肝了几个周末,万字长文吐血总结Linux命令以及面试实例分享!如果觉得文章还不错的,欢迎点赞关注哦!

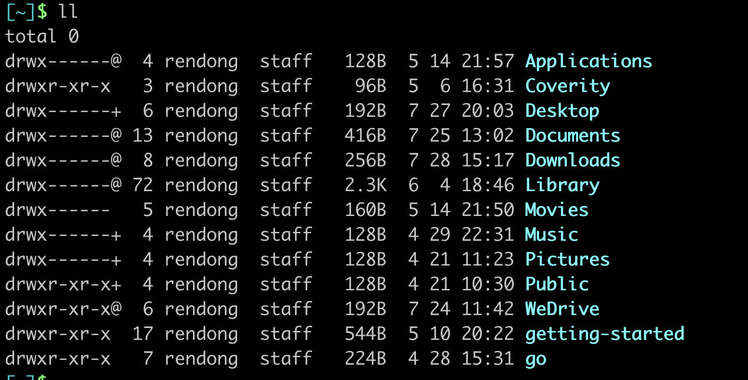
罗列出当前文件或目录的详细信息,含有时间、读写权限、大小、时间等信息
ll是ls -l的别名,可以理解为 ll 和 ls -l 的功能是相同的。
-c或-h,否则将不存在的FILE参数创建为空。#创建三个文件
$ touch test1 test2 test3#不创建文档
$ touch -c test5
$ ls
test1 test2 test3#可以看到只创建了test1、test2、test3 , -c不建立任何文件
FILE或标准输入连接到标准输出。$ cat test #展示文件内容-A, --show-all 等价于 -vET
-b, --number-nonblank 对非空输出行编号$ cat -n test #展示文件内容并且展示行号1 -A, --show-all 等价于 -vET2 -b, --number-nonblank 对非空输出行编号# 把 log2012.log 的文件内容加上行号后输入 log2013.log 这个文件里
$ cat -n log2012.log log2013.log#把 log2012.log 和 log2013.log 的文件内容加上行号(空白行不加)之后将内容附加到 log.log 里
$ cat -b log2012.log log2013.log log.log
$ tac test-b, --number-nonblank #对非空输出行编号
-A, --show-all # 等价于 -vET
chmod可以控制文件如何被他人所调用。chmod abc file #其中a,b,c各为一个数字,分别表示User、Group、及Other的权限。r=4,w=2,x=1 #r 表示可读取,w 表示可写入,x 表示可执行若要rwx属性则4+2+1=7;
若要rw-属性则4+2=6;
若要r-x属性则4+1=5。比如:
chmod 777 file
chmod 700 file
#当前工作目录下创建名为 t 的文件夹
$ mkdir t#在 tmp 目录下创建路径为 test/t1/t 的目录,若不存在,则创建
$ mkdir -p /tmp/test/t1/t
#切换到目录/
$cd /
-i, —interactive 进行交互式删除-r, -R, —recursive 指示rm将参数中列出的全部目录和子目录均递归地删除。-d, --dir删除空目录$ rm -rf linux #删除目录成功,
$ rmdir == rm -d 删除空目录
$ mv test.log test1.txt #将文件 test.log 重命名为 test1.txt$ mv log1.txt,log2.txt,log3.txt /test3 #将文件 log1.txt,log2.txt,log3.txt 移动到根的 test3 目录中
-i提示-r 复制目录及目录内所有项目-a 复制的文件与原文件时间一样$ cp -ai a.txt test #复制 a.txt 到 test 目录下,保持原文件时间,如果原文件存在提示是否覆盖。
$ echo "change world" #打印change world
change world $ echo $PWD #s输出PWD环境变量的值,$PWD 是取当前路径,然后echo到标准输出,,一般echo \$name 用来查看某个环境变量的值
/Users/localhost/test
-n 展示前n行-c 展示前n个字符$ head -n15 test.txt #展示15行$ head -c23 test.txt #展示前23个字符,中文一个汉字并非一个字符的(utf-8编码中文字符长度是可变的)
-f 循环读取&#xff08;常用于查看递增的日志文件&#xff09;-n<行数> 显示行数&#xff08;从后向前&#xff09;日志文件没办法用vim或者cat这样去看&#xff0c;一般常用tail、grep或者more
