作者:林立霞61556 | 来源:互联网 | 2023-07-29 15:13
本文主要来源:阿里云天池技术圈常用推荐算法(50页干货)
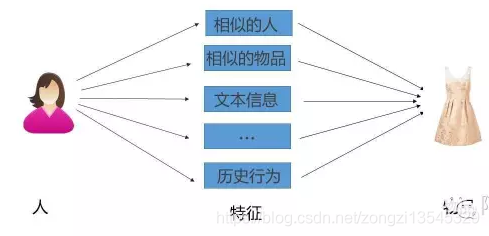
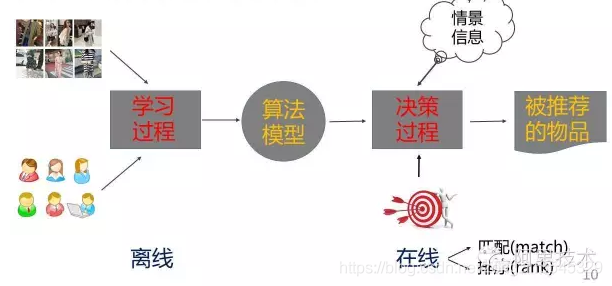
主要内容 一.推荐系统简介 信息过载过滤 出用户需要的信息。 信息过滤三种方法: 推荐系统的发展史(略) 推荐系统的应用和价值(略) 推荐系统的评价标注 (重要):推荐系统的核心问题: 影响推荐效果的因素 推荐算法的两个阶段 二.传统的推荐算法 非个性化推荐:热度排行 协同过滤: Memory-based(aka neighborhood-based)方法:Item-based/user-based CF Model-based方法:频繁项挖掘/聚类/分类/回归/矩阵分解/RBM/图模型 基于内容/知识的推荐(Content-based/Knowledge-based) 混合方法(Hybird Approaches) 热度排行 不同的排行榜算法: 单一维度的投票(旧版的Delicious) 多个维度综合打分 加入时间因素:引入衰减权重(半衰期、冷却定律) (Hacker News) 考虑反馈信息:如Reddit算法 考虑置信度:如威尔逊区间 防止马太效应:如MAB算法等 评价 容易实现 更新慢,难以推新 排行榜更多是业务问题而不是算法问题 协同过滤(Collaborative Filtering) 思想来源(略) 基本组成元素: N个用户,M个物品 评分矩阵:用户对物品的评分(显式)或用户对物品的行为(隐式) 相似性度量:物品与物品(人与人) 之间的相似性 Memory-based 将用户的所有数据读入内存中进行运算,所以被称为Memory-based
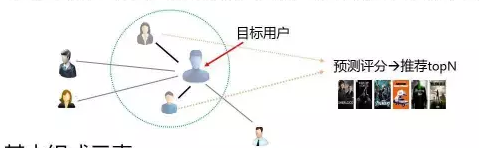
User-based CF 算法步骤
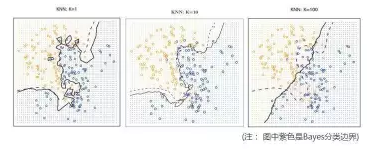
Step1 协同(在线) 相似性度量:Pearson相关系数、Jaccard距离、cosine相似性 Step2 找出相似用户喜欢的物品,并预测目标用户对这些物品的评分 Step3 过滤(离线) Step4 将剩余物品按照预测评分排序,并返回前N个物品 Item-based CF 2001年,Sarwar等人提出了item-based的CF 2003年,Amazon介绍了其Item-to-item算法 基本思想:计算item之间两两的相似性,目标用户对某个item的评分可以根据其对相似的items的评分来预测,选取用户预测评分最高的前N个商品进行推荐 电商推荐中成为主流的原因: User-based VS Item-based Item-based:准确性好,表现稳定可控,便于离线计算;但是推荐结果多样性会差一些,一般不会有惊喜感 User-based:帮助用户发现新的商品,但是需要复杂的在线计算,需要处理新用户的问题。 Item之间的相似性比较单纯,是静态的;而User之间的相似性比较复杂,而且是动态的,用时需要注意 协同过滤的优缺点 优点 需要很少的领域知识,模型通用性强 工程上实现简单,效果很好 缺点 冷启动问题(new users/items) 数据稀疏性问题 假定"过去的行为决定现在",没有考虑具体情况的差异 热门倾向性(Popularity Bias):很难推荐出小众偏好 最近邻算法
