摘要
本文由以数据之名分享,正所谓“泰山不嫌细土,故成其大;大海不择小流,故成其深”。我们在生活中要总结“以小见大,以微知著”的心得,下面让我们跟着小编的步伐,从了解MyCAT线程模型的微小细节,来掌握MyCAT性能调优的强大本领。
01
—
MyCAT线程模型
02
—
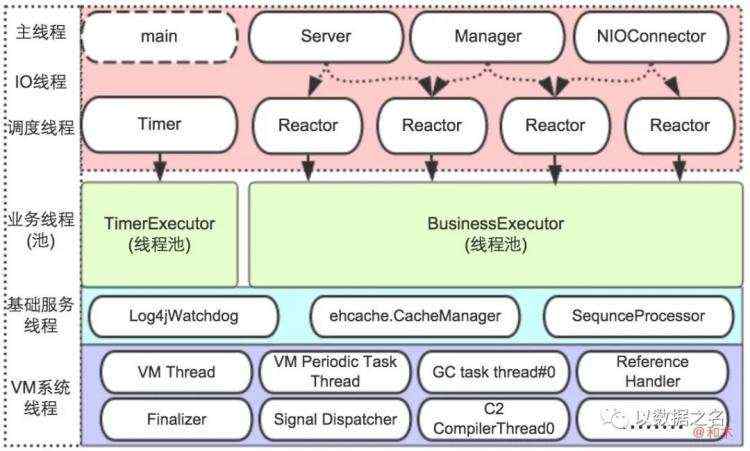
MyCAT线程介绍
Timer单线程仅仅负责调度,任务的具体动作交给timerExecutor。
默认大小N=2
任务通过timer单线程和timerExecutor线程池共同完成。这个1+N的设计方式比较巧妙!
但是timerExecutor跟aioExecutor大小默认一样,不太合理,定时任务没有那么大的运算量。
一个线程,负责作为客户端连接MySQL的主动连接事件。
一个线程,负责作为服务端接收来自业务系统的连接事件。
一个线程,负责作为服务端接收来自管理系统的连接事件。
默认个数N=processor size,通道建立连接后处理NIO读写事件。
由于写是采用通道空闲时其它线程直接写,只有写繁忙时才会注册写事件,再由NIOReactor分发。所以NIOReactor主要处理读操作。
默认大小N=processor size,任务队列采用的LinkedTransferQueue。
所有的NIOReactor把读出的数据交给BusinessExecutor做下一步的业务操作。
全局只有一个BusinessExecutor线程池,所有链接通道随机分成多个组,然后每组的多个通道共享一个Reactor,所有的Reactor读取且解码后的数据下一步处理操作,又共享一个BusinessExecutor线程池。
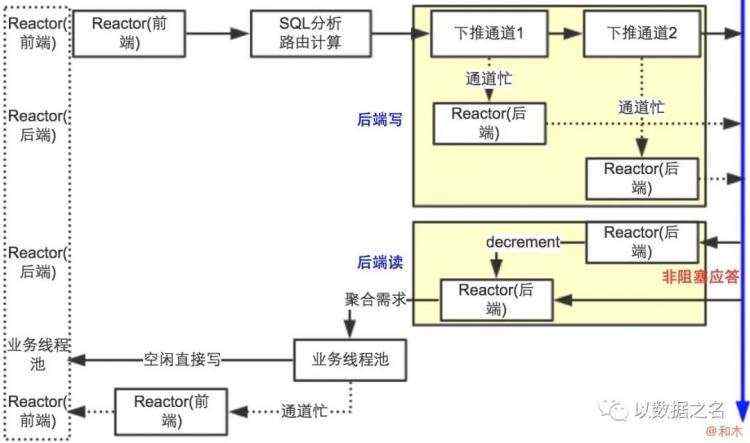
03
—
MyCAT性能调优
Linux主机的网络性能优化,mycat所在服务器多网卡绑定,bond技术,增加网络吞吐量。
TCP的性能取决于几方面因素,最重要的是链接带宽(link bandwidth)(报文在网络上传输的速率)和往返时间(round-trip time)或RTT(发送报文与接收到另一端的响应之间的延时)。这两个值确定称为BDP(Bandwidth Delay Prod-uct)的内容。BDP给出一种简单的方法计算理论上最优的TCP Socket缓冲区大小(其中保存排队等待传输和等待应用程序接收的数据)。
缓冲区太小,TCP窗口就不能完全打开,这会限制性能;缓冲区太大,则会浪费宝贵的内存资源;设置的缓冲区大小合适,就可完全利用可用带宽。
BDP计算公式:BDP=link bandwidth×RTT若应用程序通过一个100MB/s的局域网通信,其RRT为500ms,则BDP为:50MB/sx0.050/ 8625M=625KB。Linux2.6默认的TCP窗口大小是110KB,这将连接的带宽限制为22M/S,计算方法如下:throughput=window_size/RTT110 KB/0.050=2.2 MB/s使用上面计算的窗口大小,得到带宽为12.5 MB/s,即:625 KB/0 050=12.5 MB/s
应用可以根据自己的Socket计算最优的缓冲区大小。使用SO_SNDBUF和SO_RCVBUF选项来调整发送和接收缓冲区的大小。
在Linux 2.6内核中.发送缓冲区的大小由调用用户定义,而接收缓冲区会自动加倍。通过计算合理设置缓冲区的大小,Socket网络传输带宽的资源将得到充分利用,从而提高了传输性能。
3.2、JVM调优
MyCAT的JVM相关配置是在warrper启动中配置例如:
Linux下 startup_nowrap.sh
其他版本都会在对应的配置文件中配置。
3.3、JVM结构
JVM内存结构由堆、栈、本地方法栈、方法区等部分组成,另外JVM分别对新生代和旧生代采用不同的垃圾回收机制。
JVM内存结构,它是由堆、栈、本地方法栈、方法区等部分组成,结构图如下所示。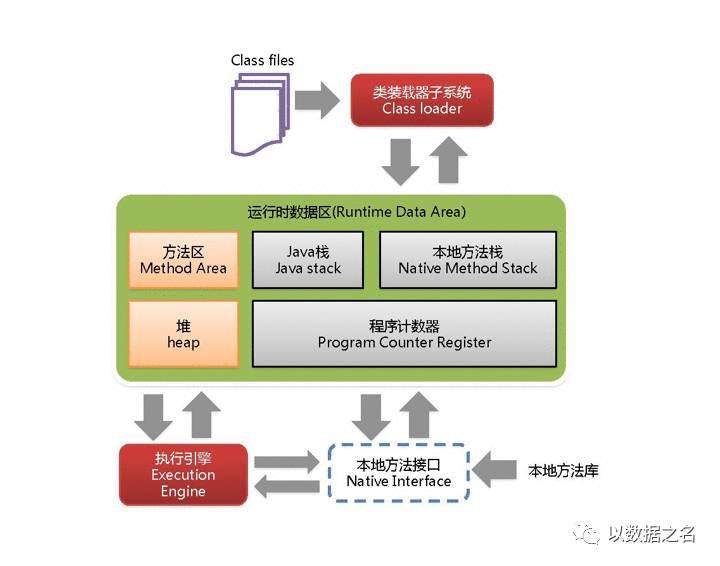
堆