cat, more 会以一页一页的显示方便使用者逐页阅读&#xff0c;cat命令是全部读取输出到标准输出&#xff0c;如果文件太大会把屏幕刷满的&#xff0c;根本没办法看。
$ more &#43;3 text.txt #显示文件中从第3行起的内容
$ ls -l | more -5 #在所列出文件目录详细信息&#xff0c;借助管道使每次显示 5 行
less 与 more 类似&#xff0c;但使用less 可以随意浏览文件&#xff0c;而 more仅能向前移动&#xff0c;却不能向后移动&#xff0c;而且 less 在查看之前不会加载整个文件$ ps -a | less -N #-N 显示每行的行号 # ps 查看进程信息并通过 less 分页显示
wc(word count)功能为统计指定的文件中字节数、字数、行数&#xff0c;并将统计结果输出-c 统计字节数-l 统计行数-m 统计字符数-w 统计词数&#xff0c;一个字被定义为由空白、跳格或换行字符分隔的字符串$ wc -l test.txt #统计文件行数 26 test.txt
$ date2019年12月22日 星期日 21时28分29秒 CST$ date &#39;&#43;%c&#39;日 12/22 21:28:33 2019
$ which ls # 查看指令"ls"的绝对路径
/bin/ls ##ls可执行程序的绝对路径
$ whereis locate #查找 locate 程序相关文件$ whereis -s locate #查找 locate 的源码文件
$ nl test.txt
$ find /user -name &#39;*.log&#39; -print # 在user目录查找 以 .log 结尾的文件,并打印输出 . 代表当前目录
$grep &#39;20:[0-5][0-9]:&#39; *.log #匹配当前目录下搜索log日志中&#xff0c;20点的日志
$grep &#39;20:[0-5][0-9]&#39; 1.log 2.log 3.log #指定在这三个文件中查找#grep规则是支持正则表达式的$ps -ef|grep java #查找所有java进程,-c可以统计查找的个数 $grep &#39;20:[1-5][0-9]:&#39; *.log | grep -v &#39;20:[3-4][0-9]:&#39; # -v反向选择&#xff0c;相当于过滤
$grep &#39;ab|bc&#39; *.log #支持|语法&#xff0c;匹配含有ab或者bc的文本行
-b&#xff1a;仅显示行中指定直接范围的内容&#xff1b;-c&#xff1a;仅显示行中指定范围的字符&#xff1b;-d —delimiter指定分割符&#xff08;默认是以tab键作为分割符&#xff09;-f —fields指定分割的区域&#xff08;常和-d参数配合使用&#xff09;#通过linux命令吧这个文本里面的hello world搞成十行&#xff0c;并且取出每一列的第七个字符。
$ cat tmp.cc| >>tmp.cc|>>tmp.cc|>>tmp.cc|head -n10|>tmp.cc|cut -c7-7$cut -c-10 tmp.txt #cut tmp.txt文件的前10列
$cut -c3-5 tmp.txt #cut tmp.txt文件的第3到5列
$cut -c3- tmp.txt #cut tmp.txt文件的第3到结尾列cut -d "|" -f 1 #指定&#xff5c;作为分割符,取第一个域
$ diff testA.txt testB.txt
打包是指将一大堆文件或目录变成一个总的文件&#xff1b;压缩则是将一个大的文件通过一些压缩算法变成一个小文件
$tar -cvf test.tar test.txt #打包 tar -cvf 包名 文件名$tar -xvf test.tar #解包 tar -xvf 包名 $tar -zcvf test.tgz test.txt #压缩 tar -czvf 包名 文件名$tar -zxvf test.tgz #解压 tar -xzvf 包名