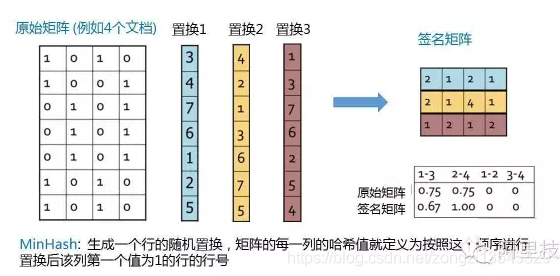
MinHash例子
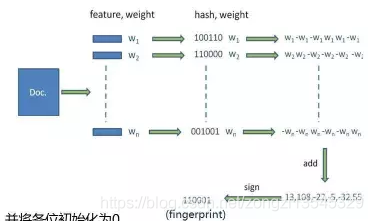
SimHash例子 (感觉这个有点难,后面会重点看)
(这一部分我还没太搞懂,后面应该会专门找一个代码实践一下= =)
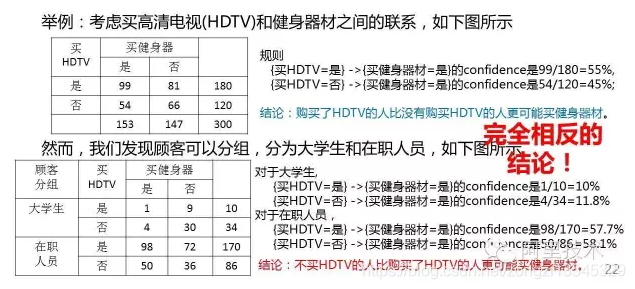
Mode-based CF 关联规则,如Apriori,FP-Growth 聚类 分类/回归模型 隐语义模型,如LSA/pLSA/LDA SVD,SVD++ RBM 图模型,如SimRank,MDP 关联规则(Associate Rule) 基本思想:基于物品之间的共现性挖掘频繁项 一般应用场景:看了又看,买了又买,商品搭配 算法:A-priori、FP-Growth 支持度(support) 置信度(confidence) 评价 实现简单,通用性较强,适合“推荐跟已经购买的商品搭配的商品”等场景 相似商品的推荐效果往往不如协同过滤好 解释变量之间的关联时要特别小心,很可能受一些隐含因素的影响,得出完全相反的结论(辛普森悖论) 辛普森悖论(Simpson’s Paradox) 如图所示的一个例子:
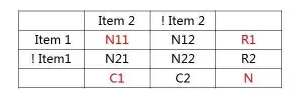
英国统计学家辛普森在1951年提出来的,两组数据分别讨论时都会满足某种性质,可是一旦合并考虑,却可能导致相反的结论。 产生辛普森悖论的主要原因 是数据的不同分组之间基数差异很大(一个组相对于其他组来说数量占绝对优势) 数学解释 结论:分析数据时合理的将数据分组 (分层)很重要 基于统计的相似性 OddsRatioN22)/(N12 N21) 聚类(Clustering)
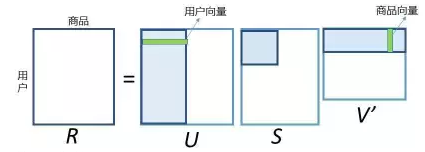
用户分群:同好人群 有时可以带给用户惊喜感,但个性化稍差(人群vs个体) 商品聚类:相似商品 常用算法 K-means,层次聚类(HC) Louvain(2008),基于密度的聚类方法(2014) 评价 聚类可以一定程度解决数据稀疏性问题,捕捉到一些隐(扩展) 聚类的精准度往往不如协同过滤好 分类/回归 基本思想:把评分预测看做一个多分类(回归)问题 常用分类器:LR,Naive Bayes 输入:通常是item的特征向量 评价: 比较通用,可以跟其他方法组合,提高预测的准确性 需要大量训练数据,防止过拟合现象 矩阵分-SVD分解 数学上的SVD 传统SVD应用到推荐中的挑战 SVD要求矩阵必须是稠密矩阵,而评分矩阵非常稀疏 SVD计算复杂度很高,在稠密大规模矩阵上运行速度很慢 ↓↓↓ 下面部分公式因为太难打了都是使用的截图。。。。。 FunkSVD 2006nian ,Simon Funk公布了算法(FunkSVD) 思想:评分矩阵R分解为两个低秩矩阵的乘积 BiasSVD 思想(基本假设) 评分系统有一些跟用户和物品无关的固有属性 用户有一些跟物品无关的固有属性 商品有一些跟用户无关的固有属性
