Butterfly detection and classification based on integrated YOLO algorithm
论文地址:xxx.itp.ac.cn//abs/2001.00361
Insects are abundant species on the earth, and the task of identification and identification of insects is complex and arduous. How to apply artificial intelligence technology and digital image processing methods to automatic identification of insect species is a hot issue in current research. In this paper, the problem of automatic detection and classification recognition of butterfly photographs is studied, and a method of bio-labeling suitable for butterfly classification is proposed. On the basis of YOLO algorithm[1], by synthesizing the results of YOLO models with different training mechanisms, a butterfly automatic detection and classification recognition algorithm based on YOLO algorithm is proposed. It greatly improves the generalization ability of Yolo algorithm and makes it have better ability to solve small sample problems. The experimental results show that the proposed annotation method and integrated YOLO algorithm have high accuracy and recognition rate in butterfly automatic detection and recognition.
昆虫是地球上丰富的物种,昆虫的鉴定和鉴定任务复杂而艰巨。如何将人工智能技术和数字图像处理方法应用于昆虫种类的自动识别是当前研究的热点问题。研究了蝴蝶照片的自动检测和分类识别问题,提出了一种适合蝴蝶分类的生物标记方法。在YOLO算法的基础上,综合不同训练机制的YOLO模型的结果,提出了一种基于YOLO算法的蝴蝶自动检测与分类识别算法。它大大提高了Yolo算法的泛化能力,使其具有较好的解决小样本问题的能力。实验结果表明,本文提出的标注方法和综合YOLO算法在蝴蝶的自动检测和识别中具有较高的准确率和识别率。
蝴蝶作为昆虫重要的环境指标之一,种类复杂多样。蝴蝶种类的鉴定直接关系到人类和动物食用的农作物。目前,广泛使用的可靠蝴蝶识别方法效果不佳。人工识别蝴蝶种类不仅工作量大,而且需要长期的经验和知识积累。如何实现昆虫物种的自动识别是计算机视觉领域的研究热点之一。
昆虫物种的自动识别需要对数字图像进行识别和分类,图像分类的效果与纹理特征提取的质量密切相关。2004年,Gaston等人[2]介绍了人工智能技术和数字图像处理方法在数字图像识别中的应用。此后,许多专家学者在这方面做了大量的工作[3,4]。近年来,随着机器学习的发展,研究人员提出了许多相关的蝴蝶检测应用算法。2012年,Wang等人[5]使用基于内容的图像检索(CBIR)提取蝴蝶的图像特征,如颜色、形状。Bohan Liang等人。对不同的纹理特征、特征权重和相似度匹配算法进行了比较,并提出了相应的分类方法。2014年,Kaya Y等人[6]应用局部二值模式(LBP)[7]和灰度共生矩阵(GLCM)[8]提取蝴蝶图像的纹理特征,然后利用单隐层神经网络进行分类,提出了一种基于极值学习机法则的蝴蝶物种自动识别方法。同年,Kang S H等人[9]提出了一种基于分支长度相似性(BLS)熵分布的有效识别方案,该方案利用从不同角度观察到的蝴蝶图像作为神经网络的训练数据。2015年,李帆[10]根据蝴蝶的形态特征和纹理分布,利用图像块的灰度共生矩阵(GLCM)特征和K近邻分类算法,提出了相应的特征提取和分类决策方法。2016年,Zhou A M等人[11]证明了该深度学习模型的可行性,并在蝴蝶标本的自动识别中具有较强的泛化能力。
2018年,谢娟英等[12]采用了基于快速RCNN的蝴蝶检测和物种识别方法[13],并在自然生态环境中利用蝴蝶照片扩展了数据集。该算法对自然生态环境中的蝴蝶照片具有较高的定位精度和识别精度。传统的蝴蝶识别算法存在以下问题:
1.在自然生态照片中,蝴蝶往往以小目标的形式出现(蝴蝶图像的面积太小),传统的蝴蝶识别算法往往无能为力。
2.培训所需的数据量巨大,但找不到高质量的带注释的公共数据集。
3.一些稀有蝴蝶在自然状态下的照片太少,无法直接用作训练集。
Joe Redmon[1]提出的YOLO模型是目标检测领域的一种著名的端到端学习模型。与RCNN[13]序列的两步模型相比,YOLO模型执行速度快,避免了背景误差,但定位精度差,某些分类的单模型误报率高。
为了提高蝴蝶识别的效率,本文将充分利用中国数据挖掘大赛和百度百科提供的数据,建立包含大量蝴蝶生态照片的蝴蝶数据集,在自然环境中利用生态照片进行模型训练,并在YOLO V3算法的基础上,提出了一种用于蝴蝶生态照片定位识别的集成算法。本文的主要结构如下:
1.数据集、数据注释和数据预处理。利用文献[14]提供的蝴蝶生态照片和百度等网络照片数据库中的图片,通过自标记,建立了一个包含2342个精确标记自然环境的蝴蝶数据集。通过实验筛选出适合于蝴蝶标记的方法,并对标记方法进行了总结。
2.集成的YOLO算法。该算法继承了YOLO算法的识别速度,优化了YOLO算法,提高了YOLO算法对细目标的识别能力,提高了YOLO算法对小样本的学习能力和泛化能力。为基于atlas的后续目标检测提供了一个良好的思路。
3.实验和分析。介绍并分析了YOLO算法在不同标注和处理模式下的性能,以及在蝴蝶测试集上集成YOLO算法的性能。
4.总结与展望。
本文使用的蝴蝶数据集都是蝴蝶在自然生态环境中的照片,以下简称生态照片。一部分来自文献[14]提供的数据集,另一部分来自百度等搜索引擎和图片库中的图片,包括蝴蝶94种11属。图1展示了蝴蝶生态学的一些样本。