*.gz 的压缩文件&#xff1a;gzip test.txt*.gz 文件&#xff1a;gzip -d test.txt.gz*.zip 文件&#xff1a;unzip test.zip 。*.zip 文件的内容&#xff1a;unzip -l jasper.zipawk &#39;{pattern &#43; action}&#39; {filenames}
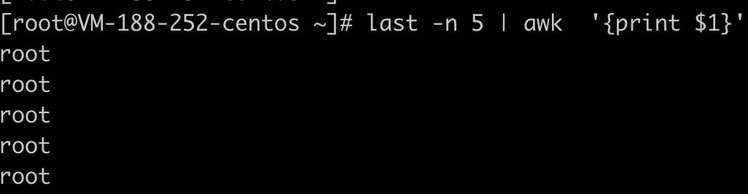
last -n 5的输出如下:

显示最近登录的5个帐号:
awk工作流程&#xff1a;
\n换行符分割的一条记录&#xff0c;然后将记录按指定的域分隔符划分域&#xff0c;$0则表示所有域$1表示第一个域,$n表示第n个域。$1表示登录用户&#xff0c;$3表示登录用户ip,以此类推。-i选项或者将结果重定向到新的文件中。sed 后面接的动作&#xff0c;请务必以‘’ 两个单引号括住&#xff01;$ nl /etc/passwd | sed &#39;2,5d&#39; #删除2-5行
$ nl /etc/passwd | sed &#39;2d&#39; #只删除第2行
$ nl /etc/passwd | sed &#39;3,$d&#39; #删除3到最后一行
:w 保存文件:w vpser.net 保存至vpser.net文件:q 退出编辑器&#xff0c;如果文件已修改请使用下面的命令:q! 退出编辑器&#xff0c;且不保存:wq 退出编辑器&#xff0c;且保存文件/dong 向光标下搜索dong字符串&#xff0c;dong可以是正则表达式
?dong 向光标上搜索dong字符串
n 向下搜索前一个搜索动作
N 向上搜索前一个搜索动作
* (#) 当光标停留在某个单词上时, 输入这条命令表示查找与该单词匹配的下(上)一个单词. 同样, 再输入 n查找下一个匹配处, 输入N 反方向查找.
g*(g#) 此命令与上条命令相似, 只不过它不完全匹配光标所在处的单词, 而是匹配包含该单词的所有字符串.
n&#43; 向下跳n行
n- 向上跳n行
nG 跳到行号为n的行
G 跳至文件的底部
$ps -a #查看所有进程
$ps -ef #查看进程的环境变量和程序间的关系
ps -aux | grep kafka #与grep联用查找某进程
发送指定的信号到相应进程。不指定型号将发送SIGTERM&#xff08;15&#xff09;终止指定进程。
如果任无法终止该程序可用"-KILL" 参数&#xff0c;其发送的信号为SIGKILL(9) &#xff0c;将强制结束进程&#xff0c;使用ps命令或者jobs 命令可以查看进程号。
$ ps -ef | grep kafka #先使用ps查找进程kafka&#xff0c;
$ kill -9 pid #然后用kill杀掉 kill -9 强制终止
#展示当前系统磁盘使用情况&#xff0c;以可读的方式展示
$ df -h
$du -h filename #查看指定文件大小
$du -h / #展示该目录下所有文件大小&#xff0c;大小以可读方式展示
$du -sh #展示当前目录大小
$du -sh ./ #展示当前目录下每个目录大小
$du -ah / #显示所有文件的大小&#xff0c;以可读方式展示
在linux环境下&#xff0c;任何事物都以文件的形式存在&#xff0c;即一切皆文件&#xff01;
$ lsof #显示当前系统打开的文件
$ lsof /bin/bashCOMMAND #查看某个文件的相关进程 lsof 文件名
$ lsof -u username#查看某个用户打开的文件信息
$ lsof -c java #列出某个程序进程所打开的文件信息
ping命令主要用来测试主机之间网络的连通性
执行ping指令会使用ICMP传输协议&#xff0c;发出要求回应的信息&#xff0c;若远端主机的网络功能没有问题&#xff0c;就会回应该信息&#xff0c;因而得知该主机运作正常。