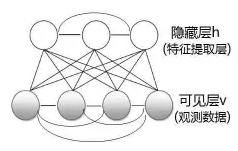
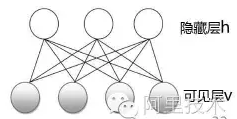
SVD++ 思想:考虑用户的隐式反馈(提供额外的用户偏好信息) Item的向量化 为什么进行向量化 知识、概念的表示 为智能推荐系统的设计提供了强有力的工具 向量化的常用方法 pLSA(Thomas Hofmann,1999) LDA(David M. Blei,2003) Word2Vec(Mikolov,2013) 实际应用的问题 向量化时大多基于行为数据,行为少的item向量化效果不好 限制玻尔兹曼机(RBM) Boltzmann机
两层神经网络(无输出层) 对称、全连接 随机:每个神经元只有两种状态(激活/未激活),通常用0/1表示,但是某一时刻处于哪种状态是随机的,由一定的概率确定 受限Boltzmann机
受限:层内无连接(大大简化计算) RBM中隐藏层的作用 图像去噪和重构的例子
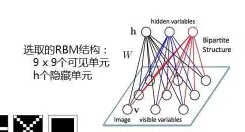
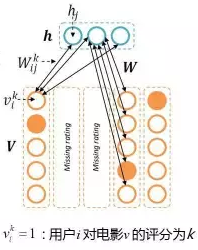
问题:N个用户,M个电泳,评分等级1-k,如何建模?(RBM的结构) 如何处理缺失值? RBM进行评分预测 算法步骤(预测用户u对电影i的评分):
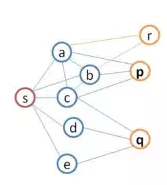
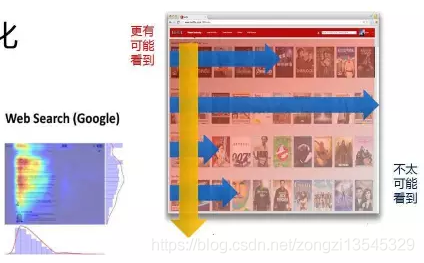
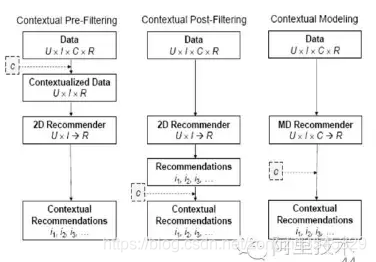
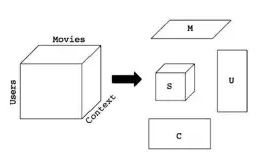
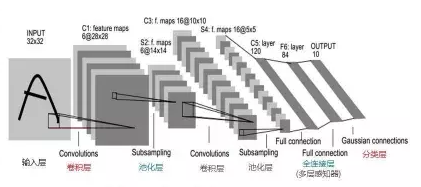
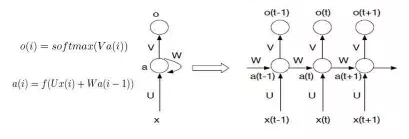
基于图的相似性 多用于社交网络人与人的关系挖掘 图模型 SIMRank(Jeh&Widom,2002) SimRank++(Ioannis Antonellis,2007) 改进1:引入evidence系数(两个节点的共同节点越多越相似) 改进2:考虑的边的权重 Markov模型(n-gram) Markov Decision Process 图模型的评价 借助图的结构的传到辛,可以发现CF发现不了的弱相似性,给推荐带来一定的惊喜性;但是图模型也面临着数据稀疏性问题和冷启动问题。 基于内容/知识的推荐 什么是内容 文本描述:NLP技术挖掘关键词 Item的属性,如电影的主题、衣服的材质等 Item的特征,例如语音信号表示、图像向量表示等 基本组成 item特征向量,如文本的TF-IDF向量 用户profile向量:通常通过用户偏好的item来提取 匹配分:直接计算cosine,分类/回归模型 基于内容推荐的评价: 优点 能够推荐出用户独有的小众偏好 可以一定程度解决数据稀疏问题和item的冷启动问题 通常具有较好的可解释性 不足 对于很多推荐问题,提取有意义的特征不容易 很难将不同的item特征组合在一起(邻域思想) 很难带给用户惊喜性 