转载请注明原文地址:https:www.cnblogs.comygj0930p10923221.html一:Memcache是什么,为什么要用它MemCache是一个
转载请注明原文地址:https://www.cnblogs.com/ygj0930/p/10923221.html
一:Memcache是什么,为什么要用它
MemCache是一个高性能、“分布式”的内存缓存系统,它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高了网站访问的速度,减轻数据库的负载。
MemCaChe是一个存储键值对的HashMap,在内存中对任意的数据(比如字符串、对象等)使用key-value形式进行存储。
数据可以来自数据库查询、API调用结果返回,或者网页传输过来的数据(session信息、request信息或者所携带的参数)。
二:Memcache安装与运维
1、在本机或者集群服务器上安装Memcache
(Ubuntu/Debian)
sudo apt-get install libevent ibevent-dev
sudo apt-get install memcached
(Redhat/Fedora/Centos)
yum install libevent libevent-devel
yum install memcached
2、启动memcache:使用 memcached命令
cd到memcached目录/bin下,通过 memcached [-options][value] 来启动memcache。
启动选项:
- -d是启动一个守护进程;
- -m是分配给Memcache使用的内存数量,单位是MB;
- -u是运行Memcache的用户;
- -l是监听的服务器IP地址,可以有多个地址;
- -p是设置Memcache监听的端口,,最好是1024以上的端口;
- -c是最大运行的并发连接数,默认是1024;
- -P是设置保存Memcache的pid文件。
3、memcache服务器运维
我们还可以在终端窗口使用telnet指令,通过IP和端口连接到memcache服务器进行操作。
4、memcache操作指令
1)存储指令

2)查找与操作指令

3)运维指令

三:Memcache在开发中的应用——Java
1、添加依赖
2、连接memcache服务器
// 连接 Memcached 服务,创建memcache客户端对象
MemcachedClient mcc = new MemcachedClient(new InetSocketAddress("ip", port));
3、通过memcache对象调用api进行存储、查找操作,api的参数同上面第二点中的指令参数
// 存储数据
Future fo = mcc.set(key, 有效期, 值);
//查找数据
mcc.get(key)
4、操作完成后关闭连接,以免占用memcache服务器资源
四:Memcache深入解读
1、memcache与redis的区别和联系
1)存储数据类型区别
redis:支持较多的数据类型(String/list/set/sortset/hash)作为值;每个value最大数据存储量为1G;支持持久化;目前只支持在linux下运行。
memcache:各种框架(tp/yii等等)都支持使用;session的信息可以非常方便的保存到memcache中,每个key保存的数据量最大为1M;不支持持久化,断电重启就没有了。
2)分布式模式区别
redis:主从模式,一个redis负责数据写入,其他多个redis负责数据读取。
memcache:平均分摊模式,每个子服务器之间都是平级的,每个服务器都要执行数据的写入、读取操作。
3)联系
两者都是把数据保存在内存中,优化数据存取速度。
2、memcache的数据类型存储
1)基本数据类型——转化为String字符串格式来存储
2)引用类型对象——原型存储
由于原型存储对资源的消耗比较大,为了节省资源,可以把引用类型信息都变为字符串形式进行存储,这时需要进行 序列化 操作。
3、memcache的分布式
memcache的分布式 不是通过架构手段去实现的,我们只需要部署多台memcache服务器,然后在代码中为memcache对象添加多个server即可。
其分布式特性是内置好了的,无需我们再通过架构手段实现一遍。
memcache本身有算法,可以保证数据“平均”地存储在不同的服务器里边。【注意:是平均,而不是复制,各台memcache中存储的内容是不同的。】

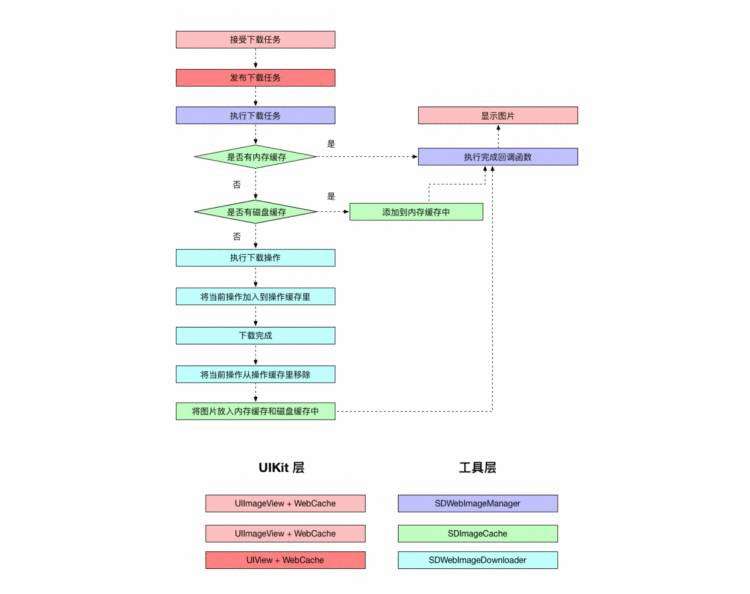
4、Memcache的访问模型(参考:https://www.cnblogs.com/xrq730/p/4948707.html)

