论文地址:paper:https://arxiv.org/ftp/arxiv/papers/2001/2001.05272.pdf
github地址:github:https://github.com/AidenHuen/FGN-NER
摘要作为象形文字,汉字含有潜在的字形信息。
这一点经常被忽视。在本文中,我们提出了FGN,即融合字形网络用于中文NER。除了用一个新的CNN对字形信息进行编码外,该方法还可以提取字形信息。
融合字形网络,该方法可以通过融合机制提取字符分布式表示和字形表示之间的交互信息。
FGN的主要创新点包括 (1)提出了一种新型的CNN结构,即CGS-CNN,以获取字形信息和相邻图之间的交互信息。(2)我们提供了一种带有滑动窗口的方法 和注意机制来融合每个字符的BERT表示和字形表示。这种方法可以捕获潜在的交互式 语境和字形之间的潜在交互知识。我们在四个NER数据集上进行了实验。实验表明,以LSTM-CRF为标记的FGN在中文NER中取得了新的
在中文NER中取得了最先进的性能。此外,我们还进行了更多的实验,以研究各方面的影响。
进行了更多的实验来研究FGN中各种组件和设置的影响。
命名实体识别(NER)通常被视为序列标记问题,并通过统计方法或神经网络解决。
命名实体识别(NER)一般被视为序列标记问题,并通过统计方法或神经网络来解决。在中文命名实体识别领域,研究人员一般采用基于字符的标记策略来标记命名实体[1, 2]。
[1]Yanan, L., Yue, Z., Dong-Hong, J.: Multi-prototype Chinese character embedding. In: Conference on Language Resources and Evaluation, pp. 855-85 9(2016).
[2]Yuxian, M., Wei, W., Fei, W., et al.: Glyce:Glyph-vectors for Chinese Character Representations. In: Advances in Neural Information Processing Systems, pp. 2742-2753 (2019).
一些研究[3, 4]
[3]Haibo, L., Masato, H., Qi, L., Heng, J.: Comparison of the impact of word segmentation on name tagging for Chinese and Japanese. In: International Conference on Language Resources and Evaluation, pp. 2532–2536 (2014).
[4]Zhangxun, L., Conghui, Z., Tiejun, Z.: Chinese named entity recognition with a sequence labeling approach. based on characters, or based on words?. Advanced Intelligent Computing Theories and Applications, 634–640 (2010).
明确比较了基于字符的方法和基于词的
的方法进行比较,证实了基于字符的方法避免了词的分割阶段的错误,性能更好。
当使用基于字符的方法进行NER时, 字符级知识表示的影响可能会极大地影响中文NER模型的性能。
目前,分布式表示学习已经成为主流的汉字表示方法。
特别是在BERT[5]的提出之后,它提高了几乎所有NLP领域的
几乎所有NLP领域的基线。然而,这些方法忽略了单词或汉字内部的信息,如中文字形。已经有一些研究,关注于单词或字符的内部成分。在英语领域,研究人员[6]使用
卷积神经网络(CNN)对单词的拼写进行编码,用于序列
标签的任务。这种方法不适合于中文NER,因为中文不是字母语言,而是象形文字语言。汉字可以被进一步分割成 转换成偏旁部首。例如,"抓 "字是由 "扌"(手)和 "爪 "组成的。
"爪"(爪子)。关于基于部首的字符嵌入的研究[7]证实了这些部件在中文中的有效性。
[7]Yaming, S., Lei, L., Duyu, T., et al.: Radical-Enhanced Chinese Character Embedding. In: International Conference on Neural Information Processing, pp. 279-286 (2014).
此外,研究人员将注意力转向了将汉字视为字形的图形编码。一些研究人员[8, 9, 25]尝试运行CNN来捕捉字形信息。然而,这些工作只是获得了可忽略的改进。在Meng等人[2]避免了以前工作的缺点,提出了一个基于字形的BERT模型,称为Glyce,它在各种NLP 包括NER在内的各种NLP任务中取得了SOTA性能。他们采用Tianzige-CNN对每个汉字的七个历史和现代脚本进行编码。
田字格是中国传统的书法形式,它符合汉字内部的偏旁部首分布。然后 Transformer[10]被用作Glyce中的序列编码器。此外,Sehanobish和 Song[11]
[11]Arijit, S., Chan, S.. Using Chinese Glyphs for Named Entity Recognition. arXiv preprint arXiv:1909.09922, Computer Science (2019).
提出了一个基于字形的NER模型,称为GlyNN,它只对每个字符的黑体进行编码,以提供字形的
黑体字体来提供字形信息,并使用BiLSTM-CRF作为序列标记器。
此外,在GlyNN中还仔细考虑了非汉字的表示。与Glyce相比,带有BERT的GlyNN在多个NER数据中取得了相当的性能,使用了较少的字形资源和小的CNN。它证明了历史文字在某种程度上对NER是没有意义的。我们认为这是因为现代汉语的实体类型和数量远比古代的丰富和复杂。
上述工作只是对字形和分布式表示进行独立编码。他们忽略了字形和上下文之间的交互式知识,这一点在多模态深度学习领域已经得到了研究。
在多模态深度学习领域中被研究[12, 13, 14]。此外,由于汉字的含义并不完整,我们怀疑对每个字的编码并不是一个合适的方法。事实上,相邻字符的字形之间的交互知识可能有利于NER任务的完成。例如,像 "杨树"、"柏树 "和 "松树 "这样的树名中的字符有相同的偏旁部首 "木",但算法名称 "决策树 "的字符却没有这样的模式。汉语中还有更多类似的模式,可以通过相邻字形之间的交互知识来区分。
因此,我们提出了FGN,即用于中文NER的融合字形网络。FGN的主要创新包括:(1) 为字形编码提供了一种新的CNN结构,称为CGS-CNN,即Character 图形序列CNN,用于字形编码。CGS-CNN可以捕捉相邻字形之间的潜在邻近字符的字形之间的信息。 邻近字符的字形之间的信息。(2) 我们提供了一种融合方法,用同步外的滑动窗口和 Slice-Attention来捕获字形表示和字符表示之间的交互知识。FGN被发现可以提高NER的性能,它在四个NER数据集上的表现优于其他SOTA
模型在四个NER数据集上的表现(第4.2节)。此外,我们验证并讨论了FGN中各种建议设置的影响(第4.3节)。

