作者:275514908_9369d7 | 来源:互联网 | 2023-07-11 08:54
1. 二阶导数信息
GBDT在优化时只用到了一阶导数信息,而XGBoost则对损失函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。
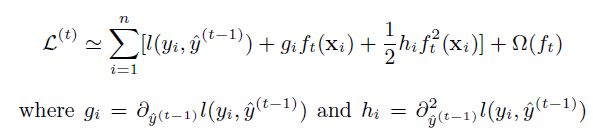
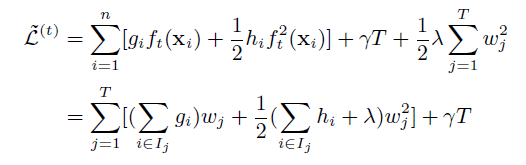
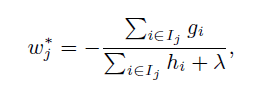
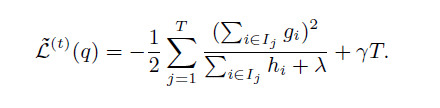
2. 防止过拟合
(1)正则项
XGBoost在代价函数里添加了正则项,用于控制模型的复杂度。正则项包括叶子结点的个数以及叶子节点值的L2范数。从Bias-variance tradeoff的角度来讲,增大偏差,减小方差。
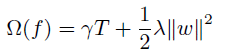
(2)shrinkage
XGBoost在每次学习得到一棵新的子树之后,会将叶子结点的值乘上一个大于0小于1的数,目的是为了削弱每一棵子树对整体模型的影响,让后面有更大的学习空间。
(3)column subsampling
XGBoost借鉴了随机森林的思想,支持列抽样,即特征随机性,不仅能有效地防止过拟合,还能加速计算。
3. 并行计算
(1)block结构
这里的并行计算并不是指树粒度上的并行,而是指特征粒度上的并行。XGBoost在训练之前,首先将数据的全部特征进行了排序,并保存为block结构,因此在寻找最佳分割点时,可以同时对多个特征进行求解。
(2)近似直方图法
相比于GBDT采用贪心算法来计算最佳分割点,XGBoost在计算最佳分割点时采用近似直方图法,先提出候选分割点,并行计算得到最佳分割点所在的区间,然后在该区间内的所有可能分割点中选择最佳分割点。
4. 缺失值处理
(1)训练时
XGBoost在寻找最佳分割点时不会考虑缺失值的影响,而在最佳分割点确定之后会将缺失数据分别放到左子树和右子树中计算损失,并选择较优的那一个。
(2)预测时
如果在预测时出现了缺失数据,XGBoost会自动将其分到右子树。




 京公网安备 11010802041100号
京公网安备 11010802041100号