文献[14]共拍摄照片5695张,其中蝴蝶照片有标本照片和生态照片两种。文献[12]指出,由于标本的拍摄角度和背景环境与生态照片有很大不同,在训练集中只使用生态照片的训练效果明显优于同时使用标本和生态照片进行蝴蝶检测和分类的训练效果,本研究的目的在于对自然环境中的蝴蝶进行定位,确定蝴蝶种类,因此本文仅选取了1048张自然生态环境中的蝴蝶照片。
数据集中每张照片包含的蝴蝶样本大多只有一个,最大数量不超过20个。每种蝴蝶至少由四个具有典型重尾分布的样本组成。
测试集基于文献[14]提供的标准测试集,包含678张生态照片,其余为训练集。
因为生态照片中蝴蝶的姿态比较复杂,甚至有很多蝴蝶重叠在一起,文献[14]提供的数据集混乱,没有统一的标注标准。我们制定了一套统一的标注标准,并根据该标准手工标注了所有照片中所有蝴蝶样本的位置和种类。
在文献[14]提供的数据集中,蝴蝶所在区域的标注有两种方式:一是以蝴蝶的触角和腿为界,如图2(a)所示;二是以蝴蝶的躯干和翅膀为界,如图2(b)所示。我们使用两种注释方法来统一数据集。

因为有些蝴蝶有社会属性,许多蝴蝶在照片中经常重叠。文献[14]中提供的数据集使用将重叠区域中的多只蝴蝶标记为单个样本的方法,如图3(a)所示。我们还开发了一个用于标记这种情况的标准:重叠区域中的每个蝴蝶都被独立地标记,并且被遮挡的部分被忽略,如图3(b)所示。该方法不仅增加了训练样本的数量,而且提高了模型对复杂场景的识别效果。