所有通过new创建的对象的内存都在堆中分配,其大小可以通过-Xmx和-Xms来控制。堆被划分为新生代和旧生代,新生代又被进一步划分为Eden和Survivor区,最后Survivor由FromSpace和ToSpace组成,结构图如下所示:
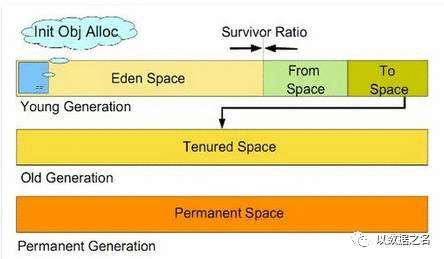
新生代。新建的对象都是用新生代分配内存,Eden空间不足的时候,会把存活的对象转移到Survivor中,新生代大小可以由-Xmn来控制,也可以用-XX:SurvivorRatio来控制Eden和Survivor的比例旧生代。用于存放新生代中经过多次垃圾回收仍然存活的对象
栈
每个线程执行每个方法的时候都会在栈中申请一个栈帧,每个栈帧包括局部变量区和操作数栈,用于存放此次方法调用过程中的临时变量、参数和中间结果
本地方法栈
用于支持native方法的执行,存储了每个native方法调用的状态
方法区
存放了要加载的类信息、静态变量、final类型的常量、属性和方法信息。JVM用持久代(PermanetGeneration)来存放方法区,可通过-XX:PermSize和-XX:MaxPermSize来指定最小值和最大值。
对JVM内存的系统级的调优主要的目的是减少GC的频率和Full GC的次数,过多的GC和Full GC是会占用很多的系统资源(主要是CPU),影响系统的吞吐量。特别要关注Full GC,因为它会对整个堆进行整理,导致Full GC一般由于以下几种情况:
旧生代空间不足。
调优时尽量让对象在新生代GC时被回收、让对象在新生代多存活一段时间和不要创建过大的对象及数组避免直接在旧生代创建对象。
Pemanet Generation空间不足。
增大Perm Gen空间,避免太多静态对象。
统计得到的GC后晋升到旧生代的平均大小大于旧生代剩余空间。
控制好新生代和旧生代的比例。
System.gc()被显示调用。
垃圾回收不要手动触发,尽量依靠JVM自身的机制。
调优手段主要是通过控制堆内存的各个部分的比例和GC策略来实现,下面来看看各部分比例不良设置会导致什么后果。
新生代设置过小
一是新生代GC次数非常频繁,增大系统消耗;二是导致大对象直接进入旧生代,占据了旧生代剩余空间,诱发Full GC。
新生代设置过大
一是新生代设置过大会导致旧生代过小(堆总量一定),从而诱发Full GC;二是新生代GC耗时大幅度增加
一般说来新生代占整个堆1/3比较合适。
Survivor设置过小
导致对象从eden直接到达旧生代,降低了在新生代的存活时间。
Survivor设置过大
导致eden过小,增加了GC频率。
另外,通过-XX:MaxTenuringThreshold=n来控制新生代存活时间,尽量让对象在新生代被回收
内存管理和垃圾回收
可知新生代和旧生代都有多种GC策略和组合搭配,选择这些策略对于我们这些开发人员是个难题,JVM提供两种较为简单的GC策略的设置方式。
吞吐量优先
JVM以吞吐量为指标,自行选择相应的GC策略及控制新生代与旧生代的大小比例,来达到吞吐量指标。这个值可由-XX:GCTimeRatio=n来设置。
暂停时间优先
JVM以暂停时间为指标,自行选择相应的GC策略及控制新生代与旧生代的大小比例,尽量保证每次GC造成的应用停止时间都在指定的数值范围内完成。这个值可由-XX:MaxGCPauseRatio=n来设置。
最后汇总一下JVM常见配置。
堆设置-Xms:初始堆大小 -Xmx:最大堆大小。-XX:NewSize=n:设置年轻代大小 -XX:NewRatio=n:设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4。-XX:SurvivorRatio=n:年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5。-XX:MaxPermSize=n:设置持久代大小 收集器设置 -XX:+UseSerialGC:设置串行收集器。-XX:+UseParallelGC:设置并行收集器 -XX:+UseParalledlOldGC:设置并行年老代收集器 。