理性能:
NVIDIA DGX A100 (1x A100 80GB) 数据来源:[1]
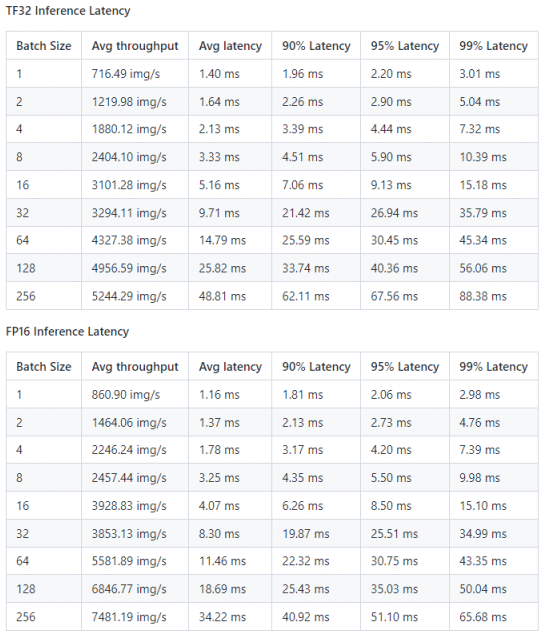
图8:Paddle-TRT 性能结果:
NVIDIA DGX A100 (1x A100 80GB) 数据来源:[1]
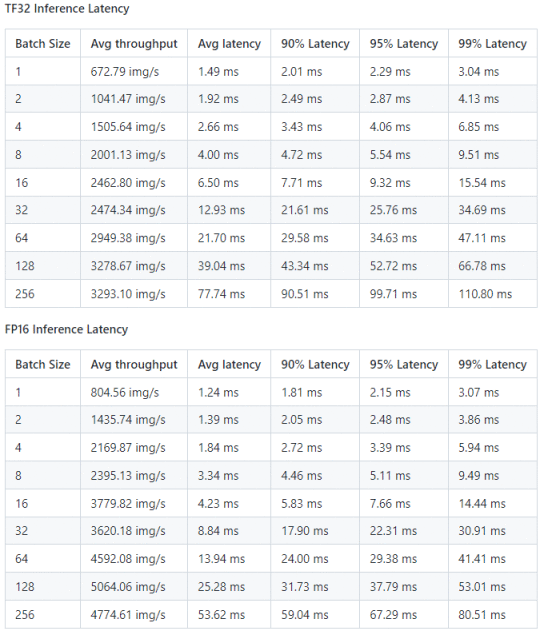
图9:Paddle-TRT 性能结果:
NVIDIA A30 (1x A30 24GB) 数据来源:[1]
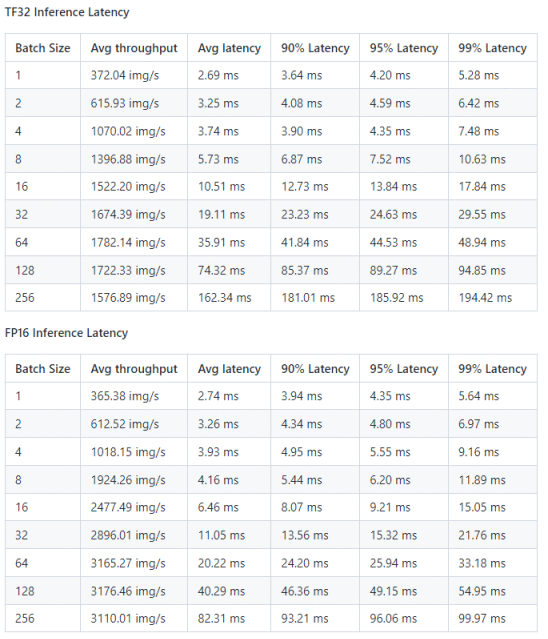
图10:Paddle-TRT 性能结果:
NVIDIA A10 (1x A10 24GB) 数据来源:[1]
如何下载NVIDIA Deep Learning Examples
仓库中的飞桨ResNeT50?
登录GitHub NVIDIA Deep Learning Examples仓库后,找到下列选项下载模型源代码即可。
PaddlePaddle/Classification/RN50/1.5
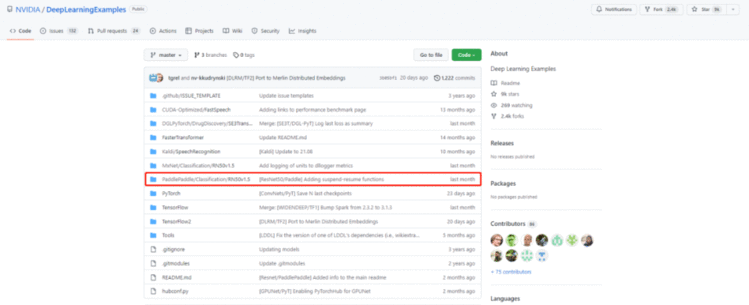
图11:NVIDIA Deep Learning Examples:
飞桨ResNet50下载页面
飞桨容器如何安装?
容器包含了深度学习框架在运行时所需的所有部件(包括驱动,工具包等),它具有轻量化与可复制性、打包和执行环境合二为一以及简化应用程序部署等优势。因此,被认为是在同一环境中实现“构建、测试、部署”的最佳平台。容器允许我们创建标准化可复制的轻量级开发环境,摆脱来自Hypervisor所带来运行开销。应用程序可以基于Container Runtime运行在“任意”系统中。
NVIDIA与百度飞桨联合开发了NGC飞桨容器,将最新版本的飞桨与最新的NVIDIA的软件栈进行了无缝的集成与性能优化,最大程度的释放飞桨框架在NVIDIA最新硬件上的计算能力。这样,用户不仅可以快速开启AI应用,专注于创新和应用本身,还能够在AI训练和推理任务上获得飞桨+NVIDIA带来的飞速体验。