ICMP&#xff08;Internet Control Message Protocol&#xff09;Internet控制消息协议。 它是TCP/IP协议簇的一个子协议&#xff0c;用于在IP主机、路由器之间传递控制消息。控制消息是指网络通不通、主机是否可达、路由是否可用等网络本身的消息。
网络延时指**一个数据包从用户的计算机发送到网站服务器&#xff0c;然后再立即从网站服务器返回用户计算机的来回时间**。 通俗的讲&#xff0c;就是数据从电脑这边传到那边所用的时间。
$ ping -c 10 host #ping指定次数
$ ping -c 10 -i 0.5 host #ping指定时间间隔和次数限制$ ping -c 4 -i 3 www.linuxcool.com # 连续ping4次&#xff0c;每次间隔3秒&#xff0c;检查与linuxcool的连通性
telnet命令用于远端登入。
执行telnet指令开启终端机阶段作业&#xff0c;并登入远端主机
$ telnet 192.168.120.209Trying 192.168.120.209...
telnet: connect to address 192.168.120.209: No route to host
telnet: Unable to connect to remote host: No route to host
在Linux使用过程中&#xff0c;需要了解当前系统开放了哪些端口&#xff0c;并且要查看开放这些端口的具体进程和用户&#xff0c;可以通过netstat命令进行简单查询
$ netstat -a #列出所有端口使用情况
$ netstat -nu #显示当前UDP连接状况
$ netstat -apu #显示UDP端口号的使用情况
$ netstat -i #显示网卡列表
ifconfig 用于查看和配置 Linux 系统的网络接口。
$ ifconfig #显示网络设备信息
$ ifconfig eth0 up $ifconfig eth0 down #启动关闭指定网卡
$ ifconfig eth0 ip #配置IP地址
$ hostname -i #查看主机ip

wget命令用来从指定的URL下载文件
wget -c http://xxx.zip ##断点续传
curl -d ##HTTP POST方式传送数据
管道 (pipeline) ,连结上个指令的标准输出&#xff0c;做为下个指令的标准输入。
常出现在流程控制中&#xff0c;扮演括住判断式的作用
这组符号与先前的 [] 符号&#xff0c;基本上作用相同&#xff0c;但她允许在其中直接使用|| 与&&逻辑等符号
反斜杠的作用是将特殊符号字符的特殊含义屏蔽掉&#xff0c;使其还是原字符
sh里没有多行注释&#xff0c;只能每一行加一个#号
把cmd命令的输出重定向到文件file中。如果file已经存在&#xff0c;则清空原有文件&#xff0c;使用bash的noclobber选项可以防止复盖原有文件。
**>> **
把cmd命令的输出重定向到文件file中&#xff0c;如果file已经存在&#xff0c;则把信息加在原有文件後面。
单一个& 符号&#xff0c;且放在完整指令列的最后端&#xff0c;即表示将该指令列放入后台中工作。
代表 or 逻辑的符号。
代表 and 逻辑的符号
匹配一个任意的字符
禁止插入换行符。
对转义字符进行替换
$直接引用变量
**$?上一次命令的返回值。**0表示执行成功&#xff0c;非零值表示出错
$()执行并获取命令输出赋值给变量
${}作为单词边界
${#}获取变量字符串长度
双引号"括起来的字符串支持变量插值&#xff0c;被双引号用括住的内容&#xff0c;将被视为单一字串
单引号&#39;括起来的字符串不会进行插值
$[]对表达式进行求值&#xff0c;与expr命令不同的是&#xff0c;$[]用于插值&#xff0c;而expr则将值输出
$$获取当前进程ID