我们的工作与用于 NER 的神经网络有关。Ronan等人[15]提出了CNN-CRF模型,该模型获得了与各种最佳统计NER模型竞争的性能。
LSTM-CRF[16]是目前后续NER的主流组件。模型中的主流组件。为了加强词级表示,Ma和Hovy[6]提出了 LSTM-CNN-CRF结构用于序列标注,
[6]Xuezhe, M., and Eduard, H.: End-to-end Sequence Labeling via Bi-directional LSTMCNNs-CRF. In: Proceedings of the Annual Meeting of the Association for Computational Linguistics, pp. 1064-1074 (2016).
[16]Huang Z, Xu W, Yu K.: Bidirectional LSTM-CRF models for sequence tagging. arXiv preprint arXiv: 1508.01991, Computer Science (2015).
该结构采用CNN来编码 该结构采用CNN编码每个英语单词的拼写,以增强语义。此外,一个核心参考表征学习方法[17],该方法结合了 LSTM-CNN-CRF进行英语NER。在中文领域,Dong等人[18]将每个字符中的部首组织成序列,并使用LSTM网络捕捉部首信息用于中文NER。Zhang等人[19]提出了一种新的NER方法,称为LatticeLSTM,它巧妙地编码了汉字以及所有与词库相匹配的潜在词汇。
[19]Yue, Z., Jie, Y.: Chinese NER Using Lattice LSTM. In: Proceedings of the Annual Meeting of the Association for Computational Linguistics, pp.1554-1564 (2018) 这也是我们后来要看的论文
匹配的词库。在Lattice-LSTM的基础上,提出了单词-字符LSTM(WC-LSTM)[20]。
[20]Wei, L., Tongge, X., Qinghua, X.: An Encoding Strategy Based Word-Character LSTM for Chinese NER, In: Proceedings of Conference of the North American Chapter of the Association for Computational Linguistics, pp. 2379-2389 (2019)
的基础上,提出了将词的信息加入到一个词的开头和结尾的字符中,以减轻词的影响。词的开头和结尾字符,以减轻单词分割错误的影响。
我们的工作也与一些多模态的工作有关。目前,来自视觉的知识已经在NLP中被广泛使用。我们根据视觉知识的来源将这些相关研究简单地分为两类:字形表示学习和多模态深度学习。如前所述,前者是稀缺的。我们将输入的句子转化为三维编码的图形序列。据我们所知,我们是第一个通过三维卷积[21]在句子层面上对字符字形进行编码的人,而三维卷积主要是用来编码视频信息的。后者是当前各种NLP领域的热点。Zhang等人[12]提出了一种用于推文NER的自适应共同关注网络,该网络可以自适应地平衡推文中图像表示和文本表示的融合比例。参考BERT,提出了一个多模态BERT[13],用于面向目标的情感分类。在这个模型中使用了多个自我注意层[9],以便在连接BERT和视觉表示后捕捉互动信息。此外,Mai等人[14]提出了一个具有局部和全局视角的融合网络,用于多模态情感计算。他们提供了一个滑动窗口来切分多模态向量,并通过外积函数融合每个切分对。他们提供了一个滑动窗口,并通过外积函数来融合每个片断对。我们的方法借鉴了上述的多模态融合方法的思路。与他们在句子层面的融合不同,我们将重点放在字符层面的融合上。
在本节中,我们将详细介绍FGN。如图1所示,FGN可以分为三个阶段:表示阶段、融合阶段和标记阶段。我们遵循基于字符的序列标签的策略进行中文NER。
这里我们讨论了汉字的表示学习,包括来自BERT的字符表示和CGS-CNN的字形表示。包括来自BERT的汉字表示和来自CGS-CNN的字形表示。这些代表的细节表示方法如下。
BERT是一个多层Transformer编码器,它为单词或字符提供分布式表示。我们使用预先训练好的中文BERT来编码句子中的每个句子中的字符。与一般的微调策略不同,我们首先在训练集上用CRF层作为标记器对BERT进行微调(HOW TO)。然后冻结BERT的参数并将其转移到FGN中。4.3节中的实验显示了这一策略的有效性。

