本文是博客:https://pyimagesearch.com/2022/04/04/introduction-to-the-yolo-family/ 的翻译。
好吧!其实在这里面并没有太多细节的信息,只是像个简单的介绍。但是,这激励我,后续会继续研究下 PP-YOLO系列(PP-YOLO,PP-YOLOv2, PP-YOLOE);Scaled-YOLOv4和Anchor-free的YOLOX。当然,本文并没有覆盖所有的YOLO模型,未来我会继续增加内容。
目录
阅读收获
介绍YOLO家族
介绍目标检测
挑战
目标检测的历史
什么是单级目标检测器?
YOLOv1
YOLOv2
YOLOv3
YOLOv4
YOLOv5
mosaic data augmentation
定量benchmark
YOLOv5 Nano 发布
YOLOv5n与YOLOv4-Tiny对比
PP-YOLO
PaddleDetection
PP-YOLO性能
PP-YOLO架构
技巧和技术的选择
结果
消融研究
Scaled-YOLOv4
什么是模型缩放?
在 YOLOv4上改进的Scaled-YOLOv4
Scaled-YOLOv4设计
CSP-ized YOLOv4
扩展 YOLOv4-Tiny 模型
扩展YOLOv4-CSP模型
数据增强
PP-YOLOv2
回顾PP-YOLO
改进的选择
YOLOX
YOLOX-Darknet53
YOLOv3-Baseline
Decoupled Head
强大的数据增强
Anchor-Free检测
Multi-Positives
Other Backbones
Modified CSPNet in YOLOv5
Tiny and Nano Detectors
总结
引文信息
参考
目标检测是计算机视觉研究的重要课题之一。大多数计算机视觉问题都涉及到检测视觉对象类别,如行人、汽车、公共汽车、人脸等。这一领域不仅局限于学术界,而且在视频监控、医疗保健、车载传感和自动驾驶等领域具有潜在的现实商业用例。
许多用例,特别是自主驾驶,都要求高精度和实时推理速度。因此,选择一个对象检测器,适合的速度和准确性成为必不可少的法案。YOLO (You Only Look Once)是一个单级对象检测器,用于实现两个目标(即速度和准确性)。今天,我们将通过涵盖所有YOLO变体(如YOLOv1, YOLOv2,…,YOLOX, YOLOR)来介绍YOLO家族。
从一开始,目标检测领域已经得到了显著的发展,最先进的体系结构在各种测试数据集上都得到了很好的泛化。但是,要理解这些当前最好的架构背后的魔力,有必要了解这一切是如何开始的,以及我们在YOLO大家庭中已经走了多远。
在目标检测中有三类算法:
今天,我们将讨论YOLO对象检测系列,它属于单阶段深度学习算法。
我们相信这是一篇独一无二的博客文章,一篇文章涵盖了所有的YOLO变体,这将帮助你深入了解每种变体,并可能帮助你为你的项目选择最佳的YOLO版本。
这节课是我们关于YOLO对象检测器的7部分系列的第一个教程:
为了了解 YOLO 家族在检测图像中的物体方面是如何进化的,请保持阅读。
回忆一下,在图像分类中,目标是回答“图像中有什么?”,其中模型试图通过给图像指定一个特定的标签来理解整个图像。
一般来说,我们处理的是图像分类中只有一个对象的情况。如图1所示,我们有一个圣诞老人和其他一些对象,但主要对象是圣诞老人,它被正确分类的概率为98%。太好了。在某些情况下,比如这个例子,当一个图像描述了一个单一的对象,分类就足以回答我们的问题。

Figure 1: Image classified as Santa with 98% confidence (source).
然而,在很多情况下,我们无法通过一个标签来判断图像中的内容,而图像分类不足以帮助回答这个问题。例如,考虑图2,其中模型检测三个对象:两个人和一个棒球手套,不仅如此,它还识别每个对象的位置。这就是所谓的目标检测。

Figure 2: Examples of object detection using Single Shot Detectors (SSD) (source).
另一个重要的object detection 用例是自动车牌识别,如图3所示。现在问你自己一个问题,如果你不知道车牌的位置,你如何识别车牌的字母和数字?当然,首先,你需要用物体检测器来识别车牌的位置,然后应用第二种算法来识别数字。
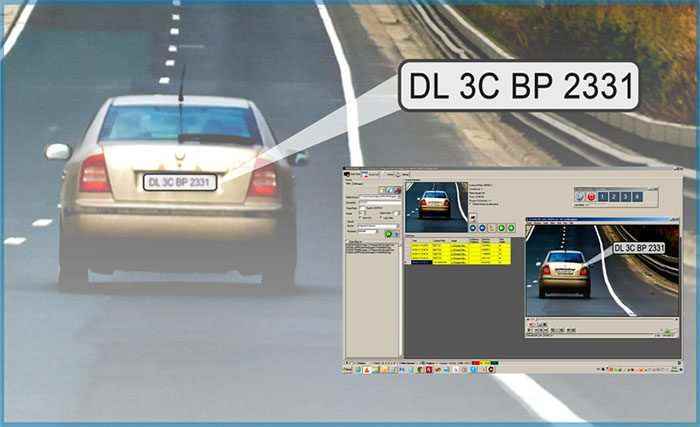
Figure 3: An example of a real-time Automatic Number Plate Recognition system (source: Chem on Pinterest).
目标检测图像分析包括分类和定位两个任务,用于分析图像中可能存在多个对象的更真实的情况。因此,目标检测是一个两步的过程; 第一步是找到物体的位置。
第二步是把这些bounding boxes分成不同的类别,因为这个目标检测bounding boxes存在所有与图像分类相关的问题。此外,它还面临着定位和执行速度的挑战。

图4: 一大群人在体育场观看比赛 (source).

Figure 5: Six breeds of dogs (source).
为了理解类的不平衡是如何在目标检测中造成问题的,考虑一个包含很少主要目标的图像。图像的其余部分被背景填充。因此,该模型将查看图像(数据集)中的许多区域,其中大多数区域被认为是负样本的。由于这些负样本,模型没有学到任何有用的信息,并且可能会淹没整个模型的训练。
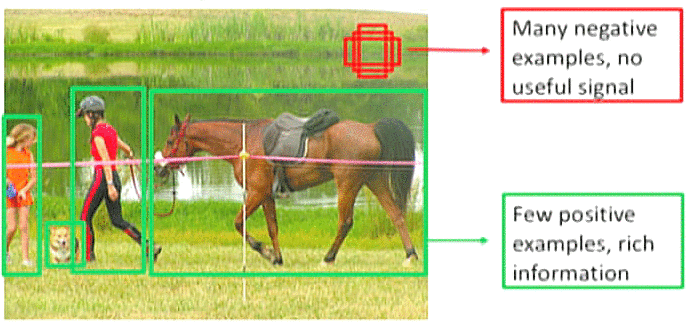
Figure 6: Many negative background examples and few positive foreground examples (source).
许多其他挑战与目标检测相关,如遮挡、变形、视点变化、光照条件和实时检测的基本速度(许多工业应用都需要)。
目标检测是计算机视觉中最关键和最具挑战性的问题之一,它的发展在过去的十年中创造了一个历史。然而,这方面的进展是显著的;每年,研究界都达到一个新的最先进的benchmark。当然,如果没有深度神经网络和NVIDIA gpu的强大计算能力,这一切都不可能实现。
在目标检测的历史上,有两个截然不同的时代:
这两个时代之间的区别在图7中也很明显,图7显示了目标检测的路线图,从2004年的Viola-Jones检测器到2019年的EfficientDet。值得一提的是,基于深度学习的检测方法被进一步分为两级检测器和单级检测器。

Figure 7: A road map of Object Detection (inspired from source).