for i in &#96;seq 1 10&#96;;
-f&#xff1a;仅删除函数&#xff1b;-v&#xff1a;仅删除变量。echo "aab12" | sed &#96;s/\(.*\)/\1/&#96; -----> aab12
s命令会用斜线间指定的第二个文本字符串来替换第一个文本字符串
\1 就代表被匹配到的第一个模式
-e 以选项中指定的script来处理输入的文本文件。
set指令能设置所使用shell的执行方式&#xff0c;可依照不同的需求来做设置
-x 执行指令后&#xff0c;会先显示该指令及所下的参数。用于脚本调试&#xff0c;在liunx脚本中可用set -x就可有详细的日志输出.免的老是要echo了
-e 若指令传回值不等于0&#xff0c;则立即退出shell
文件开头加上set -e,这句语句告诉bash如果任何语句的执行结果不是true则应该退出,如果要增加可读性&#xff0c;可以使用set -o errexit&#xff0c;它的作用与set -e相同。
if [[ x"$var" &#61;&#61; x"3"]];thenecho "$var"
fi
x防止出现语法错误。如果不写x&#xff0c;只用if [ “${var}" &#61;&#61; “0” ]来判断${var}的值&#xff0c;当${var}为空或未设置时&#xff0c;语句被解释为if [ &#61;&#61; "0" ]&#xff0c;出现语法错误。加上x后&#xff0c;当${var}为空或未设置时&#xff0c;解释为if [ “x" &#61;&#61; "x" ]&#xff0c;依然正确。
-e参数来打印转义字符echo &#96;date&#96; #显示当前日期
echo -e "\n" #打印换行符
source FileName #在当前bash环境下读取并执行FileName中的命令。
mkdir -p data/env #-p 确保目录名称存在&#xff0c;不存在的就建一个
function demo(){if [[ x"$var" &#61;&#61; x"2" ]];thenecho "$var"fi
}
echo hello world 123 | tr -d &#39;0-9&#39; ##删除字符串中的数字
hello worldecho hello world 123 | tr -d -c &#39;0-9&#39; #-c选项表示取反
123echo hello world | tr -s &#39; &#39; #s选项加上空格参数表示将多个空格压缩为单个
hello worldecho hello world | tr [a-zA-Z] [n-za-mN-ZA-M] ##rot13加密算法&#xff0c;这个算法简单地将英文字母后移13位
uryyb jbeyq
-f: 强制创建物理卷&#xff0c;不需要用户确认
-u: 设置设备的UUID
-y: 所有的问题都回答yes
-l # 逻辑卷大小-n # 逻辑卷名字mkfs.ext3 /dev/sda6 # 把该设备格式化成ext3文件系统
exit [状态值] ##使shell以指定的状态值退出,状态值0代表执行成功&#xff0c;其他值代表执行失败
-i 显示套件的相关信息。-h 套件安装时列出标记-v 显示指令执行过程^once #匹配以once开头的字符串
在一组方括号里使用 ^ 时&#xff0c;它表示"非"或"排除"的意思&#xff0c;常常用来剔除某个字符
^[^0-9][0-9]$ #第一个字符非数字&#xff0c;第二个字符为数字。如&1、%2
[^a-z] ##除了小写字母以外的所有字符
[^\\\/\^] ##除了(\)(/)(^)之外的所有字符
[^\"\&#39;] ##除了双引号(")和单引号(&#39;)之外的所有字符
bucket$ #匹配以bucket结尾的字符串
^abcd$ #精确匹配&#xff0c;只匹配abcd字符串
所有的转义序列都用反斜杠 \打头
^\t #匹配以制表符开头的字符串
\n
\\
\.