CGS-CNN 图2描述了CGS-CNN的结构。我们只选择简单的中文字体来生成字形向量,因为过去的工作[11]表明,只使用一种中文字体就能达到与七种字体相媲美的性能。CGS-CNN的输入格式是字符图谱序列。我们首先将句子转换为图形序列,其中的字符被替换成50×50的灰度图形。然后,我们提供两个3×3×3的三维卷积层来编码图形序列,并以8个通道输出每个50×50的图形。三维卷积可以从空间和时间两个维度上提取特征,这意味着每个字形向量可以从邻近的图形中获得额外的字形信息。使用填充对图形序列的维度进行填充,我们可以在通过三维卷积后保持图形序列的长度不变,这对基于字符的标签来说是必要的。然后,三维卷积的输出可以通过几组二维卷积和二维最大集合,将每个图形压缩成2×2的田字格结构,有 64个通道。为了过滤噪音和空白像素,我们将2×2结构压平,并采用1D最大池化法来处理。
采用1D最大集合法来提取每个字符的字形向量。字形向量的大小向量的大小被设定为64,这比Tianzige-CNN输出的大小(1024维)
与Glyce不同的是,它将图像分类任务设定为学习字形表示。我们在领域数据集中训练整个NER模型时学习CGS-CNN的参数
我们提供一个滑动窗口来滑动BERT和字形表示。
在滑动窗口中,每个切片对都是通过外积来计算的,以捕捉局部的交互特征。然后用切片注意来平衡每个切片对的重要性,并将它们结合起来,输出一个融合的表征。
Out-of-sync Sliding Window.
不同步的滑动窗口
如上所述,滑动窗口已被应用于多模态情感计算[14]。使用滑动窗口的原因是,直接用外积融合向量将指数级地扩大向量大小。这增加了后续网络的空间和时间复杂性。然而,这种方法要求多模态表示具有相同的大小,这不适合同时滑动BERT矢量和字形矢量。因为BERT的字符表示比字形表示有更丰富的语义信息,需要更大的矢量尺寸。这里我们提供了一个同步外的滑动窗口,可以满足不同的矢量大小,同时保持相同的片数。
假设我们有一个汉字,其字符向量定义为𝑐_𝑣 ∈ℝ
𝑑𝑐
和字形向量定义为 𝑔_𝑣 ∈ ℝ𝑑𝑔
这里𝑑𝑐和 𝑑𝑔
代表两个向量的大小。为了使这两个向量在通过滑动窗口后保持相同数量的切片,滑动窗口的设置需要满足以下限制。