大多数传统的目标检测算法,如 Viola-Jones,方向梯度直方图(HOG)和可变形零件模型(DPM) ,都依赖于从图像和经典的机器学习算法中提取出边缘、角点(corners)、梯度等手工特征。例如,Viola-Jones,第一个物体探测器,只是被设计用来探测人类的正脸,并不能很好地检测侧脸和上/下脸。
然后,在2012年,一个新时代到来了。在2012年ImageNet LSVRC-2012挑战赛中,深度卷积神经网络(CNN)的架构AlexNet,的准确度达84.7%,而第二名的准确度为73.8%。
然后,这些最先进的图像分类架构开始被用作目标检测pipeline中的特征提取器,这只是一个时间问题。这两个问题是相互关联的,它们依赖于学习robust 的 high-level features。因此,Girschick 等人(2014)展示了我们如何使用卷积特征进行目标检测,引入了 R-CNN (将 CNN 应用于region proposals)。从那时起,目标检测开始以前所未有的速度发展。
如图7所示,深度学习检测方法可以分为两个阶段; 第一个阶段称为两阶段检测算法,在多个阶段进行预测,包括像 RCNN、 fast-RCNN faster-RCNN 等网络。
第二类检测器称为单级检测器,如 SSD、 YOLO、 EfficientDet 等。
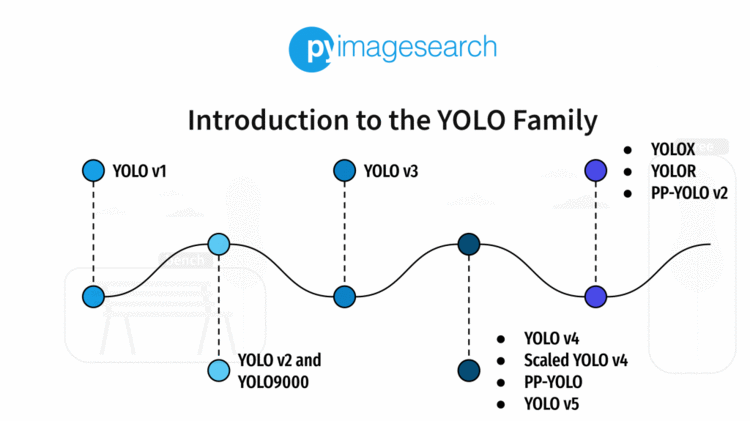
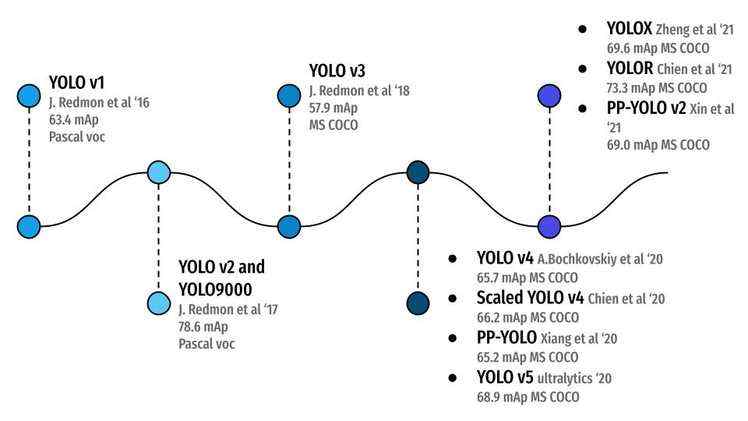
在图8中,你可以看到所有的 YOLO目标检测算法以及它们是如何演化的,从2016年的YOLOv1 实现了 Pascal/VOC (20个类)数据集上的63.4 mAP 到2021年的 YOLOR 在更具挑战性的 MS/COCO (80个类)数据集上的73.3 mAP 。这就是学术界的魅力所在。通过不断的努力工作和坚韧不拔的精神,YOLO 目标检测已经取得了长足的进步!
单级目标检测器是一类单级的目标检测结构。他们把目标检测作为一个简单的回归问题。例如,馈入网络的输入图像直接输出类概率和bounding box坐标。
这些模型跳过了region proposal 阶段,也称为Region Proposal Network,这通常是两阶段对象探测器的一部分,这是图像中可能包含目标的区域。
图9显示了单阶段和两阶段检测器工作流。在单阶段中,我们将检测头直接应用于特征图,而在两阶段中,我们首先将region-proposal network应用于特征图。
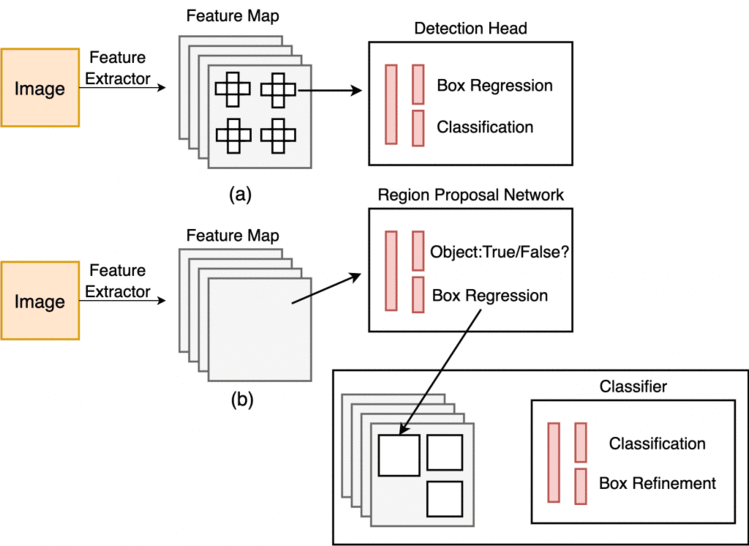
Figure 9: Single-Stage (top) and Two-Stage Detector (bottom) (image by the author).
然后,这些区域进一步传递到第二阶段,对每个区域进行预测。Faster-RCNN 和 Mask-RCNN 是最流行的两级目标检测器。
虽然两级目标器被认为比单级目标探测器更准确,但是它们的推断速度较慢,涉及多阶段。另一方面,单级探测器比两级探测器快得多。
在2016年的 CVPR 会议上,Joseph Redmon 等人发表了第一个单级目标探测器,You Only Look Once: Unified, Real-Time Object Detection。
YOLO (你只能看一次)是目检测标领域的一个突破,因为它是第一个将探测作为回归问题处理的单阶段目标检测器方法。该检测体系结构只查看一次图像,以预测目标的位置和它们的类标签。
与两阶段检测方法(Fast RCNN,Faster RCNN)不同,YOLOv1 没有proposal generator和完善(refine) 阶段; 它使用单一的神经网络预测类别概率和bounding box 坐标从整个图像一次通过。由于检测流水线本质上是一个网络,可以将其视为一个图像分类网络,因此可以进行端到端的优化。
由于这个网络被设计成端到端的训练方式,类似于图像分类,所以它的架构非常快,基本的 YOLO 模型预测图像的速度为45 FPS (帧率/秒) ,基准是 Titan x GPU。作者们还提出了一个更轻量级的 YOLO 版本,叫做 Fast YOLO,有较少的层以155 FPS 处理图像。是不是很神奇?
YOLO 实现了63.4 mAP (平均平均精度) ,如表1所示,是其他实时检测器的两倍多,使其更加特殊。我们可以看到 YOLO 和 Fast YOLO 在mean average precision(近2倍)和 FPS 方面都比 DPM 的实时目标检测器有相当大的优势。
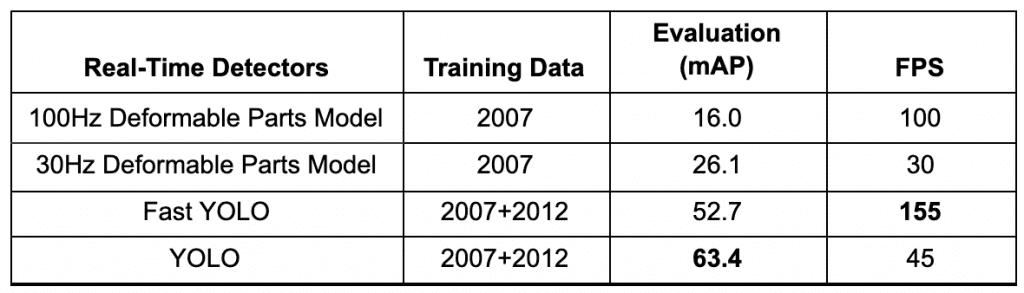
Table 1: Real-Time Detectors Quantitative Benchmarks (source: Redmon et al., p. 6).
通过对互联网上的艺术品和自然图像的研究,测试了YOLO的泛化性。此外,它大大超过了检测方法,如变形部件模型(DPM)和Region-Based 的卷积神经网络(RCNN)。
在我们即将到来的第2课中,我们将深入研究YOLOv1,所以一定要去看看!
Redmon 和 Farhadi (2017)在 CVPR 会议上发表了 YOLO9000: Better, Faster, Stronger的论文。作者在这篇论文中提出了两个最先进的 YOLO 变体: YOLOv2和 YOLO9000,它们除了在训练策略上不同,其他都是相同的。
YOLOv2是在Pascal VOC和MS COCO这样的检测数据集上训练的。同时,YOLO9000通过在MS COCO和ImageNet数据集上联合训练来预测9000多个不同的目标类别。
改进的 YOLOv2 模型使用了各种新颖的技术,在速度和准确性方面超过了诸如 Faster-RCNN 和 SSD 等最先进的方法。其中一种技术是多尺度训练,这种训练允许网络在不同的输入大小下进行预测,从而在速度和准确性之间进行权衡。
在416 × 416的输入分辨率下,YOLOv2 在2007 VOC 数据集上实现了76.8 mAP,在 Titan x GPU 上实现了67 FPS。在544 × 544输入的同一数据集上,YOLOv2 分别获得了78.6 mAP 和40 FPS。
图10显示了 YOLOv2 在 Titan x GPU 上的各种分辨率的基准测试,以及其他检测架构,如 Faster R-CNN、 YOLOv1、 SSD。我们可以观察到几乎所有的 YOLOv2 变体在速度和准确性方面都比其他的检测框架表现得更好,并且在 YOLOv2 中可以观察到accuracy (mAP)和 FPS 之间的一个尖锐的权衡。
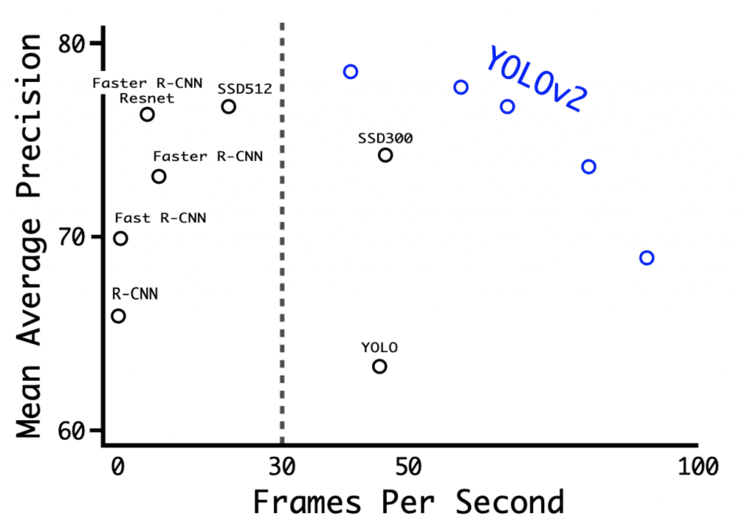
Figure 10: Accuracy and speed on Pascal VOC 2007 (source: Redmon and Farhadi, p. 7266).
