文章目录
- 一、调优相关
- 1.第一步:本地explain+线上查询
- 遇到的第一个坑:
- 遇到的第二个坑:
- 2.第二步:覆盖索引
- 3.第三步:联合索引
- 4.第四步:最左匹配原则
- 5.第五步:索引下推
- 6.唯一索引普通索引选择难题
- 7.第七步:前缀索引
- 8.第八步:条件字段函数操作
- 9.第九步:防止类型隐式转换
- 10.第十步:隐式字符编码转换
- 11.第十一步:flush
- 二、面试问题
- 1)B树和B+树的区别,为什么mysql使用B+树?
- 2)mysql有哪些存储引擎?
- 3)MyISAM和InnoDB的区别是什么?
- 4)什么叫回表?
- 5)什么叫聚簇索引?
- 6)什么是索引覆盖?怎么实现?
- 7)谈谈联合索引生效的条件和失效的条件?
- 8)什么是索引下推?
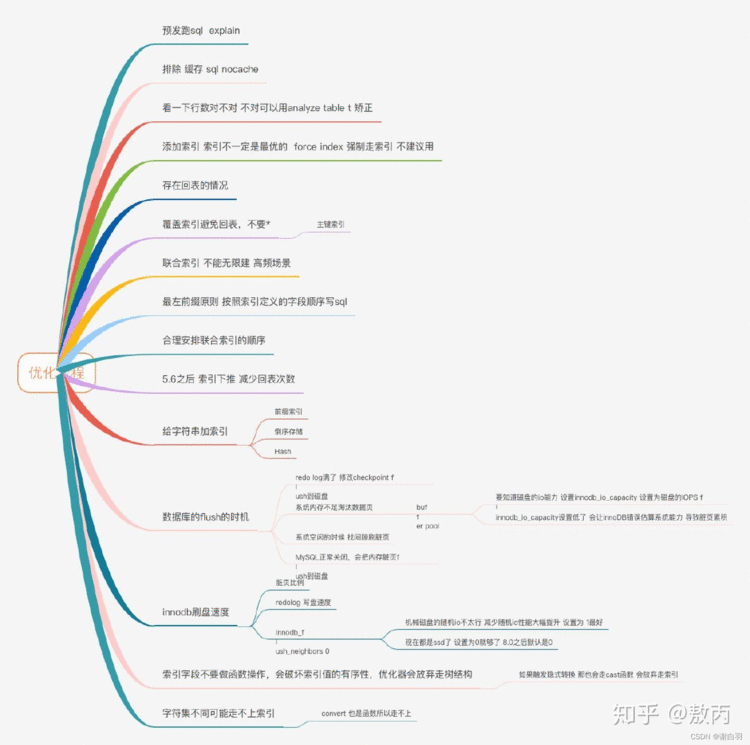
一、调优相关
1.第一步:本地explain+线上查询
在开发涉及SQL的业务都会去本地环境跑一遍SQL,用explain去看一下执行计划,看看分析的结果是否符合自己的预期(type是否为eq_ref、ref),用没用到相关的索引(possible_keys和key是不是想要的),然后再去线上环境跑一下看看执行时间(这里只有查询语句,修改语句也无法在线上执行)。

- eq_ref :对于前表的每一行,后表只有一行被扫描
- ref:对于前表的每一行,后表可能有多于一行的数据被扫描
遇到的第一个坑:
因为在MySQL8.0之前我们的数据库是存在缓存这样的情况的,我之前就被坑过,因为存在缓存,我发现我sql怎么执行都是很快,当然第一次其实不快但是我没注意到,以至于上线后因为缓存经常失效,导致rt(Response time)时高时低。
解决方法:SQL NoCache去跑SQL
原因:缓存失效比较频繁的原因就是,只要我们一对表进行更新,那这个表所有的缓存都会被清空,其实我们很少存在不更新的表。
遇到的第二个坑:
1)MySQL中数据的单位都是页,MySQL又采用了采样统计的方法,采样统计的时候,InnoDB默认会选择N个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面数,就得到了这个索引的基数。
2)我们数据是一直在变的,所以索引的统计信息也是会变的,会根据一个阈值,重新做统计。
解决方法:analyze table tablename 就可以重新统计索引信息了,所以在实践中,如果你发现explain的结果预估的rows值跟实际情况差距比较大,可以采用这个方法来处理。
1)如果走A索引要扫描100行,B所有只要20行,但是他可能选择走A索引
2)一般走错都是因为优化器在选择的时候发现,走A索引没有额外的代价,比如走B索引并不能直接拿到我们的值,还需要回到主键索引才可以拿到,多了一次回表的过程,这个也是会被优化器考虑进去的。
解决方法:还有一个方法就是force index强制走正确的索引,或者优化SQL,最后实在不行,可以新建索引,或者删掉错误的索引。
2.第二步:覆盖索引
1)说明:
可能需要回表这样的操作,那我们怎么能做到不回表呢?在自己的索引上就查到自己想要的,不要去主键索引查了。
-
如果在我们建立的索引上就已经有我们需要的字段,就不需要回表了,比如在电商里面,我们需要去商品表通过各种信息查询到商品id,id一般都是主键,可能sql类似这样:
select itemId from itemCenter where size between 1 and 6