其中𝑛是一个正整数,代表两个矢量的片数;𝑘𝑐和 𝑠𝑐分别代表字符向量的窗口大小和跨度。𝑘𝑔和𝑠𝑔分别代表字形向量的窗口大小和跨度。我们使用的策略是满足 这个条件是限制滑动窗口的超参数,使𝑑𝑐, 𝑘𝑐和𝑠𝑐分别是 𝑑g,kg,sg 的整数倍
为了得到切片对,我们首先计算每一步滑动窗口的左边界指数:

其中 𝑝(𝑖)𝑐和 𝑝(𝑖)𝑔分别代表滑动窗口的边界指数。字符和字形向量在第𝑖步的边界指数。然后,我们可以通过以下公式获得每个片断 :

其中𝑐_𝑠(𝑖)和𝑔_𝑠(𝑖)分别代表两个向量中的第𝑖片。𝑐_𝑣(𝑝(𝑖)𝑐 +1)代表在(𝑝(𝑖)𝑐+1)的第1个维度的值。为了从局部角度融合两个切片,采用外积法来生成一个交互式张量,如公式所示

还有一些公式推导就不写了 不太重要
outer product为字符级的表示提供了交互式信息,同时也产生了更多的噪音,因为许多特征是不相关的。参照注意力机制,我们提出了 "切片-注意力",它可以自适应地量化每个切片对的重要性,并将它们结合起来以表示一个字符。切片对的重要性可以量化为:

其中,𝑎𝑖代表第𝑖个切片对的重要性值,𝜎为Sigmoid函数。
这里的Sigmoid函数可以将向量的值范围限制在0和1之间,这样可以保证后续的点乘计算有意义。
在标记之前,我们将每个向量在字符级别上连接起来。句子的最终表示可以定义为𝑥={𝑥1, 𝑥2 ... , 𝑥𝜏},其中𝜏代表句子的长度。然后,采用BiLSTM作为序列编码器,采用CRF作为解码器
命名实体标签。
BiLSTM LSTM(长短时记忆)单元包含三个专门设计的 门来控制沿序列的信息传输。为了对𝑥的序列信息进行编码,我们使用一个前向LSTM网络来获得前向隐藏状态,并使用一个后向LSTM网络来获得后向隐藏状态。后向LSTM网络来获得后向隐藏状态。然后,这两个隐藏状态合并为