关于 YOLOv2 的详细评论,请关注我们即将到来的第三课。
Redmon 和 Farhadi (2018)在arXiv上发表了 YOLOv3: An Incremental Improvement论文。作者对网络架构做了许多设计上的改变,并采用了来自 YOLOv1,特别是 YOLOv2 的大多数其他技术。
本文介绍了一种新的网络体系结构 Darknet-53。Darknet-53是一个比以前大得多的网络,更准确和更快。它在320 × 320,416 × 416等不同图像分辨率下进行训练。在320 × 320的分辨率下,YOLOv3 可以在 Titan x GPU 上以45 FPS 的速度运行,达到28.2 mAP,精度与单发探测器(SSD321)相当,但速度要快3倍(如图11所示)。
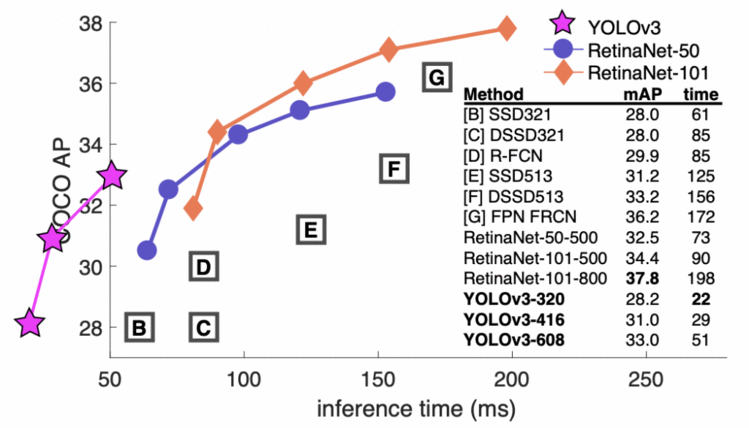
Figure 11: Quantitative Benchmark showing accuracy (COCO mAP) vs. inference time (ms) (source: Redmon and Farhadi, 2018, p. 1).
在即将到来的第五课中,我们将完全解析 YOLOv3。
YOLOv4是许多实验和研究的产物,这些实验和研究结合了各种小的新技术,提高了卷积神经网络的准确性和速度。
这篇论文在不同的 GPU 体系结构上做了大量的实验,结果表明 YOLOv4在速度和准确性方面优于所有其他的 目标检测网络体系结构。
2020年,Bochkovskiy et al. (著名 GitHub Repository: Darknet 的作者)在 arXiv 上发表了 YOLOv4: Optimal Speed and Accuracy of Object Detection 。我们可以从图12中观察到,YOLOv4运行速度比 EfficientDet 快两倍,性能相当,它将 yolov3的 mAP 和 FPS 分别提高了10% 和12% 。
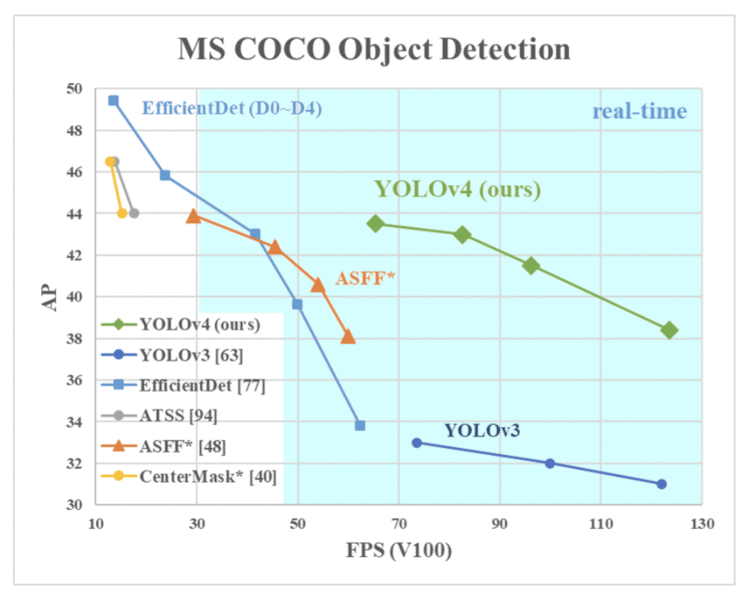
Figure 12: Comparison of the proposed YOLOv4 and other state-of-the-art object detectors (source: Bochkovskiy et al., p. 1).
卷积神经网络的性能在很大程度上取决于我们使用和组合的特征。例如,某些特征仅对特定的模型、特定的问题描述和特定的数据集起作用。但是batch normalization和residual connections等特性适用于大多数模型、任务和数据集。因此,这些特征可以被称为通用的。
Bochkovskiy et al. 充分利用了这一观点,并假设了一些通用的特征,包括
结合上述特性可以在 MS COCO 数据集上以43.5% mAP (65.7% mAP50)在 Tesla V100 GPU 上以实时速度∼65 FPS 实现最先进的结果。
Yolov4模型结合了上述和更多的特点,形成了“Bag of Freebies”,用于改进模型的训练,“Bag-of-Specials”用于提高目标检测器的准确性。
在即将到来的第6课中,我们将用代码全面介绍 YOLOv4。
2020年,在 YOLOv4发布后的两个月内,Ultralytics 的创始人兼首席执行官 Glenn Jocher 在 GitHub 上发布了 YOLOv5的开源实现。YOLOv5提供了一个基于 MS COCO 数据集的目标检测架构家族。随后,公司发布了 EfficientDet 和 YOLOv4。这是唯一一个没有研究论文的 YOLO 目标检测器,这篇论文最初引起了一些争议; 然而,很快,这个概念就被打破了,因为它的能力削弱了噪音。
今天,YOLOv5是官方最先进的模型之一,拥有巨大的支持,并且更容易在生产中使用。最好的部分是,YOLOv5 是在 PyTorch 中实现的,消除了 Darknet 框架的限制(基于 c 编程语言,而不是从生产环境的角度构建的)。Darknet 框架随着时间的推移不断发展,它是一个很好的研究框架,可以使用 TensorRT 进行工作、训练、微调和推断; 所有这些在 Darknet 中都是可能的。然而,它有一个较小的社区,因此,较少的支持。
PyTorch中YOLO的巨大变化使开发人员更容易修改架构并直接导出到许多部署环境中。别忘了,YOLOv5是Torch Hub showcase 上举办的官方最先进的模型之一。
正如您在下面的 shell 代码块中看到的,您可以使用 YOLOv5和 PyTorch Hub 在五行代码中运行一个推理。是不是很神奇?
$ import torch
$ model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5m, yolov5l
$ img = 'https://ultralytics.com/images/zidane.jpg' # or file, Path, PIL, OpenCV
$ results = model(img)
$ results.print() # or .show(), .save()
在发布的时候,YOLOv5是所有已知的YOLO实现中最先进的。自YOLOv5发布以来,这个存储库一直非常活跃,自YOLOv5-v1.0发布以来,已有超过90个贡献者。
从开发的角度来看,YOLOv5存储库提供了大量的功能,使得训练、调优、测试和部署在各种目标平台上变得非常容易。他们提供的一些现成的教程包括:
此外,他们还开发了一款名为 iDetection的iOS应用程序,提供了YOLOv5的四种变体。我们在iPhone 13 Pro上测试了这款应用程序,结果令人印象深刻;该模型的检测速度接近30FPS。
与YOLOv4一样,YOLO v5在Backbone 使用Darknet-53的Cross-Stage Partial Connections和Neck上使用 Path Aggregation Network。主要的改进包括新颖的马赛克数据增强(来自YOLOv3 PyTorch实现)和auto-learning bounding box anchors。
mosaic data augmentation的思想最初是由Glenn Jocher在YOLOv3 PyTorch实现中使用的,现在在YOLOv5中使用。mosaic augmentation是将四幅训练图像按照一定的比例拼接成一幅图像,如图13所示。mosaic augmentation对于流行的COCO对象检测benchmark特别有用,它帮助模型学会解决众所周知的“小目标问题”——在这个问题中,小目标的检测不如大目标准确。
使用mosaic data augmentation的好处是:

Figure 13: Mosaic represents a new method of data augmentation (source: Bochkovskiy et al., 2020).