-
因为商品id itemId一般都是主键,在size索引上肯定会有我们这个值,这个时候就不需要回主键表去查询id信息了。
-
由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
(覆盖索引一般针对的是辅助索引,整个査询结果只通过辅助索引就能拿到结果,不需要通过辅助索引树找到主键,再通过主键去主键索引树里获取其它字段值。这个辅助索引可以是组合索引)
举例传送门
假设你定义一个联合索引
CREATE INDEX idx_name_age ON user(name,age);
查询名称为 liudehua 的年龄:
mysql> select name, age from user where name = 'liudehua';
上述语句中,查找的字段 name 和 age 都包含在联合索引 idx_name_age 的索引树中,这样的查询就是覆盖索引查询。
3.第三步:联合索引
- 还是商品表举例,我们需要根据他的名称,去查他的库存,假设这是一个很高频的查询请求,你会怎么建立索引呢?
- 解决方法:
建立一个,名称和库存的联合索引,这样名称查出来就可以看到库存了,不需要查出id之后去回表再查询库存了,联合索引在我们开发过程中也是常见的,但是并不是可以一直建立的,大家要思考索引占据的空间。
4.第四步:最左匹配原则
最好能利用到现有的SQL最大化利用,像上面的场景,如果利用一个模糊查询 itemname like ’谢白羽%‘,这样还是能利用到这个索引的,而且如果有这样的联合索引,大家也没必要去新建一个商品名称单独的索引了。
指的是联合索引中,优先走最左边列的索引。对于多个字段的联合索引,也同理。如 index(a,b,c) 联合索引,则相当于创建了 a 单列索引,(a,b)联合索引,和(a,b,c)联合索引。
5.第五步:索引下推
select * from itemcenter where name like '谢%' and size=22 and age = 20;
-
所以这个语句在搜索索引树的时候,只能用 “谢”,找到第一个满足条件的记录ID1,当然,这还不错,总比全表扫描要好。
-
在MySQL 5.6之前,只能从ID1开始一个个回表,到主键索引上找出数据行,再对比字段值。

-
而MySQL 5.6 引入的索引下推优化(index condition pushdown), 可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。

6.唯一索引普通索引选择难题
要判断表中是否存在这个数据,而这必须要将数据页读入内存才能判断,如果都已经读入到内存了,那直接更新内存会更快,就没必要使用change buffer了。因此,唯一索引的更新就不能使用change buffer,实际上也只有普通索引可以使用。
- change buffer的大小,可以通过参数innodb_change_buffer_max_size来动态设置,这个参数设置为50的时候,表示change buffer的大小最多只能占用buffer pool的50%。将数据从磁盘读入内存涉及随机IO的访问,是数据库里面成本最高的操作之一.change buffer因为减少了随机磁盘访问,所以对更新性能的提升是会很明显的。
7.第七步:前缀索引
- 我们存在邮箱作为用户名的情况,每个人的邮箱都是不一样的,那我们是不是可以在邮箱上建立索引,但是邮箱这么长,我们怎么去建立索引呢?
- MySQL是支持前缀索引的,也就是说,你可以定义字符串的一部分作为索引。默认地,如果你创建索引的语句不指定前缀长度,那么索引就会包含整个字符串。
但是:
但是前缀索引,即使你的联合索引已经包涵了相关信息,他还是会回表,因为他不确定你到底是不是一个完整的信息,就算你是www.aobing@mogu.com一个完整的邮箱去查询,他还是不知道你是否是完整的,所以他需要回表去判断一下。
解决方法:
你可以substring()函数截取掉前面的,然后建立索引。hash,把字段hash为另外一个字段存起来,每次校验hash就好了,hash的索引也不大。
8.第八步:条件字段函数操作
- 对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。
- 这个时候大家可以用一些取巧的方法,比如 select * from tradelog where id + 1 = 10000 就走不上索引,select * from tradelog where id = 9999就可以。
9.第九步:防止类型隐式转换
select * from t where id = 1
10.第十步:隐式字符编码转换
- 还是一样的问题,如果两个表的字符集不一样,一个是utf8mb4,一个是utf8,因为utf8mb4是utf8的超集,所以一旦两个字符比较,就会转换为utf8mb4再比较。
- 转换的过程相当于加了CONVERT(id USING utf8mb4)函数,那又回到上面的问题了,用到函数就用不上索引了。
- 还有大家一会可能会遇到mysql突然卡顿的情况,那可能是MySQLflush了。
11.第十一步:flush
-
redo log大家都知道,也就是我们对数据库操作的日志,他是在内存中的,每次操作一旦写了redo log就会立马返回结果,但是这个redo log总会找个时间去更新到磁盘,这个操作就是flush。
-
Innodb刷脏页控制策略,我们每个电脑主机的io能力是不一样的,你要正确地告诉InnoDB所在主机的IO能力,这样InnoDB才能知道需要全力刷脏页的时候,可以刷多快。
-
这就要用到innodb_io_capacity这个参数了,它会告诉InnoDB你的磁盘能力,这个值建议设置成磁盘的IOPS,磁盘的IOPS可以通过fio这个工具来测试。正确地设置innodb_io_capacity参数,可以有效的解决这个问题。
-
补充:这中间有个有意思的点,刷脏页的时候,旁边如果也是脏页,会一起刷掉的,并且如果周围还有脏页,这个连带责任制会一直蔓延,这种情况其实在机械硬盘时代比较好,一次IO就解决了所有问题,

