碍于这学期课程的紧迫,现在需要尽快从课本上掌握一些ML算法,我本不想经过danger zone,现在看来却只能尽快进入danger zone,数学理论上的缺陷只能后面找时间弥补了。
如果你在读这篇文章,希望你不要走像我一样的道路,此举实在是出于无奈,尽量不要去做一个心急的程序员,应当分清楚哪些资源是过了学生时期就不再容易获得的。
朴素贝叶斯算法简述
不同于前面说的k-近邻算法,贝叶斯分类器是一种概率分类器,而朴素贝叶斯则是建立在两个前提假设上的:
①特征之间相互独立
②每个特征同等重要
如果要对一些对象分类,如桶里有白球和黑球,随机拿出一个球猜想拿出的是什么球。如果完全没有这个球的其它特征信息,很难判断该猜是什么球,如果通过先前的知识,如先前拿出过100个球,其中60个都是黑色的,又不知道这个球的其它特征,为了减少错误率,肯定会猜这个球是黑球。这种基于标签取各个值的概率的判别方式,就是在用先验概率做判别:
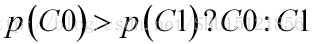
而如果知道了一些特征,如白色的球往往更粗糙(粗糙的球是白色的概率比粗糙的球是黑色的概率大),那如果摸到的是粗糙的球,很显然就要判别为白色才会错误率最小了,这种获得了特征以后对标签的判别,就是在用后验概率做判别:
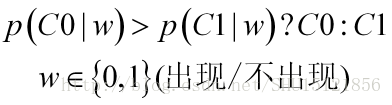
如果特征只有粗糙程度这一个,那么很好办,如果有很多特征,如大/小,有缺口/无缺口,重/轻…,这里举的特征都只有布尔型取值即0或者1,也就是在判决之前,能获得n个特征信息:
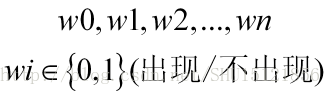
这时候这些特征的取值就可以组成一个向量了:
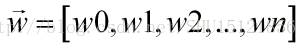
而这时要做判别的方式,也就是特征向量在这样的值下,对象属于哪一个类的概率最高,就判别为哪一类:
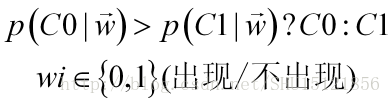
根据贝叶斯公式,对每个特征W而言,在该特征取值为w时属于类Ci的概率(后验概率)可以这样计算:
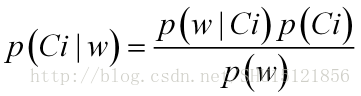
而对于多个特征信息的情况,在这个特征向量取这样的值的情况下,属于类Ci的概率(后验概率)也是一样的做法:
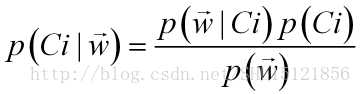
因为最后是要拿后验概率比较大小,找出最大的那个,而对于已经获得的一个特征序列而言,各个类在该特征下的后验概率与上式右边的分母——特征取该序列值的概率没有关系,所以只要去比较分子上的类条件概率和先验概率:
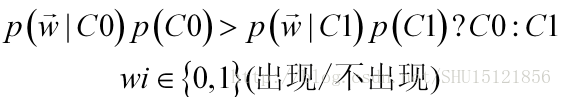
对于先验概率是比较容易求得的,而这里的类条件概率是已知类为Ci的条件下,特征向量取这个序列值的概率。
前面说了,朴素贝叶斯假设特征之间是相互独立的,因此特征的联合概率可以拆开来:
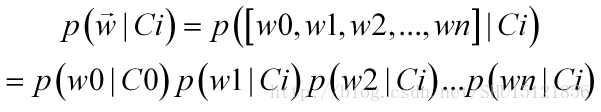
从而在朴素贝叶斯假设下,所要比较的类条件概率和类的先验概率乘积可以这样展开:
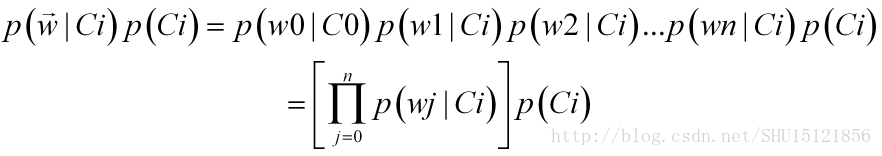
在现实的情况下,毕竟是用样本集中的频率去表征概率,上面的式子中的某个特征的类条件概率有可能算出来是0(因为样本集总是有限的),这样乘起来整个式子就是0,显然不应因为一个特征的值的出现而否决所有特征,所以在实际做的时候,会把每个特征的频数都初始化为1,这样即便后面再也没出现过,也不至于让这个频率变成0;同时显然要把每个类中各个特征出现的总频数初始化为特征的数目n,因为刚刚已经把每个特征的频数都初始化为1了。这是一件事。
另一件事是&#xff0c;即便这些数相乘起来不该得到0了&#xff0c;但是算法是在计算机上跑的&#xff0c;概率总是<1的值&#xff0c;太多很小的数相乘会造成下溢出。为了避免这件事&#xff0c;对概率取对数&#xff0c;因为对数和原来的数在相同的区域内同时增加或者减少&#xff0c;在相同的点取到极值&#xff0c;而我们要做的也仅仅是拿最后的概率去比较大小。对要比较大小的这块(类条件概率和先验概率的乘积)取对数得&#xff1a;