在表2中,我们展示了在Volta 100 GPU上640×640图像分辨率的MS COCO验证数据集上5个YOLOv5变体的性能(mAP)和速度(FPS)benchmarks。所有5个模型都在MS COC训练数据集上进行训练。模型基准以从YOLOv5n(即,具有最小模型的nano 变种到最大的模型YOLOv5x)开始的升序显示。
考虑YOLOv5l;当batch size = 1和67.2 mAP为0.5 IOU时,推理速度为10.1ms(或100 FPS)。相比之下,在V100上具有608分辨率的YOLOv4实现了62 FPS with 65.7 mAP at 0.5 IOU. YOLOv5显然是这里的赢家,因为它提供了最好的性能和比YOLOv4更快的速度。
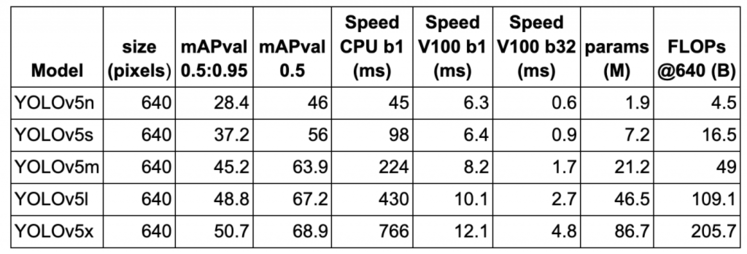
Table 2: Performance and Speed benchmarks of five YOLOv5 variants on the MS COCO dataset.
2021年10月,YOLOv5-v6.0发布,包含了许多新特性和bug修复(来自73个贡献者的465个PRs),带来了架构调整,最重要的是引入了新的P5和P6 Nano模型:YOLOv5n和YOLOv5n6。Nano型号的参数比以前的型号少了75%,从7.5M到1.9M,小到足以在移动设备和CPU上运行(如图14所示)。从下图可以看出,YOLOv5的性能明显优于EfficientDet变种。此外,即使最小的YOLOv5变种(即YOLOv5n6)也比EfficientDet 得到相当accuracy下推理更快。
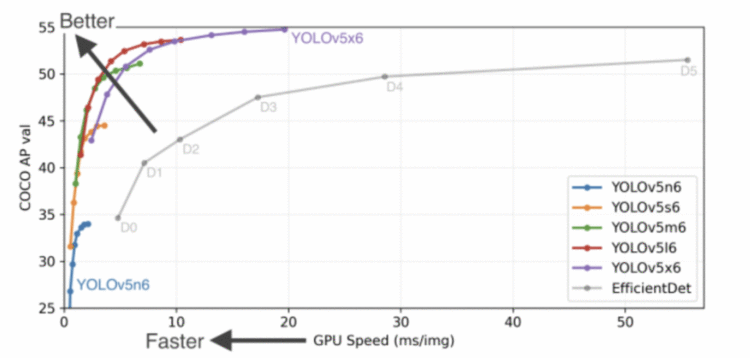
Figure 14: Performance and speed benchmarks for the YOLOv5-v6.0 family of models on MS COCO dataset, Official benchmarks include YOLOv5n6 at 1666 FPS (640×640 image resolution with a batch size of 32 on a Tesla v100 GPU).
因为YOLOv5n是YOLOv5最小的变种,所以我们将它与YOLOv4- tiny进行比较,YOLOv4-Tiny也是YOLOv4型号中最轻的变种。图15显示,YOLOv5 nano变种在训练时间和准确性方面无疑优于YOLOv4-Tiny。
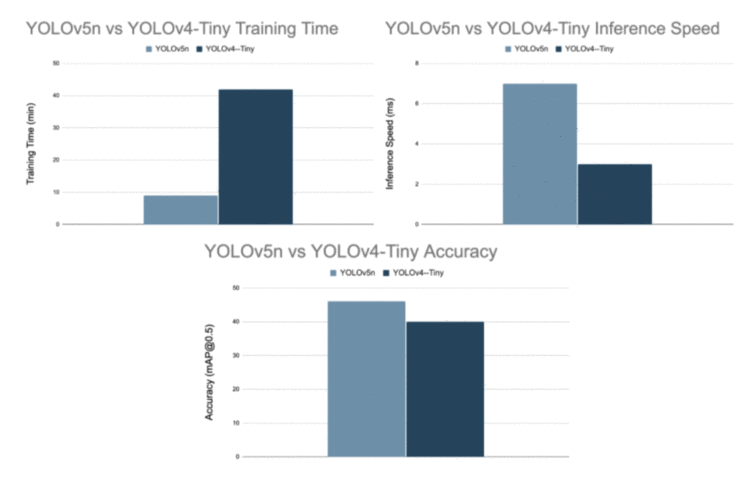
Figure 15: Benchmarks of YOLOv5n and YOLOv4-Tiny (source).
PP-YOLO是PaddleDetection的一部分,这是一个基于PaddlePaddle框架的端到端目标检测开发工具包(如图16所示)。它提供了大量的目标检测架构i、backbones、数据增强技术、组件(如losses、feature pyramid network等),可以以不同的配置组合,以设计出最佳的目标检测网络。
简而言之,它提供了目标检测、实例分割、多目标跟踪、关键点检测等图像处理功能,使这些模型在构建、训练、优化、部署等过程中更快更好地进行目标检测。
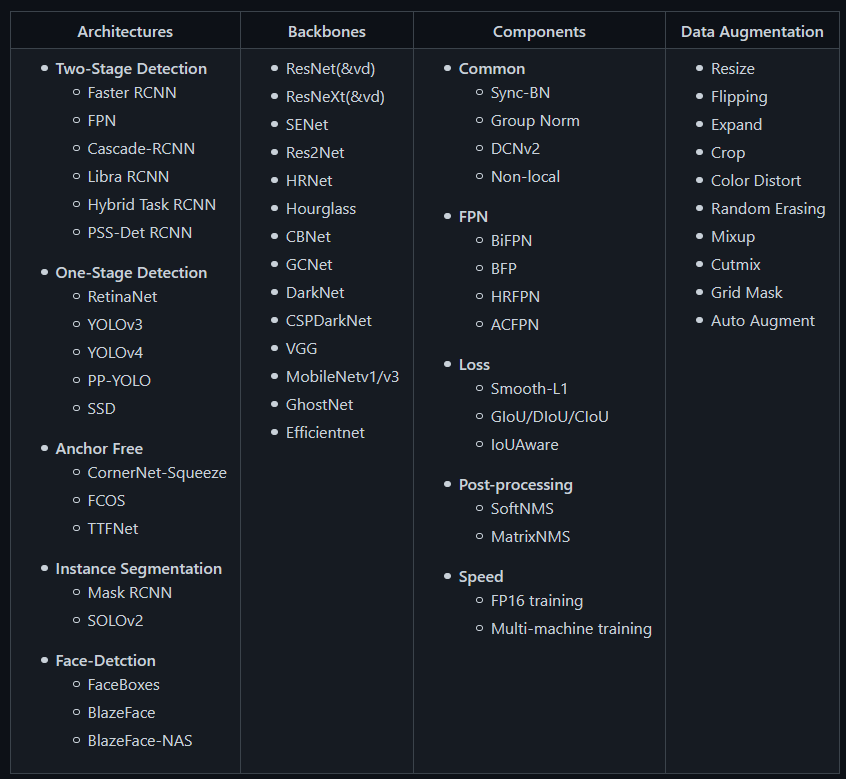
Figure 16: Overview of the Development Kit Structure (source).
现在让我们回到 PP-YOLO 论文。
这篇文章的目的不是发布一个新颖的目标检测模型,而是一个具有相对平衡的有效性和效率的目标检测器,可以直接应用于实际的应用场景。这个目标与 PaddleDetection 开发套件的动机相呼应。因此,新颖之处在于证明这些技巧和技术更好地平衡了有效性和效率,并提供了一个关于每一技巧对检测器有多大帮助的消融研究。
与 YOLOv4类似,本文还尝试结合现有的各种技巧,不增加模型参数和 FLOPs 的数量,但尽可能提高检测器的准确性,并保证检测器的速度几乎不变。然而,与 YOLOv4不同的是,本文并没有探讨不同的backbone(Darknet-53,ressnext50)和数据增强方法,也没有使用神经结构搜索(NAS)来搜索模型超参数。
通过结合所有的技巧和技术, 当测试Volta 100 GPU batch size = 1,PP-YOLO达到45.2%的mAP和推理速度为72.9 FPS(如图17所示),标志着一个更好的有效性和效率之间的平衡,超过了著名的最先进的探测器如EfficientDet,YOLOv4, RetinaNet。
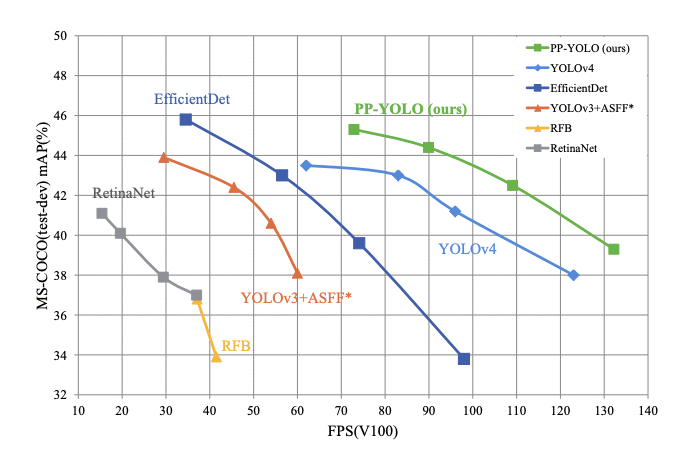
Figure 17: Comparison of the proposed PP-YOLO with other state-of-the-art object detectors. PP-YOLO runs faster (x-axis) than YOLOv4 and improves mAP (y-axis) from 43.5% to 45.2%.