-XX:+UseConcMarkSweepGC:设置并发收集器 垃圾回收统计信息 -XX:+PrintGC。-XX:+PrintGCDetails -XX:+PrintGCTimeStamps。-Xloggc:filename 并行收集器设置 -XX:ParallelGCThreads=n:设置并行收集器收集时使用的CPU数。并行收集线程数。-XX:MaxGCPauseMillis=n:设置并行收集最大暂停时间 -XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)。并发收集器设置-XX:+CMSIncrementalMode:设置为增量模式。适用于单CPU情况。-XX:ParallelGCThreads=n:设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数。系统相关 -XX:+UseNUMA numa是一个CPU的特性。SMP架构下,CPU的核是对称,但是他们共享一条系统总线。所以CPU多了,总线就会成为瓶颈。在NUMA架构下,若干CPU组成一个组,组之间有点对点的通讯,相互独立。启动它可以提高性能。NUMA需要硬件,操作系统,JVM同时启用,才能启用。Linux可以用numactl来配置numa,JVM通过-XX:+UseNUMA来启用。-XX:LargePageSizeInBytes=128m 启用大内存页。
现在一个操作系统默认页是4K。如果你的heap是4GB,就意味着要执行1024*1024次分配操作。所以最好能把页调大。这个配额设计操作系统,单改Jvm是不行的。Linux上的配置有点复杂,不详述。在Java1.6中UseLargePages是默认开启的,LasrgePageSzieInBytes被设置成了4M。笔者看到一些情况下配置成了128MB,在官方的性能测试中更是配置到256MB。
官方JVM参数说明:
http://www.oracle.com/technetwork/java/javase/tech/vmoptions-jsp-140102.html
MyCAT调优参数都配置在server.xml。本小节我们主要讨论如下两个参数块:
1. processors数值的影响范围2. buffer和buffer队列大小
3.4.1、processors
定义了如下几个类的实例个数:
1. NIOProcessor2. NIOReactorPool3. AsynchronousChannelGroup
NIOProcessor类,持有所有的前后端连接,定期的空闲检查和写队列检查。要完成这个动作。Mycat是通过遍历NIOProcessor持有的所有连接来完成的。
所以,可以适当的根据系统性能调整NIOProcessor的个数。使得前、后段连接可以均匀的分布在每个NIOProcessor上。这样,就可以加快每次的空闲检查和写队列检查。快速的将空闲的连接关闭,减轻服务器的内存使用量。
NIOReactor是NIO中具体执行selector的类,当满足感兴趣的事件发生的时候,他就通知上次逻辑进行具体的处理。所以,NIOReactor的个数据等于具体事件处理器的个数。如果系统的配置允许的话,应该尽可能的增大NIOReactor的数量。默认值是系统核心数。
AsynchronousChannelGroup是AIO中必须提供的一个组成部分。AsynchronousChannelGroup根据processors的数值,确定实例数和channelGroup组内的线程池大小。后端AIO连接循环取AsynchronousChannelGroup数组中的实例。所以。如果是在AIO模式下使用Mycat的话,调整这个参数也是有必要的。默认值是系统核心数。
最后,可以根据自己硬件的实际情况,配置processors的具体大小。例如,配置processor的个数为16:
server.xml文件中定义<property name="processors">16property>
3.4.2、buffer pool