MemCache虽然被称为"分布式缓存",但是MemCache本身完全不具备分布式的功能,MemCache集群之间不会相互通信(与之形成对比的,比如JBoss Cache,某台服务器有缓存数据更新时,会通知集群中其他机器更新缓存或清除缓存数据),所谓的"分布式",完全依赖于客户端程序的实现[通过代码]。
MemCache一次写缓存的流程:
1)应用程序输入需要写缓存的数据
2)API将Key输入路由算法模块,路由算法根据Key和MemCache集群服务器列表得到一台服务器编号
3)由服务器编号得到MemCache及其的ip地址和端口号
4)API调用通信模块和指定编号的服务器通信,将数据写入该服务器,完成一次分布式缓存的写操作
读缓存和写缓存一样,只要使用相同的路由算法和服务器列表,只要应用程序查询的是相同的Key,MemCache客户端总是访问相同的客户端去读取数据,只要服务器中还缓存着该数据,就能保证缓存命中。
5、memcache路由算法(参考:https://www.cnblogs.com/xrq730/p/4948707.html)
1)余数Hash策略
例如,key的HashCode为50,memcache服务器有3台,则key.hashcode % 3 == 2,路由算法将key路由到第二台服务器上进行存储。
原理:由于hashcode的随机性,可以保证数据“较为平均”地分布在memcache服务器集群中。
缺点:服务器集群伸缩性差。当memcache服务器集群横向扩展时,服务器数量变化,会导致同样的key路由到新的服务器上,而旧路由器上的值不会被清除。
解决方案:
(1)在网站访问量低谷时段,通常是深夜,技术团队加班,扩容、重启服务器;
(2)然后通过模拟请求的方式,对缓存内容重新读写一遍,逐渐预热缓存,使缓存服务器中的数据重新分布;
2)一致性Hash算法
一致性Hash算法通过一个叫做一致性Hash环的数据结构实现Key到缓存服务器的Hash映射。
我们将服务器节点分布在Hash环上,每个key路由时,指向该key沿着hash环顺时针最近的服务器节点上。
例如:服务器扩展前的Hash环

当我们新增了一台服务器时,环上新增了一个节点:

这样会导致上图中加粗部分缓存内容被重新分布,但相比第一种策略,这样已经优化了好多倍了。并且,集群中缓存服务器节点越多,增加节点带来的影响越小。
6、memcache的存储原理(参考:https://www.cnblogs.com/xrq730/p/4948707.html)
MemCache采用的内存分配方式是 固定空间分配:

1)MemCache将内存空间分为一组slab
2)每个slab下又有若干个page,每个page默认是1M,如果一个slab占用100M内存的话,那么这个slab下应该有100个page
3)每个page里面包含一组chunk,chunk是真正存放数据的地方,同一个slab里面的chunk的大小是固定的
4)有相同大小chunk的slab被组织在一起,称为slab_class
如果slab中没有chunk可以分配了怎么办:如果MemCache启动没有追加-M(禁止LRU,这种情况下内存不够会报Out Of Memory错误),那么MemCache会把这个slab中最近最少使用的chunk中的数据清理掉,然后放上最新的数据。
为什么MemCache存放的value大小是限制的:因为一个新数据过来,slab会先以page为单位申请一块内存,申请的内存最多就只有1M,所以value大小自然不能大于1M了。
7、memcache的特性与限制
1)MemCache中可以保存的item数据量是没有限制的,只要内存足够
2)MemCache单进程在32位机中最大使用内存为2G,64位机则没有限制
3)Key最大为250个字节,超过该长度无法存储
4)单个item最大数据是1MB,超过1MB的数据不予存储
5)MemCache服务端是不安全的,比如已知某个MemCache节点的ip和port,可以直接telnet过去,并通过flush_all让已经存在的键值对立即失效
6)不能够遍历MemCache中所有的item,因为这个操作的速度相对缓慢且会阻塞其他的操作
7)MemCache的高性能源自于两阶段哈希结构:第一阶段在客户端,通过Hash算法根据Key值算出一个节点;第二阶段在服务端,通过一个内部的Hash算法,查找真正的item并返回给客户端。
8)MemCache设置添加某一个Key值的时候,传入expiry为0表示这个Key值永久有效,然而这个Key值也会在30天之后失效,这是在源码中写死了的。
五:常见的memcache使用
1、session共享
一个大型网站或系统,往往部署在多台服务器上。多台服务器彼此之间需要共享session信息,这时可以把session缓存在memcache中,而各服务器都可以从memcache中提取session进行分布式处理的同时又能保持一致性。
2、网页内容缓存
网站有一个页面需要获得许多数据信息,并且这些数据信息在短时间内不会发生变化时。可以把这些数据获得出来存入到memacache中过去,供后续访问。




 京公网安备 11010802041100号
京公网安备 11010802041100号