作者:luosj | 来源:互联网 | 2023-09-25 17:59
NLP随笔(一)-20世纪50年代中期到80年代初期的感知器,20世纪80年代初期至21世纪初期的专家系统,以及最近十年的深度学习技术,分别是三次热潮的代表性产物Gartner
20 世纪50 年代中期到80 年代初期的感知器,20世纪80 年代初期至21世纪初期的专家系统,以及最近十年的深度学习技术,分别是三次热潮的代表性产物
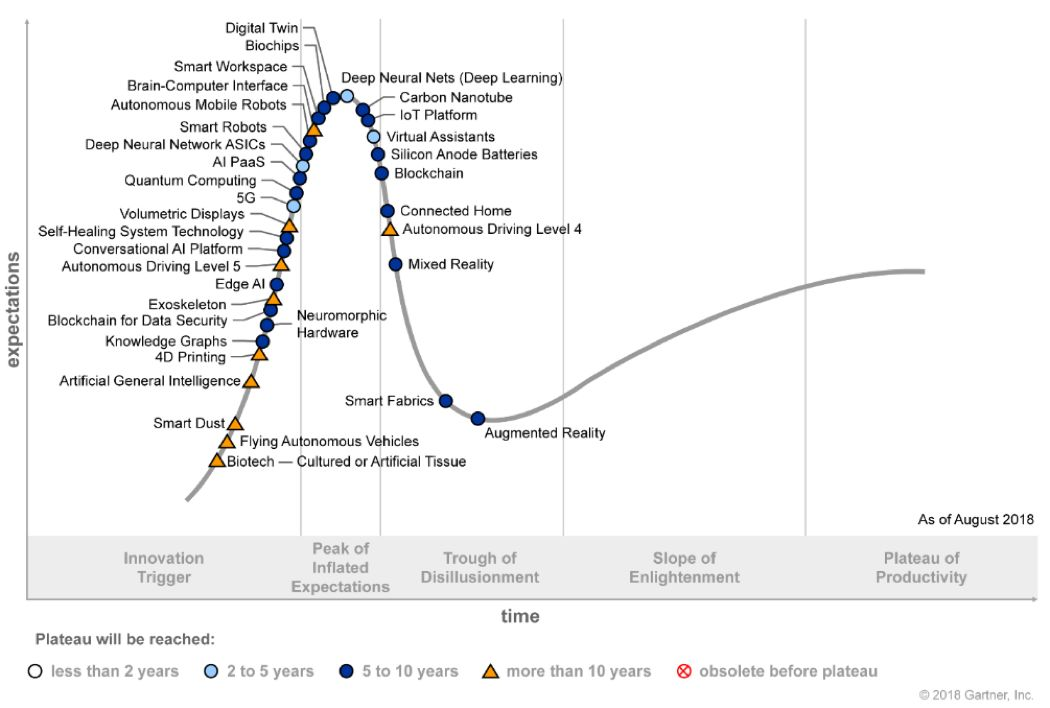
Gartner2018技术成熟度曲线,Gartner每年发布的技术趋势曲线,聚焦未来5到10年间,可能产生巨大竞争力的新兴技术
人工智能技术远未达到媒体所宣传的神通广大,无所不能。从图1中的技术发展现状也可一窥端倪。AlphaGo可以战胜最好的人类棋手,但却不可能为你端一杯水。著名机器人学者Hans Moravec早前说过:机器人觉得容易的,对于人类来讲将是非常难的;反之亦然。
人可以轻松做到听说读写,但对于复杂计算很吃力;而机器人很难轻松做到用手抓取物体、以及走上坡路,但可以轻而易举地算出空间火箭的运行轨道。人类可以通过日积月累的学习,轻松完成各种动作,但对于机器人来讲完成这些简单的动作难如登天。专家们称此理论为“莫拉维克悖论”(Moravec's Paradox)。机器学习专家、著名的计算机科学和统计学家 Michael I. Jordan近日在《哈佛数据科学评论》上发表文章,也认为现在被称为AI的许多领域,实际上是机器学习,而真正的 AI 革命尚未到来。
业界一致认为,AI的三要素是算法,算力和数据
从计算,到感知,再到认知,是大多数人都认同的人工智能技术发展路径。那么认知智能的发展现状如何?
首先,让我们看一下什么是认知智能。复旦大学肖仰华教授曾经提到,所谓让机器具备认知智能是指让机器能够像人一样思考,而这种思考能力具体体现在机器能够理解数据、理解语言进而理解现实世界的能力,体现在机器能够解释数据、解释过程进而解释现象的能力,体现在推理、规划等等一系列人类所独有的认知能力上
对于看、听、说、动作而言,感知智能已经可以达到非常好的效果。而对于推理、情感、联想等能力,还需要更强的认知能力的体现