二、面试问题
1)B树和B+树的区别,为什么mysql使用B+树?
1)B树:
①一个节点有多个元素
②整个树都是排好序的
2)B+树:
①叶子节点是有指针的
②一个节点有多个元素
(用这种存储结构来存储大量数据的情况下呢,它的整体高度相比二叉树来说比较低,而对于数据库来说,所有的数据存储必然是存储在磁盘上的而磁盘io的效率事件上是很低的,特别是随机磁盘的一个情况下效率更低,所以树的高度决定磁盘io一个次数,磁盘io次数越少,那么对性能的提升就会越大,采用b树作为索引存储结构的原因,)
③整个树都是排好序的
③非叶子节点在叶子节点的元素都冗余了一份

2)mysql有哪些存储引擎?
①InnoDB是mysql默认事物型引擎,也是最广泛的存储引擎,被设计来处理大量短期事务
②MyISAM是5.1及之前版本的默认存储引擎,但是不支持事务和行级锁,且崩溃后无法安全恢复。同时MyISAM对表加锁,很容易因为表锁的问题导致典型的性能问题。
③Memory引擎:至少比MyISAM表要快一个数量级,数据文件是存储在内存中,查找和映射比较快。表结构在重启后还会保留,但是数据会丢失。
④Archive引擎:只支持INSERT和SELECT操作,会缓存所有的写并利用zlib对插入的行进行压缩,所以比MyISAM表的磁盘IO更少。但是每次SELECT查询都需要执行全表扫描,所以一般是用于日志或数据采集类存储
⑤CSV引擎:将普通的CSV文件作为MYSQL的表来处理,但这个表不支持索引,但是可以作为数据交换的机制
3)MyISAM和InnoDB的区别是什么?
①InnoDB支持事务,MyISAM不支持事务
②InnoDB可以包含外键,但是MyISAM不支持
③InnoDB是聚簇索引,MyISAM是非聚簇索引
InnoDB使用辅助索引的时候,如果主键很大,那么其他索引也会很大,因为辅助索引需要两次查询,他存的是主键的信息,然后再根据主键去查询数据
④InnoDB不保存行数,数表行时是全表扫描
⑤InnoDB最小锁粒度是行锁,MyISAM最小锁粒度是表锁
4)什么叫回表?
一次性select不能拿到所有列的数据,还需要到表中再去查找列的数据,就叫回表
5)什么叫聚簇索引?
比如说以主键建立的B+树,叶子节点存储的是对应行的数据,而不是指向另外一块内存(该内存存储对应行数据)的指针,存指针叫做非聚簇索引(或叫辅助索引)
6)什么是索引覆盖?怎么实现?
定义:执行某个查询语句,在一棵索引树上就能获取SQL所需的所有列数据,无需回表
怎么实现:将查询的字段建立到联合索引里面去
7)谈谈联合索引生效的条件和失效的条件?
1、创建联合索引时应仔细考虑列的顺序(知道姓和名更为有用)
2、避免索引失效条件:
①不在索引列上做任何操作,包括不限于计算、函数、自动或手动类型转换
②存储引擎不能使用索引范围条件右侧的列(左侧优先)
③尽量使用索引覆盖(索引和查询列一致)
④mysql在使用(!&#61;,>,<)的时候无法使用索引
⑤is null &#xff0c;is not null也无法使用索引
⑥like以通配符开头&#xff0c;即’%ABC’
8&#xff09;什么是索引下推&#xff1f;
根据条件查询的过程中&#xff0c;再返回server之前就根据比如说联合索引查询的条件过滤了一部分数据&#xff0c;这样在返回数据库server层的时候就减少了回表的次数&#xff08;5.6及5.6以上版本&#xff09;
传送门








 京公网安备 11010802041100号
京公网安备 11010802041100号