单级检测模型一般由backbone, detection neck, and detection head组成。PP-YOLO 的架构(如图18所示)与 YOLOv3和 YOLOv4检测模型非常相似。
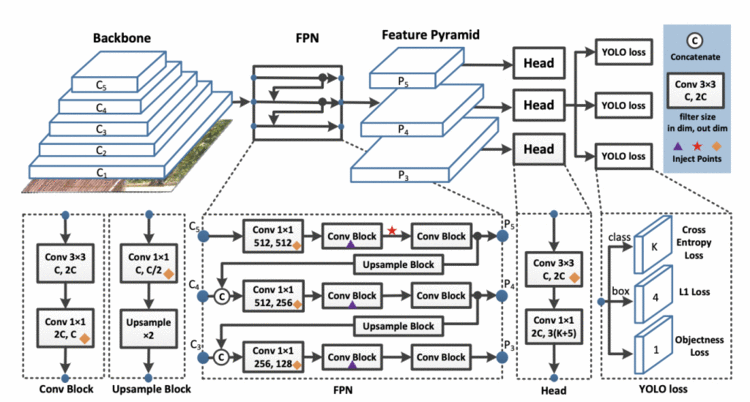
Figure 18: PP-YOLO Architecture Diagram consisting of Backbone, Neck, and Head (source).
PP-YOLO 检测器分为三部分:
在所提出的backbone模型中,在架构的最后阶段,3 × 3卷积层被可变形卷积层代替。与 Darknet-53 相比,ResNet50-vd 的参数量和 FLOPs 数量明显减少。这有助于实现比 YOLOv3稍高的 mAP (39.1)。
最终输出的输出通道是 3(K+5),其中K是类的数量(MS COCO 数据集为80) ,3是每个网格上anchors的数量。对于每个anchor,第一个 K 通道是预测类概率,四个通道是bounding box坐标预测,一个通道是目标得分预测。
在上面的 PP-YOLO 结构中,钻石表示coord-conv layers,紫色三角形表示DropBlocks,红色星号表示Spatial Pyramid Pooling。
如果你还记得,我们讨论过这篇文章结合了各种技巧和技术来设计一个有效和高效的目标检测网络; 现在,我们将简要介绍每一个。这些技巧都已经存在,来自不同的论文。
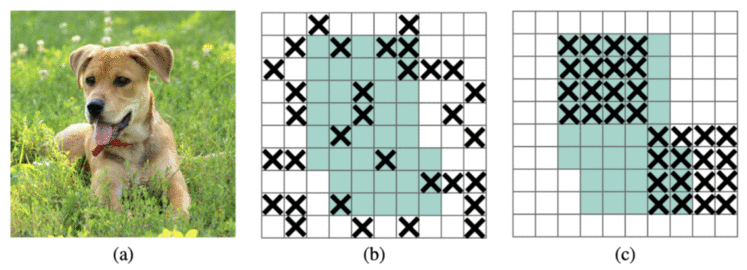
Figure 19: (a) input image to a convolutional neural network. The green regions in (b) and (c) include the activation units which contain semantic information in the input image (source).
在 PP-YOLO 中,DropBlock 只应用于检测head(即 FPN) ,因为将其添加到backbone会降低模型的性能。
在介绍 PP-YOLO 之前,我们了解到 PP-YOLO 比 YOLOv4运行得更快,mean average precision score从43.5% 提高到45.2% 。PP-YOLO 的详细性能见表3。
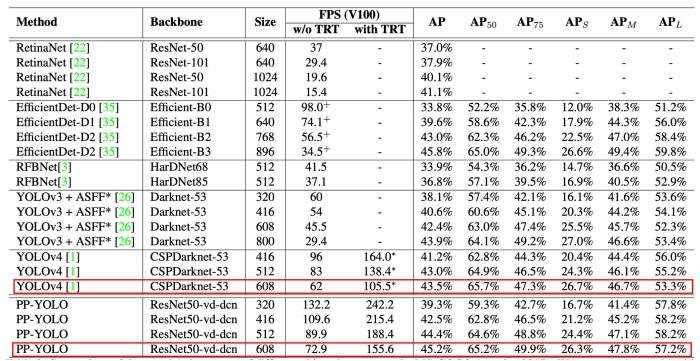
Table 3: Detailed comparison of the speed and accuracy of PP-YOLO with other state-of-the-art object detectors on the MS-COCO (test-dev 2017). The results with batch size = 1, with and without TensorRT are computed.
Long et al. (2020) 比较了Volta 100 GPU 上有 TensorRT 和没有 TensorRT (加速推理)的模型。从表中我们可以得出结论,与 YOLOv4相比,MS COCO 数据集上的 mAP 分值从43.5% 增加到45.2% ,FPS 从62 增加到72.9(没有 TensorRT)。
该表还显示了带有其他图像分辨率的 PP-YOLO,与其他最先进的检测器相比,PP-YOLO 在速度和精度的平衡方面似乎确实具有优势。
作者进行的消融研究表明,技巧和技术如何影响模型的参数和性能。在表4中,PP-YOLO 从表示为 B 的第二行开始,其中检测器使用 resnet50作为可变形卷积的backbone。当您移动到下一行 C 时,技巧会添加到前一个模型体系结构中,并且贯穿始终。性能增益和参数和 FLOPS 的增加都显示在相应的列中。
我们强烈建议您查看the paper以了解更多细节。
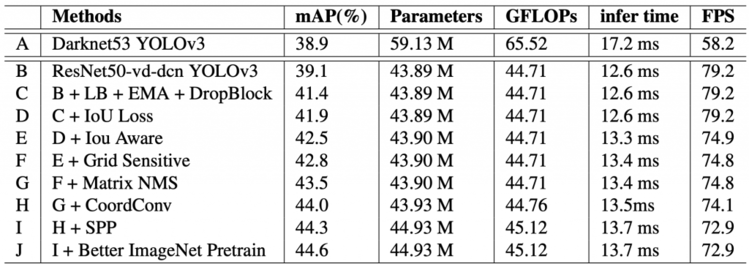
Table 4: Ablation study of techniques and tricks on the MS-COCO minival split.
Wang et al. (2021) 在 CVPR 会议上发表了一篇题为“ Scaled-YOLOv4: Scaling Cross Stage Partial Network”的论文。到目前为止,这篇论文已经受到了190多条引用!通过 Scaled-YOLOv4,作者通过有效地缩放网络的设计和规模,推动了 YOLOv4模型的发展,超过了谷歌研究大脑团队今年早些时候发布的EfficientDet 。
可以在这里找到 PyTorch 框架中 scaled-yolov4的实现。
提出的基于Cross-Stage Partial 方法的检测网络,在速度和准确性方面都超过了之前大的和小的目标检测模型的基准。此外,网络缩放方法修改网络的深度、宽度、分辨率和架构。
图20显示了 Scaled-YOLOv4-large 模型实现的最先进的结果: MS COCO 数据集上55.5% AP (73.4% AP50),在 Tesla V100 GPU 上以 16 FPS 的速度。
另一方面,更轻的 Scaled-YOLOv4-tiny 版本在 RTX 2080Ti GPU 上使用 TensorRT (半精度 FP-16)优化(batch size = 4) ,以443fps 的速度达到22.0% AP (42.0% AP50)。
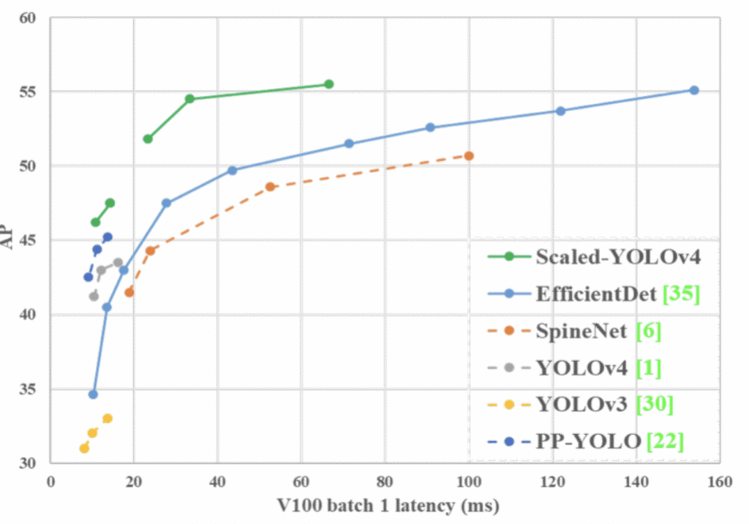
Figure 20: Comparison of the proposed Scaled-YOLOv4 with other state-of-the-art object detectors (source).