虚拟生命基本能力范畴

虚拟生命发展阶段
虚拟生命1.0,可以看做是聊天机器人的升级版本。本阶段最重要的特点是单点技术的整合,并能作为整体和人类进行交互。从功能上来看,仍然是被动交互为主,但可以结合对用户的认知,进行用户画像和主动推荐。
我们目前正在处于虚拟生命的1.0阶段。在这个阶段,多轮对话、开放域对话、上下文理解、个性化问答、一致性和安全回复等仍然是亟待解决的技术难题。同时,虚拟生命也需要找到可落地的场景,做好特定领域的技术突破。
虚拟生命2.0,是目前正在努力前行的方向,在这个阶段,多模态技术整合已完全成熟,虚拟生命形态更为多样性,具备基于海量数据的联合推理及联想,对自我和用户都有了全面的认知,并可快速进行人格定制。实现这个阶段可能需要3-5年。
虚拟生命3.0, 初步达到强人工智能,具备超越人类的综合感知能力,并拥有全面的推理、联想和认知,具备自我意识,并能达到人类水平的自然交互。随着技术的进步,我们期待在未来十年至三十年实现虚拟生命的3.0。
语言是主要以发声为基础来传递信息的符号系统,是人类重要的交际工具和存在方式之一。作用于人与人的关系时,是表达相互反应的中介;作用于人和客观世界的关系时,是认识事物的工具;作用于文化时,是文化信息的载体(来源:维基百科)。语言与逻辑相关,而人类的思维逻辑最为完善
自底向上,自然语言处理需要通过对字、词、短语、句子、段落、篇章的分析,使得计算机能够理解文本的意义

比如和机器人对话的过程中,对于音乐话题的理解,就需要用到命名实体识别、实体链接等技术。举一个简单的例子,“我真的非常喜欢杰伦的双截棍”,就需要判断杰伦是一个人名,链接到知识库中“周杰伦”这样一个歌手实体,并且“双截棍”是一个歌名而不是一种器械。同时,还可以进行情感判断,是一个正面的“喜欢”的情感。
传统的自然语言处理技术,还是以统计学和机器学习为主,同时需要用到大量的规则。近十年来,深度学习技术的兴起,也带来了自然语言处理技术的突破。这一切还需要从语言的表示开始说起。
众所周知,计算机擅长处理符号,因此,自然语言需要被转化为一个机器友好的形式,使得计算机能够快速处理。一个很典型的表示方法是词汇的独热(one-hot)表示,也就是相当于每个词在词汇表里都有一个特定的位置。比如说有一个10000个词的词汇表,而“国王”是词汇表里的第500个词,那么“国王”就可以表示为一个一维向量,只有第500个位置是1,其他9999个位置都是0。但这种表示方法的问题很多,对语义相近但组成不同的词或句子如“国王”和“女王”,利用独热表示的向量内积,无法准确的判断两者之间的相似度。
2013年,Tomas Mikolov等人在谷歌开发了一个基于神经网络的词嵌入(word embedding)学习方法Word2Vec,不但大大缩短了词汇的表示向量的长度,而且能够更好的体现语义信息。通过这种嵌入方法可以很好的解决“国王”-“男人”=“女王”-“女人”这类问题。感兴趣的读者可以参考互联网上大量的关于词嵌入的资料。
计算机能够快速处理自然语言之后,传统的机器学习方法也进一步被深度学习所颠覆。相关算法在近年来的迭代速度非常快。以语言模型(Language Model)预训练方法为例,代表性方法有Transformer,ELMo,Open AI GPT,BERT,GPT2以及最新的XLNet。其中,Transformer于2017年6月被提出。ELMo的发表时间是2018年2月,刷新了当时所有的SOTA(State Of The Art)结果。
不到4个月,Open AI在6月,基于Transformer发布了GPT方法,刷新了9个SOTA结果。又过了4个月,横空出世的BERT又刷新了11个SOTA结果。2019年2月,Open AI发布的GPT2,包含15亿参数,刷新了11项任务的SOTA结果。而2019年6月,CMU 与谷歌大脑提出了全新 XLNet,在 20 个任务上超过了 BERT 的表现,并在 18 个任务上取得了当前最佳效果。
除了算法和算力的进步,还有一个重要的原因在于,以前的自然语言处理研究,更多的是监督学习,需要大量的标注数据,成本高且质量难以控制,而以BERT为代表的深度学习方法,直接在无标注的文本上做出预训练模型。在人类历史上,无监督数据是海量的,也就代表着这些模型的提升空间还有很大。2019年7月11日,Google AI发表论文,就利用了惊人的250亿平行句对的训练样本。其应用效果我们也拭目以待。
尝试用技术模拟人类的真实对话,在开放领域就是个伪命题。因为在人类的对话过程中,一句话中所表达出的信息,不只是文字本身,还包括世界观、情绪、环境、上下文、语音、表情、对话者之间的关系等。
比如说“今天天气不错”,在早晨拥挤的电梯中和同事说,在秋游的过程中和驴友说,走在大街上的男女朋友之间说,在倾盆大雨中对同伴说,很可能代表完全不同的意思。在人类对话中需要考虑到的因素包括:说话者和听者的静态世界观、动态情绪、两者的关系,以及上下文和所处环境等