也就是说朴素贝叶斯算法要做的事情是&#xff1a;对每个类(标签的每种可能取值)而言&#xff0c;对每个特征在这个类的类条件概率取对数&#xff0c;然后全部加起来&#xff0c;再加上该类的先验概率的对数&#xff0c;对于所有类的这样的数&#xff0c;去比较大小&#xff0c;最大的那个所对应的类就成为朴素贝叶斯判别的那个类。
文本分类demo
问题描述
书上的例子是&#xff0c;训练集给出了一个文档集合和一个标签向量。文档集合不是矩阵&#xff0c;每一行的单词数目都不必一致。
文档集合中的每一行对应了一个文档&#xff0c;也就是说&#xff0c;这一行中有若干个单词&#xff0c;或许是网上的某个论坛下的一条评论中的一些单词。
标签向量还是对应着特征矩阵中的每一行&#xff0c;标签取值0表示那一行的言论是正当言论&#xff0c;标签取值1表示那一行的言论是不正当的。
而要做的事情是&#xff0c;对于给出的一个文档&#xff0c;里面有若干个词&#xff0c;要判别出它是正当言论还是不正当的。
①建立模块和加载数据集的函数
还是建立一个新的python模块&#xff0c;导入必要的包&#xff1a;
from numpy import *
import operator
from matplotlib import pyplot as plt
因为只是demo&#xff0c;用6个样本作为样本集。直接返回文档集合和标签(实际上这不是一个矩阵&#xff0c;每行的单词个数都不必一致)。
def loadDataSet():postingList&#61;[[&#39;my&#39;,&#39;dog&#39;,&#39;has&#39;,&#39;flea&#39;,&#39;problems&#39;,&#39;help&#39;,&#39;please&#39;],[&#39;maybe&#39;,&#39;not&#39;,&#39;take&#39;,&#39;him&#39;,&#39;to&#39;,&#39;dog&#39;,&#39;park&#39;,&#39;stupid&#39;],[&#39;my&#39;,&#39;dalmation&#39;,&#39;is&#39;,&#39;so&#39;,&#39;cute&#39;,&#39;I&#39;,&#39;love&#39;,&#39;him&#39;],[&#39;stop&#39;,&#39;posting&#39;,&#39;stupid&#39;,&#39;worthless&#39;,&#39;garbage&#39;],[&#39;mr&#39;,&#39;licks&#39;,&#39;ate&#39;,&#39;my&#39;,&#39;steak&#39;,&#39;how&#39;,&#39;to&#39;,&#39;stop&#39;,&#39;him&#39;],[&#39;quit&#39;,&#39;buying&#39;,&#39;worthless&#39;,&#39;dog&#39;,&#39;food&#39;,&#39;stupid&#39;]]classVec &#61; [0,1,0,1,0,1] return postingList,classVec

②创建词表的函数
创建词表的意义是&#xff0c;把训练集中的所有词有序地排在一个列表中&#xff0c;这样就为后面的词向量打下了基础。因为可以在后面用词向量的每个位置上用1或者0来代表词表中这个位置的词有没有在那个文档中出现了。
def createVocabList(dataSet):vocabSet&#61;set([]) for document in dataSet:vocabSet&#61;vocabSet | set(document)return list(vocabSet)

③建立词集模型的函数
建立词集模型&#xff0c;也就是去建立用0/1表示不出现/出现的词向量。设定这个函数是很有用的&#xff0c;因为在训练和使用分类器的时候都要把存了词汇的文档列表转化成和词表相关的词向量&#xff0c;才能去做概率计算。
def setOfWords2Vec(vocabList,inputSet):returnVec&#61;[0]*len(vocabList) for word in inputSet:if word in vocabList:returnVec[vocabList.index(word)]&#61;1else:print "词%s不在词表中!"%word return returnVec
如利用前面的词表&#xff0c;把样本集中的一行行文档转化为一行行词向量&#xff1a;