图20显示 scaled-yolov4与其他最先进的检测器相比获得了最好的结果。
卷积神经网络结构可以在三个维度上进行缩放: 深度、宽度和分辨率。网络的深度对应于网络中的层数。宽度与卷积层中滤波器或通道数量有关。最后,分辨率就是输入图像的高度和宽度。
图21给出了对这三个维度的模型缩放的更直观的理解,其中(a)是一个baseline网络示例; (b)-(d)是只增加网络宽度、深度或分辨率一维的常规缩放; (e)是一种提出的(在 EfficientDet 中)复合缩放方法,以固定比例均匀地缩放所有三个维度。
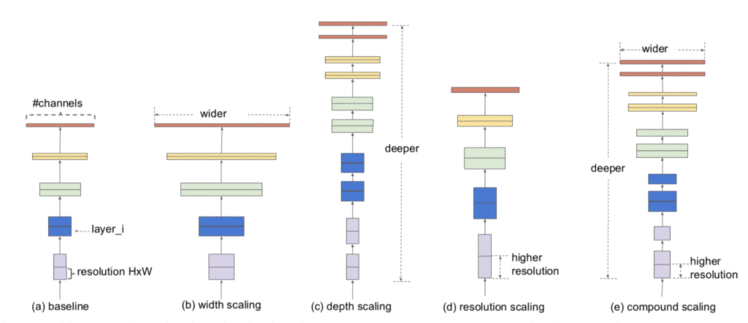
Figure 21: Model Scaling in EfficientDet (source).
传统的模型缩放方法是改变模型的深度,即增加更多的卷积层。例如,由 Simonyan 等人设计的 VGGNet 在不同的阶段堆叠了额外的卷积层,并使用这个概念来设计 vgg-16和 vgg-19架构。
下列方法通常遵循相同的模型缩放方法。首先,由 He et al. (2015) 提出的 ResNet 体系结构使用深度缩放来构建非常深的网络,如 ResNet-50,ResNet-101,它允许网络学习更复杂的特征,但遭受了消失的梯度问题。后来, Zagoruyko and Komodakis (2017) 考虑了网络的宽度,改变了卷积核的个数,实现了缩放,从而在保持相同精度的情况下实现了wide ResNet(WRN)。虽然 WRN 的参数比 ResNet 多,但推理速度要快得多。
然后近年来,复合缩放使用复合系数均匀地缩放了卷积神经网络架构的所有深度/宽度/分辨率的尺寸。与传统的任意缩放这些因素的方法不同,复合缩放方法使用一组固定的缩放系数均匀地缩放网络的宽度、深度和分辨率。
这也是 scaled-YOLOv4 试图做的,也就是说,使用优化的网络缩放技术来实现 YOLOv4-CSP-> P5-> P6-> p7 检测网络。
YOLOv4 是为通用 GPU 上的实时目标检测设计的。在 Scaled-YOLOv4中,YOLOv4 被重新设计为 YOLOv4-csp,以获得最佳的速度/精度折衷。
Wang et al. (2021) 在论文中提到,他们“CSP-ized”了目标检测网络的一个特定部分。这里的 CSP-ize 指的是应用 Cross Stage Partial Networks 论文中提出的概念。CSP 是构建卷积神经网络的一种新方法,它减少了各种 CNN 网络的计算量: 最多可达50% (在FLOPs 方面对于 Darknet backbone)。
在 CSP 连接中:
图22显示了 CSP 连接的示例。左边是标准网络,右边是 CSP 网络。
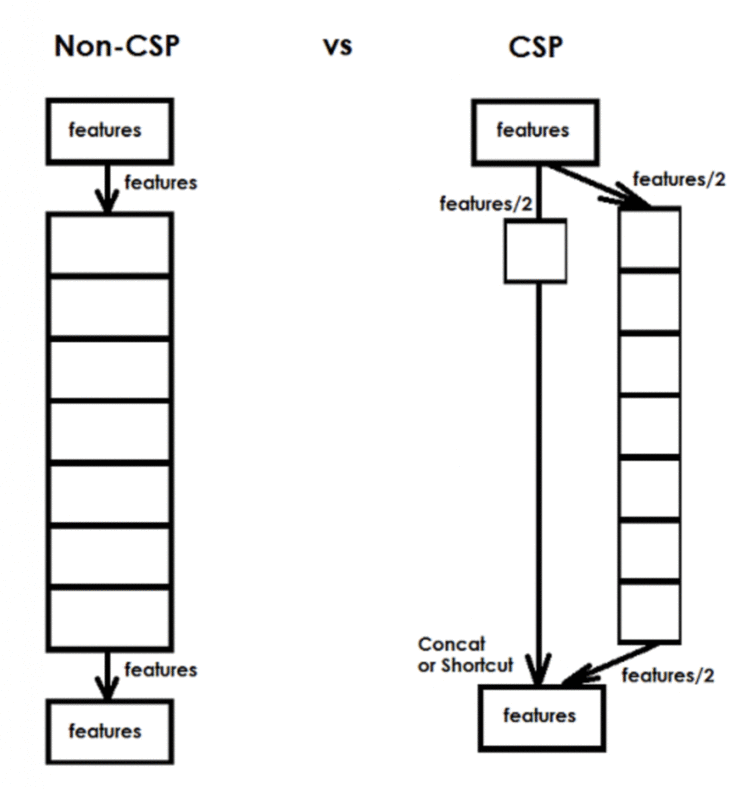
Figure 22: Example of a CSP connection (source).
YOLOv4-tiny 模型与 Scaled-YOLOv4模型有不同的考虑,因为在边缘侧,各种约束会发挥作用,比如内存带宽和内存访问。对于 YOLOv4-tiny 的浅层 CNN,作者指望 OSANet 在很小的深度上具有良好的计算复杂性。
表5显示了 YOLOv4-tiny 与其他tiny目标检测器的性能比较。同样,YOLOv4-tiny 实现了与其他tiny模型相比的最佳性能。
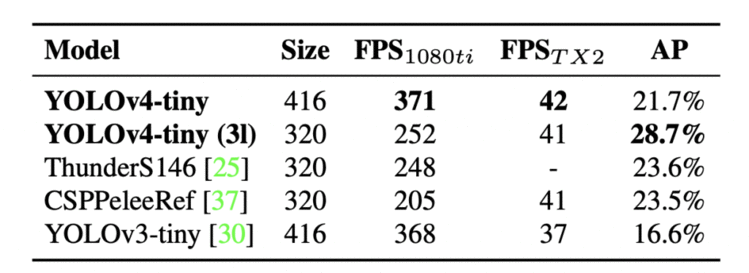
Table 5: Comparison of state-of-the-art tiny models.
表6显示了 YOLOv4-tiny 的结果时,测试不同的嵌入式 gpu,包括 Xavier AGX,Xavier NX,Jetson TX2,Jetson NANO。如果采用 fp16和batch size = 4 对 Xavier AGX 和 Xavier NX 进行测试,帧率分别可达到290fps 和118fps。
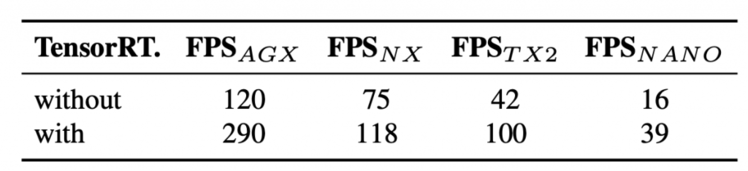
另外,当batch size分别为1和4时,用TensorRT FP16 在通用 GPU RTX 2080ti 上运行 YOLOv4-tiny,分别可以达到773fps 和1774fps,速度极快。
YOLOv4-tiny 无论使用何种设备都能实现实时性能。
为了检测大图像中的大型物体,作者发现增加 CNN backbone和neck的深度和 stages 数是必要的(据报道增加宽度几乎没有效果)。这允许他们首先放大input size和stages 数,并根据实时推理速度要求动态调整宽度和深度。除了这些比例因子之外,作者还在论文中改变了他们的模型架构的配置。
YOLOv4-large 是为云计算 GPU 设计的,主要目的是实现目标检测的高精度。此外,还开发了一个完全CSP-ized 的模型 YOLOv4-P5,并将其放大到 YOLOv4-P6 和 YOLOv4-P7,如图23所示。
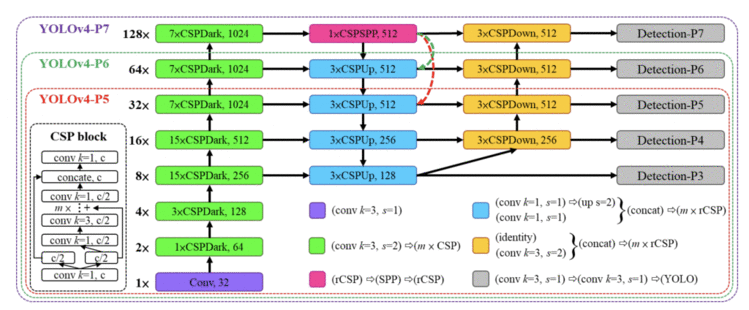
Figure 23: Architecture of YOLOv4-large, including YOLOv4-P5, YOLOv4-P6, and YOLOv4-P7.
当宽度比例因子等于1时,YOLOv4-P6 可以达到30 FPS 的视频实时性能。当宽度比例因子等于1.25时,YOLOv4-P7可以实现16 FPS 的视频实时性能。
YOLOv4 中的数据增强是 YOLOv4 令人印象深刻的性能的关键贡献之一。在 Scaled-YOLOv4中,作者首先在一个较少增强的数据集上进行训练,然后在训练结束时打开增强以进行微调。他们还使用“测试时间增强”,其中有几个增强应用于测试集。预测是在这些测试增强中取平均值,以进一步提高其非实时结果。
最后,作者展示了基于 CSP 方法的 YOLOv4 目标检测神经网络可以上下扩展,适用于大小网络; 因此,他们称之为 Scaled-YOLOv4。此外,所提出的模型(YOLOv4-large)在MS COCO 数据集的test-dev 上获得了56.0% 的最高 AP 准确率,使用 TensorRT-FP16 实现了 YOLOv4-tiny RTX 2080Ti 的极高的1774 FPS 速度,以及其他 YOLOv4模型的最优速度和准确度。
到目前为止,我们已经覆盖了7个 YOLO 目标探测器,我们可以说2020年是到目前为止最好的一年,对 YOLO 家族来说更是如此。我们了解到,YOLOv4、 YOLOv5、 PP-YOLO 和 Scaled-YOLOv4在目标检测一个接一个地达到了最先进的水平。
现在让我们进入下一个 YOLO 检测器,看看2021年会发生什么!