而且,以上这些都不是独立因素,整合起来,才能真正反映一句话或者一个词所蕴含的意思。这就是人类语言的奇妙之处。同时,人类在交互过程中,并不是等对方说完一句话才进行信息处理,而是随着说出的每一个字,不断的进行脑补,在对方说完之前就很可能了解到其所有的信息。再进一步,人类有很强的纠错功能,在进行多轮交互的时候,能够根据对方的反馈,修正自己的理解,达到双方的信息同步。
在上一节中,我们也提到,自然语言处理技术很难解决推理问题。而推理是认知智能的重要组成部分。比如说对于问题“姚明的老婆的女儿的国籍是什么?”,一个可行的解决方案,就是通过大规模百科知识图谱来进行推理查询。
知识图谱被认为是从感知智能通往认知智能的重要基石。一个很简单的原因就是,没有知识的机器人不可能实现认知智能。图灵奖获得者,知识工程创始人Edward Feigenbaum曾经提到:“Knowledge is the power in AI system”。张钹院士也提到,“没有知识的AI不是真正的AI”。
拿上一节提到的GPT-2算法来看,即使其文章续写能力让人赞叹,也只是再次证明了足够大的神经网络配合足够多的训练数据,就能够产生强大的记忆能力。但逻辑和推理能力,仍然是无法从记忆能力中自然而然的出现的。学界和企业界都寄希望于知识图谱解决知识互连和推理的问题。那么什么是知识图谱?简单来说,就是把知识用图的形式组织起来。可能这样说还不够明白,我们举例子分别说下什么是知识,什么是图谱。
所谓知识,是信息的抽象,举一个简单的例子来说,226.1厘米,229厘米,都是客观存在的孤立的数据。此时,数据不具有任何的意义,仅表达一个事实存在。而“姚明臂展226.1厘米”, “姚明身高229厘米”,是事实型的陈述,属于信息的范畴。对于知识而言,是在更高层面上的一种抽象和归纳,把姚明的身高、臂展,及姚明的其他属性整合起来,就得到了对于姚明的一个认知,也可以进一步了解姚明的身高是比普通人更高的。
维基百科给出的关于知识的定义是:知识是人类在实践中认识客观世界(包括人类自身)的成果,它包括事实、信息的描述或在教育和实践中获得的技能。知识是人类从各个途径中获得得经过提升总结与凝练的系统的认识。
图谱的英文是graph,直译过来就是“图”的意思。在图论(数学的一个研究分支)中,图(graph)表示一些事物(objects)与另一些事物之间相互连接的结构。一张图通常由一些结点(vertices或nodes)和连接这些结点的边(edge)组成。Sylvester在1878年首次提出了“图”这一名词[7]。如果我们把姚明相关的“知识”用“图谱”构建起来

知识图谱是实现通用人工智能(Artificial General Intelligence)的重要基石。从感知到认知的跨越过程中,构建大规模高质量知识图谱是一个重要环节,当人工智能可以通过更结构化的表示理解人类知识,并进行互联,才有可能让机器真正实现推理、联想等认知功能。而构建知识图谱是一个系统工程

自顶向下的策略为专家驱动,根据应用场景和领域,利用经验知识人工为知识图谱定义数据模式,在定义本体的过程中,首先从最顶层的概念开始,然后逐步进行细化,形成结构良好的分类学层次结构;在定义好数据模式后,再将实体逐个对应到概念中。
自底向上的策略为数据驱动,从数据源开始,针对不同类型的数据,对其包含的实体和知识进行归纳组织,形成底层的概念,然后逐步往上抽象,形成上层的概念,并对应到具体的应用场景中。
知识图谱可以辅助各种智能场景下的应用。谷歌在2012年最早提出“Knowledge Graph”的概念,并将知识图谱用到搜索中,使得“搜索能直接通往答案”。知识图谱还能辅助智能问答、决策推理等应用场景。

最后,构建知识图谱的成本仍然较高。Heiko Paulheim在其文章《How much is a Triple? Estimating the Cost of Knowledge Graph Creation》中,给出了几个典型的知识图谱的构建成本。其中,上世纪80年代开始的也是最早的知识图谱项目CYC,平均构建一条陈述句和断言的成本是5.71美元,而随着自然语言处理和机器学习技术的进步,DBpedia构建每一条的成本降低到了1.85美分。即便如此,在真正工程化落地的时候,牵扯到多源数据的清洗整合,一个知识图谱项目的成本还是居高不下。
自然语言处理与知识图谱结合可以实现一定程度的推理,而知识图谱和深度学习结合可以实现一定程度的可解释性,自然语言处理和深度学习结合,诞生了BERT等强大的语言模型












 京公网安备 11010802041100号
京公网安备 11010802041100号