后面也就是介绍bilstm 就不多写了
在第4.1节和第4.2节中,我们介绍了我们使用的数据集的情况和后续实验的一些设置。主要的实验结果可以在第4.2节中找到,在这里我们设定了我们的模型和各种SOTA模型的比较。我们提出的FGN 我们提出的FGN在每个数据集中测试了10次,以计算平均精度(P)。召回率(R),F1-socre(F1)。在第4.3节中,我们测试了FGN中的一些主要组件,每个组件也测试了10次。每个组件也被测试了10次,以计算平均指标。
数据集
我们选择了四个广泛使用的NER数据集进行实验,包括OntoNotes 4 [22], MSRA [23], Weibo [24] 和Resume [19]。所有这些数据集都是用BMES标签方案来注释的。其中,OntoNotes 4和MSRA属于新闻领域。领域;微博的注释来自中国的社交媒体--新浪微博。这三个 数据集只包含传统的名称实体,如地点、个人姓名和组织。简历是由个人简历中的8种命名实体注释而成的。
超参数设置
我们对字符表示和字形表示都使用了丢弃机制。CGS-CNN的dropout被设定为0.2,激进的自我注意的dropout被设定为0.5。LSTM的隐藏大小被设置为764,LSTM的丢弃率被设置为0.5。我们使用了Chinese BERT (),它是由谷歌预训练的 谷歌2 . 按照默认配置,每个字符的输出向量大小被设置为 为764。我们使用的字符图谱是从《新华字典》3中收集的,数量为8630个。数量为8630个。我们将这些图形转换为50×50的灰度图。正如在第3.2节中提到的 3.2节中提到,字符向量的窗口大小和滑动窗口的步长分别是字形向量的整数倍。因此,我们将前者的大小和跨度设置为96和8,而后者的大小和跨度设置为 前者为96和8,后者为12和1,根据经验研究。亚当是 作为优化器用于BERT微调和NER模型训练。学习 微调条件和训练条件下的学习率是不同的。前者是 设置为0.00001,而后者设置为0.002。
表1和表2显示了FGN的一些详细统计数据,与其他SOTA模型在四个NER数据集上进行了比较。与其他SOTA模型在四个NER数据集上的比较。这里,FGN代表所提出的字形 模型;Lattice LSTM[19]和WC-LSTM[20]是没有BERT的SOTA模型,结合了单词嵌入和字符嵌入。BERT-LMCRF代表BERT模型,BiLSTM-CRF作为NER标记器。
Glyce [2] 是前面提到的基于SOTA BERT的字形网络。GlyNN[11]是另一个基于SOTA BERT的字形网络。特别是,我们选择GlyNN的平均F1进行比较,因为我们也采用平均F1作为衡量标准。对于其他基线,我们选择他们在试验中显示的结果,因为他们没有说明他们是否使用平均F1。可以看出,FGN在所有四个数据集中的表现都优于其他SOTA模型。
与BERT-LMCRF相比 与BERT-LMCRF相比,FGN的F1获得了明显的提升,分别为3.13%、2.88%、1.01%和 0.84%,在微博、OntoNote 4、MSRA和Resume上分别获得明显的提升。
此外,FGN的表现超过了一些基于SOTA字形的NER模型,如Glyce和GlyNN。然而,FGN 在Resume和MSRA数据集上没有取得明显的改善,因为BERTLMCRF已经能够识别这两个数据集上的大部分实体。
事实上,在数据集微博和OntoNote4对于NER来说更加困难,因为实体的类型和实体的提及更加多样化。提及的实体更加多样化。
例如,微博和OntoNote4中的一些有趣的和特殊的实体 词,如 "铼德"(公司名称)和 "啊滋"(公司名称),这些词在微博和OntoNote4中都很有趣。(公司名称)和 "啊滋猫"(奶茶店 店),只有FGN能够成功识别。我们猜测其原因是 铼 "字含有表示 "金属 "的偏旁 "钅",而 "滋 "字 含有表示 "水 "的基点 "氵"。这些基点与他们公司的产品有关。
事实上,这种现象在各种中国实体中很常见包括公司、人名和地点,这些都深受中国人命名文化的影响。
将上下文信息与上述 字形信息相结合,FGN可以捕捉到额外的特征来识别一些特殊的 在某些情况下,FGN可以捕捉到额外的特征来识别一些特殊的命名实体。

