作者:徐天凝_669 | 来源:互联网 | 2023-08-31 17:54
前言:
如果你想统计一本书中每个单词出现的次数,最简单的方式是写一个单线程程序遍历每一个单词,虽然简单,但比较耗时
你也可以写一个多线程程序,并发计算。效率高了很多,不过程序很难写,还要防止不同线程重复统计
当然,还可以将书拆成几份,让不同的计算机单线程运行,最后汇总。这样效率高,程序也简单。你也许更疑惑了,这TM做不到啊
别急,MapReduce就是做这个的
01
编程模型-MapReduce
MapReduce是一个分布式运算程序的编程框架
简单来说,你只要编写一个单线程程序,通过MapReduce框架就能在不同的计算机上同时执行该程序
在编写程序时,你无需考虑分布式,简单的像个孩子
现在说起MapReduce,我们都知道它是一种计算框架。实际上它在Google发表的论文里它是一种编程模型。后来开源社区根据谷歌的论文实现了一个分布式计算框架,也命名为MapReduce
那么MapReduce编程模型是什么呢?
如果把数据的处理方式抽象为Map和Reduce,所有的数据计算都能通过这两种形式实现
1)Map
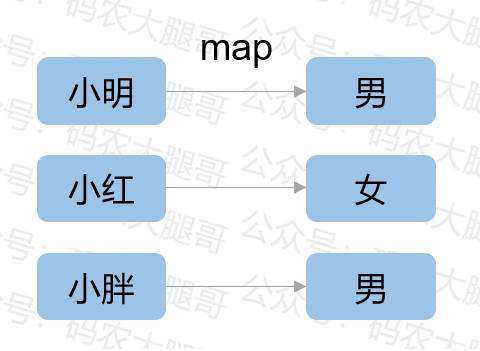
Map也叫映射,表示数据一对一的映射,也就是实现数据的转换。比如,根据人名转换成性别
2)Reduce
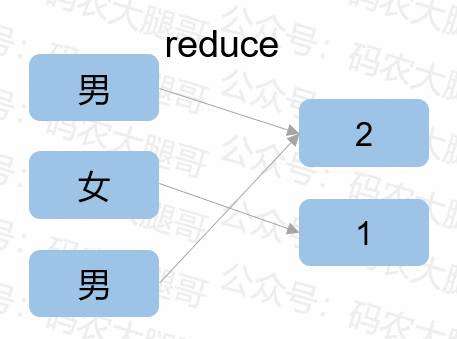
reduce作为另外一种映射方式,主要作用是聚合。比如,对性别进行聚合,得到每种性别的人数
3)map与reduce的混合使用
MapReduce认为,再复杂的数据处理流程都可以通过这两种映射方式的组合来解决
将复杂的逻辑拆解成一个个map或reduce,通过代码来完成每个小阶段的计算逻辑,就能完成复杂计算逻辑了
02
WordCount
前面我们知道了Map和Reduce两种计算思想,下面我们通过一个WordCount案例,来学习MR框架是如何实现分布式计算的
假设我们要统计一份日志中每个单词出现的次数。这个日志存储在分布式存储在两台电脑上,一台份200M,一份100M
通过如图的5个过程并行计算,即可得到最终的结果
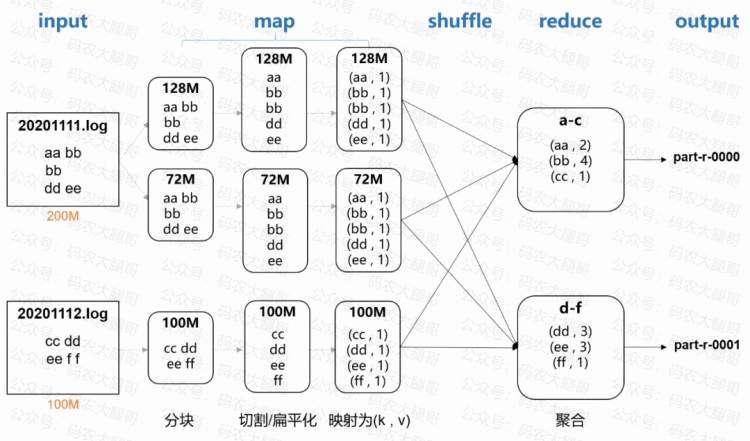
1.input
该阶段主要是读取文件。两台电脑同时读取,200M的文件存储时会存成两个Block,所以可以启动两个线程分别读取两个Block
2.map
该阶段主要是数据的转换。首先将每块数据按行读取,对于每一行数据,按指定分隔符拆开,得到一个个单词。最后将每个单词映射成(key , value)的形式
3.shuffle
shuffle有个很优雅的名字,叫 "奇迹发生之地"。至于它有什么作用,我们后面再说
4.reduce
该阶段主要作用是数据聚合。聚合后的数据就可以输出了
5.output
输出最终结果
03
MapReduce计算框架
最后,我们再来看看计算框架-MapReduce
1.优点
简单实现一些接口,就可以完成一个分布式程序。不过现在已经没人写MR程序了,有兴趣的可以去了解下集群中某一台机器挂了,计算任务会分配到别的机器,不会导致整个任务执行失败
可实现上千台服务器集群的并发计算,适合PB级以上海量数据的离线处理
2.缺点
1)不支持实时计算
MapReduce计算时间较长,可能一个任务就要跑几分钟甚至几十分钟,无法像MySql那样在毫秒内返回结果
因此,诞生了一些可以支持大数据实时计算的数据库,以后会逐步接触到。
2)不支持流式计算
MapReduce输入的数据集必须是静态的,不支持动态变化的数据集。
3)不擅长DAG计算
如果多个MR程序存在依赖关系,后一个程序的输入是前一个的输出。这种情况,不适合用MapReduce来完成
因为每一步的结果都会写入磁盘,然后再进行下一个程序,这样造成了大量磁盘IO,性能非常低下
一个MapReduce程序运行时,会启动三种实例进程
1)MrAppMaster
负责整个程序的过程调度与状态协调,在NameNode上启动
2)MapTask
负责Map阶段的数据处理过程,会在不同DataNode上启动
3)ReduceTask
负责Reduce阶段的数据处理过程,会在不同DataNode上启动
你学废了吗?






![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)


 京公网安备 11010802041100号
京公网安备 11010802041100号