这也就得到了特征矩阵。
④训练分类器的函数
训练分类器总是需要输入训练集的特征矩阵和标签向量&#xff0c;在朴素贝叶斯算法中&#xff0c;训练分类器的目的是得到每个类上每个词的类条件概率(不如把同一类的类条件概率放到一个向量里)&#xff0c;即得到类条件概率p(w|c)向量&#xff0c;还要知道各个类的先验概率的值&#xff0c;因为这里是二分类问题&#xff0c;所以只需要知道一个值就行了&#xff0c;这里返回的是1号类的先验概率。
def TraPsBys(dataMat,labelVec):m&#61;len(dataMat) n&#61;len(dataMat[0]) pClass1&#61;sum(labelVec)/float(m)p0Num&#61;ones(n) p1Num&#61;ones(n) p0Denom&#61;1.0*n p1Denom&#61;1.0*n for i in range(m):if labelVec[i]&#61;&#61;1:p1Num&#43;&#61;dataMat[i]p1Denom&#43;&#61;sum(dataMat[i])else:p0Num&#43;&#61;dataMat[i]p0Denom&#43;&#61;sum(dataMat[i])p0Vect&#61;p0Num/p0Denom p1Vect&#61;p1Num/p1Denom p0Vect&#61;log(p0Vect)p1Vect&#61;log(p1Vect)return p0Vect,p1Vect,pClass1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
如传入刚才的特征矩阵和标签向量&#xff0c;这里得到的类条件概率向量是取过对数的了。而先验概率还没有取对数&#xff0c;一方面是方便我们观察一下先验概率的取值&#xff1b;另一方面&#xff0c;要根据这个先验概率去计算另一类的先验概率&#xff0c;这样暂时不取对数还是方便一些。

属于1号类的先验概率&#xff1a;

⑤做分类用的函数
这个函数能够对输入的词向量&#xff0c;用训练好的参数(类条件概率向量和先验概率)&#xff0c;给出预测的结果值。
具体的做法就是&#xff0c;对于这两个类(1号和0号类)&#xff0c;分别把词向量表示的出现的各个特征取对数后的值全加起来&#xff0c;再加上这一类的先验概率取对数后的值。
对于这两个类都这样做&#xff0c;最后比较大小&#xff0c;哪个大就输出哪个类的标号即可。
def CsfPsBys(vec2Classify,p0Vec,p1Vec,pClass1):p1&#61;sum(vec2Classify*p1Vec)&#43;log(pClass1)p0&#61;sum(vec2Classify*p0Vec)&#43;log(1.0-pClass1)if p1>p0:return 1else:return 0
比如建立一个文档来测试一下&#xff1a;

预测为1&#xff0c;即预测为不正当言论。
⑥测试用的函数
一个封装好的便利函数&#xff0c;可以用来理解整个分类器的使用流程。
def TstPsBys():postingList,classVec&#61;loadDataSet() vocabList&#61;createVocabList(postingList) trainMat&#61;[] for postInDoc in postingList:trainMat.append(setOfWords2Vec(vocabList,postInDoc))p0V,p1V,pC1&#61;TraPsBys(trainMat,classVec)testEntry&#61;[&#39;love&#39;,&#39;my&#39;,&#39;dalmation&#39;] thisDoc&#61;array(setOfWords2Vec(vocabList,testEntry))print testEntry,"分类为:",CsfPsBys(thisDoc,p0V,p1V,pC1)testEntry&#61;[&#39;stupid&#39;,&#39;garbage&#39;]thisDoc&#61;array(setOfWords2Vec(vocabList,testEntry))print testEntry,"分类为:",CsfPsBys(thisDoc,p0V,p1V,pC1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26

⑦建立词袋模型的函数
和建立词集模型的函数功能上是类似的。因为朴素贝叶斯分类器有两种实现方式&#xff0c;一种是基于伯努利模型实现&#xff0c;一种是基于多项式模型实现。前者不考虑词在文档中出现的次数&#xff0c;将没歌词的出现与否作为一个特征&#xff0c;称为词集模型&#xff1b;后者需要考虑词在文档中出现的次数&#xff0c;这也就包含了更多的信息&#xff0c;称为词袋模型。
def bagOfWords2Vec(vocabList,inputSet):returnVec&#61;[0]*len(vocabList) for word in inputSet:if word in vocabList:returnVec[vocabList.index(word)]&#43;&#61;1else:print "词%s不在词表中!"%word return returnVec






 京公网安备 11010802041100号
京公网安备 11010802041100号