因为所有的NIOProcessor共享一个buffer pool,而我们在server.xml中提到过:
BufferPool的总长度 = bufferPool / bufferChunk
我们可以使用show @@processor
命令列出所有的processor状态,查看列:FREE_BUFFER、TOTAL_BUFFER、BU_PERCENT。
server.xml文件中定义<property name="processorBufferPool">20480000property>
另一个buffer pool是线程内buffer pool,这个值可以根据processors的数值计算出来。具体看server.xml配置详解。
首先MySQL要绝对避免使用Swap内存,网上有多种办法,可以参考。
这里是MySQL5.6及以上的调优参数,主要是提升多个database/table的写入和查询性能:
[mysqld]
当Order By 或者Group By等需要用到结果集时,参数中设置的临时表的大小小于结果集的大小时,就会将该表放在磁盘上,这个时候在硬盘上的IO要比内销差很多。所耗费的时间也多很多,Mysql 会取min(tmp_table_size, max_heap_table_size)的值,因此两个设置为一致。除非是大量使用内存表的情况,此时max_heap_table_size要设置很大。
#max_heap_table_size=200M#tmp_table_size=200M
下面这部分是Select查询结果集的缓存控制,
query_cache_limit 表示缓存的Select结果集的最大字节数,这个可以限制哪些结果集缓存, query_cache_min_res_unit 表示结果集缓存的内存单元大小,若需要缓存的SQL结果集很小,比如返回几条记录的,则query_cache_min_res_unit越小,内存利用率越高
query_cache_size表示总共用多少内存缓存Select结果集,
query_cache_type则是控制是否开启结果集缓存,默认0不开启,1开启,2为程序控制方式缓存,比如SELECT SQL_CACHE …这个语句表明此查询SQL才会被缓存,对于执行频率比较高的一些查询SQL,进行指定方式的缓存,效果会最好。
FLUSH QUERY CACH 命令则清理缓存,以更好的利用它的内存,但不会移除缓存,
RESET QUERY CACHE 使命从查询缓存中移除所有的查询结果。
#query_cache_type =1#query_cache_limit=102400#query_cache_size = 2147483648#query_cache_min_res_unit=1024
MySQL最大连接数,这个通常在1000-3000之间比较合适,根据系统硬件能力,需要对Linux打开的最大文件数做修改
#max_connections =2100
下面这个参数是InnoDB最重要的参数,是缓存innodb表的索引,数据,插入数据时的缓冲,尽可能的使用内存缓存,对于MySQL专用服务器,通常设置操作系统内存的70%-80%最佳,但需要注意几个问题,不能导致system的swap空间被占用,要考虑你的系统使用多少内存,其它应用使用的内在,还有你的DB有没有myisa引擎,最后减去这些才是合理的值。
#innodb_buffer_pool_size=4G
innodb_additional_mem_pool_size 除了缓存表数据和索引外,可以为操作所需的其他内部项分配缓存来提升InnoDB的性能。这些内存就可以通过此参数来分配。推荐此参数至少设置为2MB,实际上,是需要根据项目的InnoDB表的数目相应地增加
#innodb_additional_mem_pool_size=16M
innodb_max_dirty_pages_pct ,如果设置过大,内存也很大或者服务器压力很大,那么效率很降低;如果设置过小,那么硬盘的压力会增加.
#innodb_max_dirty_pages_pct=90