2021年,百度发布了 PP-YOLO 的第二个版本,称为 PP-YOLOv2: A Practical Object Detector,由 Xing Huang 等人发布在 arXiv 上,在目标检测域中达到了新的高度。
从这篇论文的标题可以很容易地推断出,这篇论文背后的动机是开发一个目标检测器,它可以达到很好的准确性,并且以更快的速度执行推理。因此,是一个实用的物体检测器。此外,由于本文是前期工作(即 PP-YOLO)的后续,作者希望开发一种能够在有效性和有效性之间达到完美平衡的检测器,为了实现这一目标,类似的集成技巧和技术被跟踪,并且重点放在消融研究上。
通过结合多种有效改进,PP-YOLOv2 显著提高了性能(即在 MS coco2017测试集上从45.9% mAP 提高到49.5% mAP)。此外,在速度方面,PP-YOLOv2 以68.9 FPS 运行,分辨率为640 × 640,如图24所示。此外,PP-YOLOv2 采用了两种不同的 backbone 架构: resnet-50和 ResNet-101,而 PPYOLOv1 只使用 resnet-50 backbone架构发布。
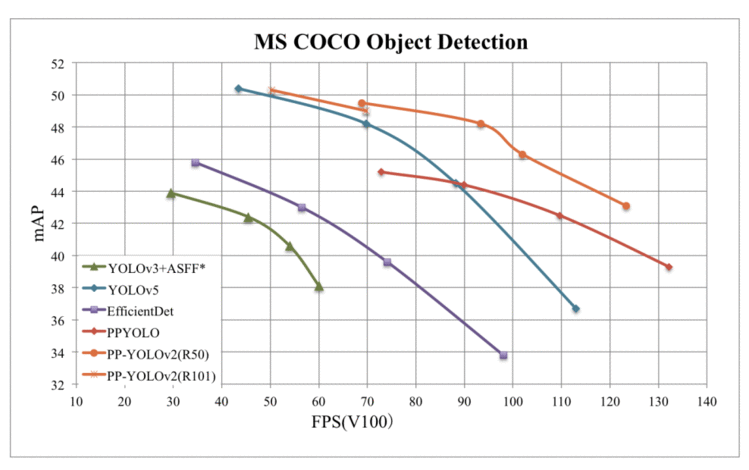
Figure 24: Comparison of the proposed PP-YOLOv2 and other object detectors.
在 TensorRT 引擎的支持下,半精度(FP16,batch size = 1)进一步提高了 PP-YOLOv2-ResNet50 推理速度到106.5 FPS,超过了其他最先进的对象检测器,如 YOLOv4-CSP 和 YOLOv5l,其模型参数大致相同。
当检测器的backbone 从 resnet50更换为 resnet101时,PP-YOLOv2 在 MS co2017测试集上获得了50.3% 的 mAP,与 YOLOv5x 在速度上显著地超过了 YOLOv5x 近16% ,达到了类似的性能。
所以现在你知道了,如果你的老板让你处理一个涉及到目标检测的问题,你需要选择哪个探测器。当然,如果 KPI 要以更快的速度实现良好的性能,那么答案应该是 PP-YOLOv2:) !
到目前为止,我们知道 PP-YOLOv2 是在 PP-YOLO 论文的研究进展的基础上建立起来的,该论文充当了 PP-YOLOv2 的 baseline 模型。
PP-YOLO 是 YOLOv3 的一个增强版本,YOLOv3的backbone darknet-53 被 ResNet50-vd 所取代。许多其他的改进是通过严格的消融研究利用共10个技巧,如
表7显示了使用Volta 100 GPU,在MS COCO mini validation split 上改进的消融研究。在表中,A 指的是基准 PP-YOLO 模型。然后,在B中,PAN 和 Mish 被添加到 A中,有了 2 mAP 的显著提高; 虽然 B 比 A 慢,但是精度提升是值得的。
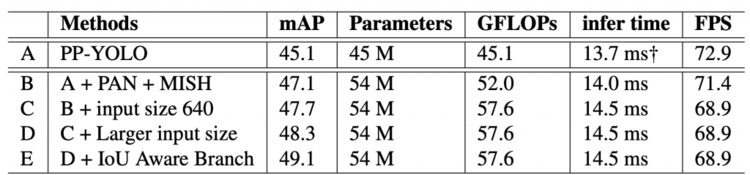
Table 7: Ablation Study in PP-YOLOv2 on MS COCO Dataset. “†” indicates the result includes bounding box decode time (1~2 ms).
Yolov4和 YOLOv5 在640图像分辨率上进行了评估, PP-YOLOv2 的输入大小增加到640,用于训练和评估以进行公平的比较(如 C 所示)。
D (larger input size)和 E (IoU Aware 分支)中的 提升了 mAP ,都没有增加推理时间,这是一个好迹象。
要了解更多关于 PP-YOLOv2 与其他最先进的目标检测器的速度和准确性比较的详细信息,请查看 paper on arXiv 中的表2。
2021年,Ge等人在arXiv上发表了一份名为YOLOX: Exceeding YOLO Series in 2021的技术报告。到目前为止,我们了解到的唯一一个 anchor-free 的YOLO目标检测器是YOLOv1,但是YOLOX也以 anchor-free 的方式检测目标。此外,它还采用了其他先进的检测技术,如decoupled head、利用鲁棒数据增强技术和领先的标签分配策略SimOTA,以实现最先进的结果。
YOLOX 使用单一的 YOLOX-L 模型赢得了Streaming Perception Challenge的第一名。
如图25(右)所示,只有0.91m 参数的 YOLOX-Nano 在 MS COCO 数据集上获得了25.3% 的 AP,超过 NanoDet 1.8% 的 AP。对 YOLOv3 进行各种修改,使 COCO 上的 AP 准确率从44.3% 提高到47.3% 。
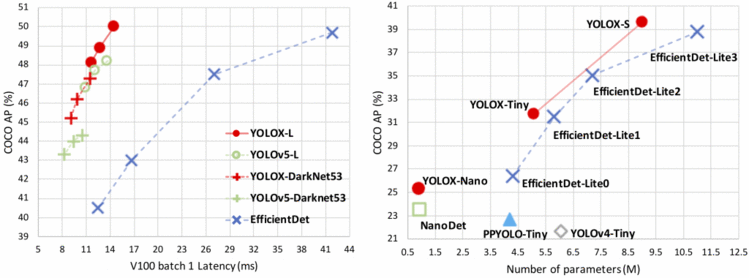
Figure 25: Speed-accuracy trade-off (left) and Size-accuracy curve of lite models (right) for YOLOX and other state-of-the-art object detectors.
YOLOX-L 在 Tesla v100上以68.9 FPS 的速度在 COCO 上获得50.0% AP,其参数与 YOLOv4-CSP,YOLOv5-L 大致相同,超过 YOLOv5-L 1.8% AP。
YOLOX 是在 PyTorch 框架中实现的,在设计时考虑到了开发人员和研究人员的实际使用。因此,YOLOX 部署版本也可以在 ONNX、 TensorRT 和 OpenVino 框架中使用。
在过去的两年里,目标检测学术界在 anchor-free 检测器、高级标签分配策略和端到端(NMS-free)检测器方面取得了重大进展。然而,这些技术还没有应用到 YOLO目标检测架构中,包括最近的模型: YOLOv4、 YOLOv5和 PP-YOLO。它们中的大多数仍然是 anchor-based 的检测器,并且手工制定了用于训练的分配规则。这就是发布 YOLOX 的动机!
选用带有Darknet-53 backbone 的YOLOv3作为baseline。然后,对 base 模型进行了一系列的改进。
从baseline到最终的YOLOX模型,训练设置基本上相似。所有模型在MS COCO train2017数据集上进行300个epoch的训练,batch size 为128。 input size 均匀地从448 到832,有32个strides。在一台Tesla Volta 100 GPU上,使用FP16精度(半精度)和 size = 1 来测量FPS和延迟。
它使用DarkNet-53 backbone 和一个被称为YOLOv3-SPP 的SPP层。一些训练策略相对于原来的实现进行了修改,如
通过这些增强,YOLOv3 baseline 在MS COCO验证集上实现了38.5%的AP,如表8所示。所有型号均在Tesla V100上以640×640分辨率、FP16-precision和batch size = 1进行测试。下表中的延迟和FPS是在没有post-processing的情况下测量的。
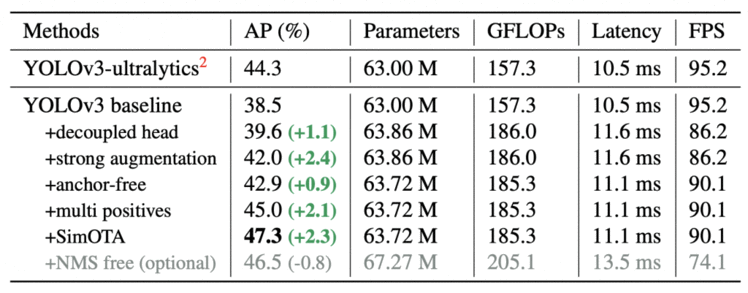
Table 8: YOLOX-Darknet53 in terms of AP (%) on MS COCO val.