匹配前面的子表达式零次或一次。例如&#xff0c;“do(es)?” 可以匹配 “do” 或 “does” 。? 等价于 {0,1}。
**匹配前面的子表达式零次或多次。例如&#xff0c;zo 能匹配 “z” 以及 “zoo”。 等价于{0,}。
与 {1,} 是相等的&#xff0c;匹配前面的子表达式一次或多次。
匹配除换行符&#xff08;\n、\r&#xff09;之外的任何单个字符。要匹配包括 ‘\n’ 在内的任何字符&#xff0c;请使用像"(.|\n)"的模式。
匹配一个单词边界&#xff0c;也就是指单词和空格间的位置。例如&#xff0c; ‘er\b’ 可以匹配"never" 中的 ‘er’&#xff0c;但不能匹配 “verb” 中的 ‘er’
前面的字符或字符簇只出现n次
前面的内容出现n或更多的次数
前面的内容至少出现n次&#xff0c;但不超过m次
[a-z] # 匹配所有的小写字母
[A-Z] # 匹配所有的大写字母
[a-zA-Z] # 匹配所有的字母
[0-9] # 匹配所有的数字
[0-9\.\-] # 匹配所有的数字&#xff0c;句号和减号
[ \f\r\t\n] # 匹配所有的白字符
/[A-Za-z0-9]/ #匹配所有的字母和数字
^[a-zA-Z_]$ #所有的字母和下划线
^a$ #字母a
^a{4}$ #aaaa
^a{2,4}$ #aa,aaa或aaaa
^a{2,}$ #包含多于两个a的字符串
^a{2,} #如&#xff1a;aardvark和aaab&#xff0c;但apple不行
a{2,} #如&#xff1a;baad和aaa&#xff0c;但Nantucket不行
\t{2} #两个制表符
.{2} #所有的两个字符
^[a-zA-Z0-9_]&#43;$ #所有包含一个以上的字母、数字或下划线的字符串
^[1-9][0-9]*$ # 所有的正整数
^\-?[0-9]&#43;$ # 所有的整数
^[-]?[0-9]&#43;(\.[0-9]&#43;)?$ # 所有的浮点数
ssh -l 用户名 -端口号 服务器ip
输入密码
使用ssh连接远程服务器时&#xff0c;有时一个脚本要执行很长时间&#xff0c;如果没有放在后台独立运行&#xff0c;由于网络波动或者中断都有可能导致命令中断&#xff0c;所以在这里分享一个后台独立运行命令的Tip&#xff0c;亲测好用&#xff0c;棒棒哒&#xff01;
nohup ./main &
此后&#xff0c;如果你断开了ssh&#xff0c;程序依旧运行。此种方式的缺点是&#xff0c;应用程序没有交互界面了&#xff0c;程序的输出将会输出的一个xxx.out文件中&#xff0c;而且以后无法在界面控制程序的结束。必须通过kill的方式。所以这种方式显得很简单粗鲁&#xff0c;很少使用。
screen
回车后进入Screen子界面&#xff0c;此时putty标题栏会指示处于子界面状态&#xff0c;然后运行你的程序
./main
然后按下Ctrl&#43;A后抬起&#xff0c;然后按下d键&#xff0c;此时切换回主界面&#xff0c;Putty的窗口标题栏也会指示。
进行其他的操作&#xff0c;或者exit
此时就是断开ssh,程序仍在运行。以后重新ssh连接后&#xff0c;输入
screen -ls
查看子界面的代号&#xff0c;然后输入
screen -r 子界面代号
就可以查看当初你程序运行所在的子界面了
Linux下有三个命令&#xff1a;ls、grep、wc。通过这三个命令的组合可以统计目录下文件及文件夹的个数。
$ ls -l | grep "^-" | wc -l
$ ls -lR| grep "^-" | wc -l
$ ls -lR | grep "^d" | wc -l
ls -l长列表输出该目录下文件信息(注意这里的文件是指目录、链接、设备文件等)&#xff0c;每一行对应一个文件或目录&#xff0c;ls -lR是列出所有文件&#xff0c;包括子目录。
grep "^-"ls的输出信息&#xff0c;只保留一般文件&#xff0c;只保留目录是grep "^d"。wc -lvim 会一次性把文件load到内存,不可取
cat会一次性输出文件的所有内容&#xff0c;用cat来读取16G的文件&#xff0c;你只能看到在屏幕上不断打印的内容&#xff0c;无法阅读。
如果只看文件的前一部分&#xff0c;用 head -n 就是最佳选择。