如果用户的profile挖掘不准,推荐效果往往很差 混合方法(Hybird Approaches) 模型融合方法 加权(weighted)组合 切换(switching)组合:确定一个合理的切换跳进 混合(Mixed) 特征组合(feature combination):不同模型特征组合到一起 特征扩展(feature augmentation):一个模型的输出作为另一个的特征 级联(Cascade):粗排->精排 评价 通常比单个算法表现好 需要在不同算法之间、理论效果和实际可行性之间仔细权衡 三.推荐算法的最新研究 Leaning to Rank 大多数推荐结果是一个列表,因此推荐结果的排序也很重要。 L2R:将排序看做一个ML问题 推荐的评价准则: Normalized Discounted Cumulative Gain(NDCG) Mean Reciprocal Rank(MRR) 问题:难以直接利用这些指标指导学习过程 常用算法 Pointwise:LR,GBDT,SVM Pairwise:RankSVM,RankBoost,RankNet,LambdaRank… Listwise:AdaRankmLambdaRank/LambdaMart,ListMLE 页面整体优化 用户注意力建模 情景(Context-aware)推荐 什么是情景: 看电影:工作日,周末 订餐:餐厅距离 网购:用户心情 母婴:孩子年龄 三种实现方式 情景推荐算法 张量分解(Tensor Factorization) 参见A Kararzoglou,2010 分解机(Factorization Machine) 矩阵(张量)分解跟线性(逻辑)回归融合的一种推广 参见Rendle,2010 Factorization Machine效果更好 深度学习算法 卷积神经网络(CNN) 循环神经网络(RNN) 深度学习在推荐上的应用 Spotity将CNN用于音乐推荐 考拉将RNN用于电商推荐 传统i2i:基于最后一个行为 RNN:基于用户整个session行为(序列数据) 评价 利用DL有希望开发出更加智能的推荐系统 RNN可用于捕捉用户实时意图,但是仅仅利用行为数据的RNN可能效果有限 (可能的改进点:1.将图像、文本、行为数据综合起来 四.总结 推荐算法需要深入理解推荐需求、业务目标、对数据的理解和处理、对用户的理解。
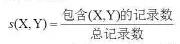
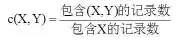

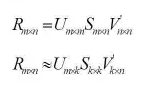
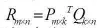
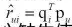
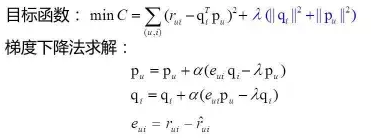





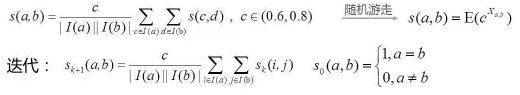


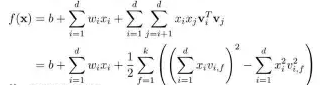










 京公网安备 11010802041100号
京公网安备 11010802041100号