图26显示了 YOLOv3 到 YOLOv5 模型中使用的coupled head(上部)和 YOLOX 的decoupled head(下部)。这里的head是指不同尺度下的输出预测。例如,在coupled head中,我们有一个预测张量 H*W*(Cls+Reg+Obj) (详细的解释见下图)。而这种方法的问题在于,在训练过程中,我们通常将分类和定位任务放在同一个head里,在训练过程中这两个head之间经常会相互竞争。因此,模型很难对图像中的每个目标进行正确的分类和定位。
因此,YOLOX 使用了用于分类和定位的decoupled head,如图26所示(下)。对于 FPN 特征的每个层次,首先采用一个1 × 1的连续层,将特征通道减少到256个。然后带有两个 3×3 conv的两个并行分支被加入,分别完成分类和定位任务。最后,向定位分支添加一个额外的 IoU 分支。
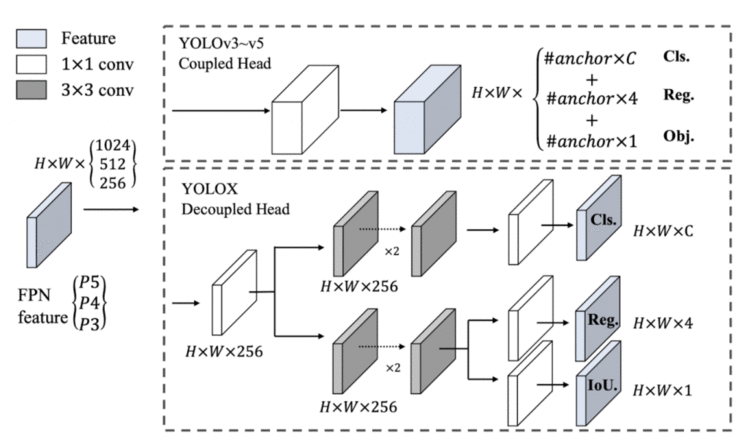
Figure 26: Illustration of the difference between YOLOv3 head and the proposed decoupled head.
decoupled head使得YOLOX模型比coupled head收敛更快,如图27所示。此外,在x轴上,我们可以观察到decoupled head的COCO AP分数如何比YOLOv3 head提高得更快。
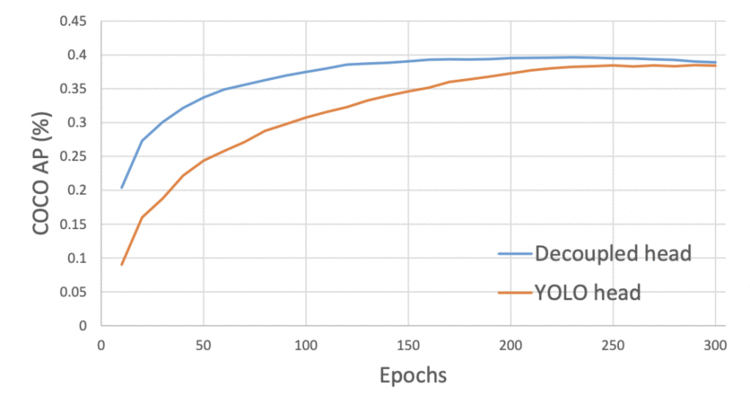
Figure 27: Training curves for detectors with YOLOv3 coupled and YOLOX decoupled head.
加入了类似YOLOv4的Mosaic和MixUp数据增强技术,以提高YOLOX的性能。Mosaic是ultralytics-YOLOv3 提出的一种有效的增强策略。
使用上述两种增强技术,作者发现在ImageNet数据集上对backbone 进行预训练并没有什么好处,所以他们从头开始训练模型。
为了开发一种高速目标检测器,YOLOX 采用了一种 anchor-free 机制,减少了设计参数的数量,因为现在我们不再需要处理anchor boxes,这大大增加了预测的数量。因此,对于预测head中的每个位置或网格,我们现在只有一个预测,而不是预测三个不同anchor boxes的输出。每个目标的中心位置被认为是一个正样本,并有一个预定义的比例范围。
简单地说,在 anchor-free 检测中,每个网格的预测值从3减少到1,它直接预测四个值,它们是 相对网格的左上角的两个偏移量 和 预测框的高度和宽度。
使用这种方法,减少了网络参数和检测器的 GFLOPs,使检测器更快,甚至性能提高到42.9% AP,如表8所示。
为了与YOLOv3的分配规则一致,anchor-free 版本只为每个目标选择一个正样本(中心位置),而忽略其他高质量的预测。然而,优化这些高质量的预测也可能带来有益的梯度,这可能会缓解训练中正/负采样的极端不平衡。在YOLOX中,中心3×3区域被分配为正样本,在FCOS paper中也被称为“中心采样”。因此,检测器的性能提高到45.0% AP,如表8所示。
为了进行公平的比较,YOLOX用YOLOv5改良的带有SiLU激活函数的 CSP v5 backbone 取代了Darknet-53 backbone 并且使用 PAN head。通过利用其缩放规则,YOLOX-S、YOLOX-M、YOLOX-L和YOLOX-X模型被生产出来。
表9为YOLOv5模型与YOLOX产生的模型对比。所有YOLOX变种的AP均有~ 3.0% ~ 1.0%的持续改善,使用 decoupled head 只增加了少量的时间。下面的模型在一个 Tesla Volta 100 GPU上, FP16-precision(半精度)和batch size = 1,在640×640图像分辨率下测试。
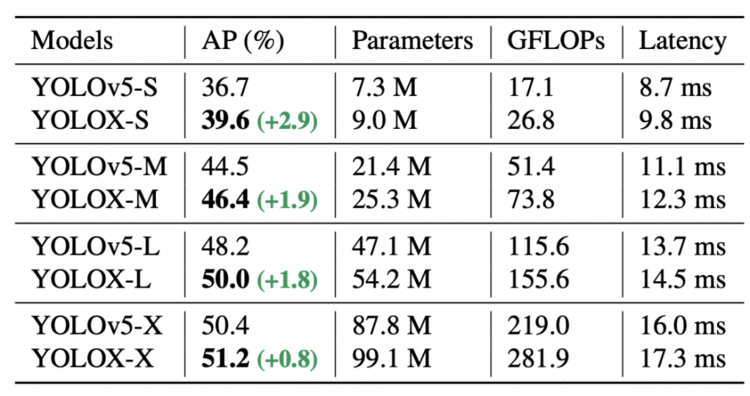
Table 9: Comparison of produced YOLOX variants with existing YOLOv5 variants in terms of AP (%) on MS COCO dataset along with Parameters, GFLOPs, and Latency factors.
我们将 YOLOX 模型与 YOLOv5模型进行了比较,后者在尺寸上分为小型、中型、大型和特大型(更多的参数)。作者进一步缩小了 YOLOX 模型,使其参数低于 YOLOX-s 变体,从而生产 YOLOX-tiny 和 YOLOX-nano。YOLOX-Nano 是专门为移动设备设计的。该模型采用深度卷积方法,模型参数为0.91M,1.08G FLOPs。
如表10所示,YOLOX-Tiny 与 YOLOv4-Tiny 和 PPYOLO-Tiny 相比较。同样的,YOLOX 在更小的模型size上表现良好。
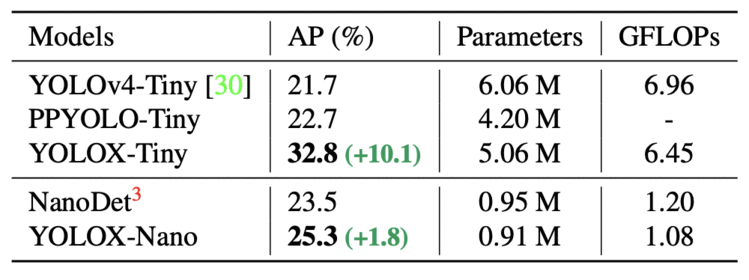
Table 10: Comparison of YOLOX-Tiny and YOLOX-Nano and the counterparts in terms of AP (%) on MS COCO validate dataset.
恭喜你能走到这一步。如果你能够轻松地跟进,甚至稍微努力一点,做得好!所以让我们快速总结一下:
Sharma, A. “Introduction to the YOLO Family,” PyImageSearch, D. Chakraborty, P. Chugh, A. R. Gosthipaty, J. Haase, S. Huot, K. Kidriavsteva, R. Raha, and A. Thanki, eds., 2022, https://pyimg.co/3cpmz
@incollection{Sharma_2022_YOLO_Intro,author = {Aditya Sharma},title = {Introduction to the {YOLO} Family},booktitle = {PyImageSearch},editor = {Devjyoti Chakraborty and Puneet Chugh and Aritra Roy Gosthipaty and Jon Haase and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},year = {2022},note = {https://pyimg.co/3cpmz},
}
注意:这里的翻译并没有寻求作者的授权!所以我选了原创......我不知道是否恰当!




 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 