NGC飞桨容器已经集成到飞桨官网主页。你可以选择“飞桨版本”+“Linux”+“Docker”+“CUDA 11.7”找到对应的容器下载指令。
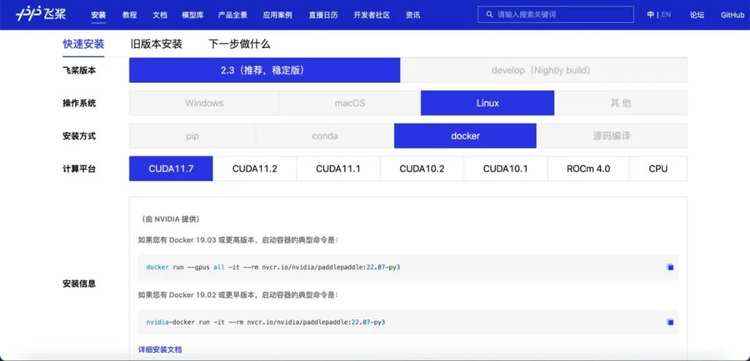
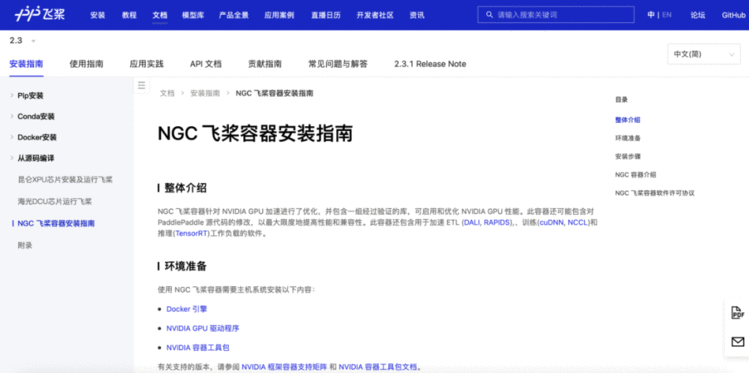
参考《NGC飞桨容器安装指南》下载安装:
https://www.paddlepaddle.org.cn/documentation/docs/zh/install/install_NGC_PaddlePaddle_ch.html
NVIDIA飞桨容器现已开放免费下载,点击“阅读原文”跳转至飞桨官网《NGC飞桨容器安装指南》页面可获取安装指南。同时,您可扫描下方二维码加入用户体验群,提交体验报告将获得更多精美礼品!

参考资料
[1]NVIDIA Deep Learning Examples仓库中基于飞桨框架的ResNet50性能
https://github.com/NVIDIA/DeepLearningExamples/tree/master/PaddlePaddle/Classification/RN50v1.5
[2] NVIDIA Deep Learning Examples仓库中基于PyTorch的ResNet50训练性能
https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/Classification/ConvNets/resnet50v1.5
拓展阅读
全新AI开发环境来了!NVIDIA产品专家为您解密NGC飞桨容器
揭秘!MLPerf Training v2.0飞桨何以力压NGC PyTorch,实现同等GPU配置BERT模型训练性能第一

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~








 京公网安备 11010802041100号
京公网安备 11010802041100号