MyISAM表引擎的数据库会分别创建三个文件:表结构、表索引、表数据空间。我们可以将某个数据库目录直接迁移到其他数据库也可以正常工作。
然而当你使用InnoDB的时候,一切都变了。InnoDB 默认会将所有的数据库InnoDB引擎的表数据存储在一个共享空间中:ibdata1,这样就感觉不爽,增删数据库的时候,ibdata1文件不会自动收缩,单个数据库的备份也将成为问题。
通常只能将数据使用mysqldump 导出,然后再导入解决这个问题。innodb_file_per_table=1可以修改InnoDB为独立表空间模式,每个数据库的每个表都会生成一个数据空间。
独立表空间
优点:
每个表都有自已独立的表空间。
每个表的数据和索引都会存在自已的表空间中。
可以实现单表在不同的数据库中移动。
空间可以回收(drop/truncate table方式操作表空间不能自动回收)
对于使用独立表空间的表,不管怎么删除,表空间的碎片不会太严重的影响性能,而且还有机会处理。
缺点:
单表增加比共享空间方式更大。
结论:
共享表空间在Insert操作上有一些优势,但在其它都没独立表空间表现好。
实际测试,当一个MySQL服务器作为MyCAT分片表存储服务器使用的情况下,单独表空间的访问性能要大大优于共享表空间,因此强烈建议使用独立表空间。
当启用独立表空间时,由于打开文件数也随之增大,需要合理调整一下 innodb_open_files 、table_open_cache等参数。
#innodb_file_per_table=1#innodb_open_files=1024#table_open_cache=1024
Undo Log 是为了实现事务的原子性,在MySQL数据库InnoDB存储引擎中,还用Undo Log来实现多版本并发控制(简称:MVCC)。
Undo Log的原理很简单,为了满足事务的原子性,在操作任何数据之前,首先将数据备份到Undo Log,然后进行数据的修改。如果出现了错误或者用户执行了 ROLLBACK语句,系统可以利用Undo Log中的备份将数据恢复到事务开始之前的状态。
因此Undo Log的IO性能对于数据插入或更新也是很重要的一个因素。于是,从MySQL 5.6.3开始,这里出现了重大优化机会:
As of MySQL 5.6.3, you can store InnoDB undo logs in one or more separate undo tablespaces outside of the system tablespace. This layout is different from the default configuration where the undo log is part of the system tablespace. The I/O patterns for the undo log make these tablespaces good candidates to move to SSD storage, while keeping the system tablespace on hard disk storage. #innodb_rollback_segments参数在此被重命名为innodb_undo_logs
因此总共有3个控制参数:
innodb_undo_tablespaces 表明总共多少个undo表空间文件,
innodb_undo_logs 定义在一个事务中innodb使用的系统表空间中回滚段的个数。如果观察到同回滚日志有关的互斥争用,可以调整这个参数以优化性能,默认是128最大值,官方建议先设小,若发现竞争,再调大
*注意*:这里的参数是要安装MySQL时候初始化InnoDB引擎设置的,innodb_undo_tablespaces参数无法后期设定。
#innodb_undo_tablespaces=128#innodb_undo_directory= SSD硬盘或者另外一块硬盘,跟数据分开#innodb_undo_logs=64
下面是InnoDB的日志相关的优化选项:
innodb_log_buffer_size 这是 InnoDB 存储引擎的事务日志所使用的缓冲区。类似于 Binlog Buffer,InnoDB 在写事务日志的时候,为了提高性能,也是先将信息写入 Innofb Log Buffer 中,当满足 innodb_flush_log_trx_commit 参数所设置的相应条件(或者日志缓冲区写满)之后,才会将日志写到文件(或者同步到磁盘)中。
innodb_log_buffer_size 不用太大,因为很快就会写入磁盘。
innodb_flush_log_trx_commit 参数设置参考如下:
0:log buffer中的数据将以每秒一次的频率写入到log file中,且同时会进行文件系统到磁盘的同步操作;
1:在每次事务提交的时候将log buffer 中的数据都会写入到log file,同时也会触发文件系统到磁盘的同步;
2:事务提交会触发log buffer 到log file的刷新,但并不会触发磁盘文件系统到磁盘的同步。此外,每秒会有一次文件系统到磁盘同步操作。
对于非关键交易型数据,采用2即可以满足高性能的日志操作,若要非常可靠的数据写入保证,则需要设置为1,此时每个commit都导致一次磁盘同步,性能下降。
innodb_log_file_size 此参数确定数据日志文件的大小,以M为单位,更大的设置可以提高性能,但也会增加恢复故障数据库所需的时间。
innodb_log_files_in_group 分割多个日志文件,提升并行性。
innodb_autoextend_increment 对于大批量插入数据也是比较重要的优化参数(单位是M)
#innodb_log_buffer_size=16M#innodb_log_file_size =256M#innodb_log_files_in_group=8#innodb_autoextend_increment=128#innodb_flush_log_at_trx_commit=2
#建议用GTID的并行复制,需要主从复制的情况下,可以设置以下相关参数:
#gtid_mode = ON#binlog_format = mixed#enforce-gtid-cOnsistency=true#log-bin=binlog#log-slave-updates=true
04
—
致谢
本文大量参考了MyCAT官方语雀文档(https://www.yuque.com/ccazhw),感激之情溢于言表!小编近期会继续写Redis、MySQL、Jvm和数据仓库、数据湖等相关的技术文章,欢迎联系小编投稿您的原创文章!

01|数据库专题
MySQL围城之困第一篇
MySQL破冰之旅第二篇
MySQL踏浪之途第三遍
MySQL主从复制部署实战
MyCAT前世因缘第一篇
MyCAT今生有约第二篇
无Hive,不数仓
HBase奇妙探索第一篇
基于TiDB构建高性能综合数据服务平台
TiDB Binary 多节点集群模式部署
02|Kettle插件专题
Kettle插件开发之Splunk篇
Kettle插件开发之Elasticsearch篇
Kettle插件开发之KafkaConsumerAssignPartition篇
“以消息之名”构建KafkaProducer篇
Kettle插件开发之KafkaConsumer篇
Kettle插件开发之KafkaConsumerAssignPartition篇
Kettle插件开发之MQToSQL篇
Kettle插件开发之Redis篇
03|方法论专题
金融数据仓库之分层命名规范
Kafka核心概念剖析
基于Kettle快速构建基础数据仓库平台
一入数据深似海,集市仓库湖中台
张无忌VS涨污机
BI选型哪家强,以数据之名挑大梁
数据科学家能力发展路线图
虽小编一己之力微弱,但读者众星之光璀璨。小编敞开心扉之门,还望倾囊赐教原创之文,期待之心满于胸怀,感激之情溢于言表。一句话,欢迎联系小编投稿您的原创文章!









 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有