这里我们讨论一下FGN中各种设置和组件的影响。我们研究的组件包括。CNN结构、命名实体标记器和融合方法。
微博数据集被用于这些说明。
Effect of CNN structure.
如表3所示,我们研究了各种CNN结构的性能,同时保持FGN的其他设置不变。
各种CNN结构的性能,同时保持FGN的其他设置不变。
在这个表中。"2d "代表没有三维卷积层的CGS-CNN。"avg "代表1D CGS-CNN中的最大池化被1D平均池化所取代。
2D CNN表示 表示只有二维卷积层和二维池化层的CNN结构。Tianzige-CNN是由Glyce提出的。
可以看出,普通的二维CNN结构得到的结果较差,因为它完全忽略了Tianzige结构和邻近字形的信息。
与Tianzige-CNN相比,使用CGS-CNN能使F1提高0.66%,因为 CGS-CNN可以捕捉字形之间的交互信息。
与二维卷积相比,使用带有三维卷积的FGN在F1中提高了 1.14%,这证实了短语或单词的相邻字形信息的好处。或词的相邻字形信息的好处。
除此之外,在捕捉天字形结构的特征时,最大池化比平均池化效果更好。
如前所述,这里的最大集合可能会过滤一些字符图中的空白像素和噪音。

我们选择了一些广泛使用的序列标记器来 在FGN中取代BiLSTM-CRF进行讨论。
表4显示了各种所选标记器的性能。
可以看出,基于LSTM和CRF的方法优于 Transformer[9]编码器的NER任务。事实上,大多数的SOTA NER方法[11, 19, 20]喜欢使用BiLSTM而不是Transformer作为他们的序列编码器。
与只有CRF相比,LSTM-CRF在F1中引入了0.43%的提升。
此外,双向LSTM在F1中引入了0.56%的进一步提升。
在这个实验中,LSTMCRF在NER任务中的表现比Transformer更好。

我们研究了在融合阶段不同设置的性能,如表5所示。在该表中,"concat "表示在没有任何融合的情况下,将字形和BERT表示法连接起来。
"no freeze "代表带有可训练的BERT的FGN。
"avg pool "和 "max pool "代表FGN中的Slice-Attention分别被pooling或max pooling取代。
此外,我们将窗口大小重置为 (196, 16), (48, 4),滑动窗口的步长为(24, 2)。和字形表示,以测试FGN。
与直接连接字形和BERT的向量相比,FGN在F1中引入了0.82%的提升,这证实了我们融合策略的有效性。
在不同阶段采用微调和冻结BERT策略的FGN优于采用可训练BERT的FGN。
我们认为这是因为微调BERT在更新BERT参数时只需要最小梯度值。
但LSTM-CRF 需要设置一个较大的学习速率来调整具有适当梯度值的初始化参数。
在FGN中,使用Slice-Attention优于使用平均池或最大池,因为Slice-Attention可以自适应地平衡每个片断的信息,而池层只是静态地过滤信息。
否则,滑动窗口的设置 4.1节中设置的滑动窗口略胜于其他超参数设置的滑动窗口。

在本文中,我们提出了用于中文NER的FGN。在FGN中,我们采用了一种叫做CGS-CNN的新型CNN结构来捕捉字形信息和相邻图形之间的交互信息。
然后,采用同步外滑动窗口和Slice-Attention的融合方法。窗口和Slice-Attention的融合方法来融合BERT和CGS-CNN的输出表示。
BERT和CGS-CNN的输出表示,这可能为NER任务提供额外的互动信息。
在四个NER数据集上进行的实验表明,采用LSTM-CRF的FGN 作为标记器,在四个数据集上获得了SOTA性能。
此外,还讨论了FGN的各种设置和组件的影响。在消减研究中讨论了FGN中各种设置和组件的影响。






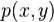

 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有