less/more并不需要加载全部文件&#xff0c;因此在打开大文件的时候&#xff0c;less/more具有优势。但使用 less 可以随意浏览文件&#xff0c;而 more 仅能向前移动&#xff0c;却不能向后移动
使用top命令查看负载&#xff0c;在top下按“1”查看CPU核心数量&#xff0c;shift&#43;"c"按cpu使用率大小排序&#xff0c;shif&#43;"p"按内存使用率高低排序&#xff1b;
使用iostat -x命令来监控io的输入输出是否过大
查找单词名称&#xff1a;test
操作命令&#xff1a;
&#xff08;1&#xff09;more xxx.log | grep -o test | wc -l ### word count -list
&#xff08;2&#xff09;cat xxx.log | grep -o test | wc -l
&#xff08;3&#xff09;grep -o test xxx.log | wc -l
方法1: lsof命令,即ls open files
$ lsof -i:端口号
方法2: netstat命令
$ netstat -tunpl | grep 端口号
1.touch hello.sh2.vim hello.sh 键入i 插入#!/bin/shecho hello world;键入: esc :wq
3.chmod 700 hello.sh//给予用户权限4. 执行./hello.sh 或者执行 sh hello.sh
在 if-then 中使用测试命令&#xff08; -gt 等&#xff09;来比较两个数字。
#!/bin/bash //这一行 一定要有 &#xff0c;表示命令通过 /bin/bash 来执行
x&#61;10
y&#61;20
if [ $x -gt $y ]
then
echo “x is greater than y”
else
echo “y is greater than x”
fi
#其他比较命令
-eq //等于
-ne //不等于
-gt //大于 &#xff08;greater &#xff09;
-lt //小于 &#xff08;less&#xff09;
-ge //大于等于
-le //小于等于
在linux 中 命令执行状态&#xff1a;0 为真&#xff0c;其他为假
/dev 目录下&#xff1f;read 命令可以读取来自终端&#xff08;使用键盘&#xff09;的数据。-p后面跟提示信息&#xff0c;即在输入前打印提示信息。
#!/bin/bash
read -p "Input file name: " FILENAME
if [ -c "$FILENAME" ];thencp $FILENAME /dev
fi
/tmp/input.txt 文件的内容&#xff1f;要求&#xff1a;
[root&#64;~]## cat -n /tmp/input.txt1 00001111122223 0000111112222224 11111000000222567 1111111111111222222222228 22111111119 11222222210 112211## 删除所有空行命令
[root&#64;~]## sed &#39;/^$/d&#39; /tmp/input.txt
000011111222
000011111222222
11111000000222
111111111111122222222222
2211111111
112222222
1122## 插入指定的字符
[root&#64;~]## sed &#39;s#\(11111\)#AAA\1BBB#g&#39; /tmp/input.txt
0000AAA11111BBB222
0000AAA11111BBB222222
AAA11111BBB000000222
AAA11111BBBAAA11111BBB11122222222222
22AAA11111BBB111
112222222
1122
【面试系列】计算机网络&#xff08;一&#xff09;
【面试系列】计算机网络&#xff08;二&#xff09;
【面试系列】常考web安全问题总结
30道计网常考面试题总结
【面试系列】会持续更新&#xff0c;欢迎关注公众号“任冬学编程”&#xff0c;一起学习与进步&#xff01;






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 