基于深度学习的目标检测算法往往需要大量的数据作为训练集。本文采用旋转、镜像、模糊、对比度升降等9种变换方法对训练集进行扩展,并结合不同的预处理方法及其参数(如旋转角度、曝光等),得到最优的预处理方法。结果将在第4部分中显示。
通过上述过程,蝴蝶在自然生态环境中的自动检测和分类问题已经转化为一个多目标的检测和分类问题。与常见的目标检测问题不同,蝴蝶自动检测和分类问题有三个难点:1)分类多(94个分类);2)样本分布不均匀。一些珍稀品种的蝴蝶样品明显少于其他种类的蝴蝶;3)必须将不同的小类(不同种类的蝴蝶)归入同一大类(蝴蝶),即需要进行细粒度分类。因此,本文对蝴蝶的自动检测和分类的研究就更加困难。
Joe-Redmon提出的YOLO模型[1]是目标检测领域一种著名的端到端学习模型。其特点是与RCNN[8]级数的两步模型相比,YOLO模型的执行速度快得多,在细粒度检测中表现良好。我们的任务选择了YOLO的第三代车型YOLO v3。
YOLO V3模型的结构如图4所示。为了检测自然照片中不同大小(面积比例不同)的蝴蝶,YOLO V3在特征提取网络(darknet-53)后,利用多尺度特征图对不同大小的目标进行检测。
YOLO V3输出三个不同比例的特征图。经过79层卷积网络后,通过三层特征提取网络得到第一尺度的检测结果。这里用于检测的特征图是输入图像的32倍下采样。由于降采样率高,特征地图的感知场相对较大,适合于检测图像中面积较大的目标。
上采样卷积是从79层后面完成的。第81层特征图与第61层特征图相结合。经过三层特征提取网络,得到了第九十一层的细粒度特征图,即相对于输入图像的16倍下采样特征图。它具有中等尺度的感知视野,适合于检测图像中面积比例中等的目标。
最后,再次对91层特征图进行采样,并与36层特征图进行连接。经过三层特征提取网络,得到相对于输入图像低8倍采样的特征图。它具有最小的感知场,适合于检测图像中面积比例较小的目标。
每个输出包含3d2分割5+N维向量,其中符号D表示该比例下输出特征图的边长度。数字3以每个网格单元中的先验框数为中心,符号N是分类数。每个向量的前四个维表示预测框的位置,第五个维表示候选框中目标的概率,5+i维表示候选框中目标属于i类的概率。
YOLO使用均方和误差作为损失函数。它由四部分组成:预测盒误差(ERRcenter)、预测边界宽度和高度误差(ERRwh)、分类误差(ERRclass)和预测置信误差(ERRconf)。

这里,n是网格单元中预测帧的数目,(x,y)是预测帧的中心坐标,w和h分别是预测帧的宽度和高度。由于大预测盒引起的误差明显大于小预测盒引起的误差,YOLO采用了预测宽高平方根的方法,而不是直接预测宽高。如果第一个网格单元中的第j个预测框负责对象,则我们得到ιobj ij=1,反之,ιobj ij=0。
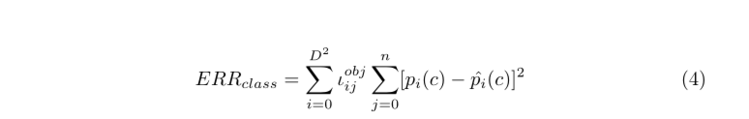
YOLO认为每个网格单元只包含一个分类对象。如果c是正确的类别,那么ˆpi(c)=1,反之,ˆpi(c)=0。
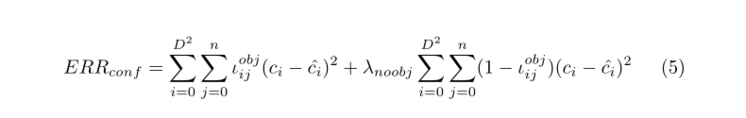
其中ci表示预测框中包含的对象的置信度。如果实际边界框中有对象,则ˆci是实际边界框和预测框的IoU值。相反,有ˆCi=0。在损失函数的不同加权部分引入参数λ,提高了模型的鲁棒性。在本文中,我们有λcoord=5,λcoord=0.5。

为了得到更准确的分类和检测结果,提高magic的泛化能力,本文进一步对多个YOLO模型的结果进行处理,得到了集成的YOLO算法。算法的伪码如算法1所示。其核心思想是利用多个训练效果较好的模型分别对图像进行预测,并对预测帧进行聚类。聚类过程如图5所示。

每个定位框可以描述为一个四维向量bi=(x1i,x2i,y1i,y2i),一个整数和一个实数pi。它表示:在左上角为x1i、y1i、右下角为x2iand和y2i的矩形中,有种数为ciis pi的蝴蝶的概率。设每个集群集为S1,S2,…,Sk。对于每个S i(i=1,2,…,k),满足:对于∀i,j∈S,ci=cj。将集合的“大体”定义为:
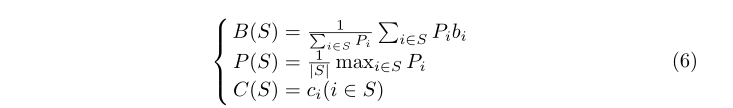
其中,B(S)是集合S的“聚合”定位框,P(S)是集合S的“聚合”概率,C(S)是集合S的“聚合”分类。每次对单个预测边界框进行分类时,从与检测框具有相同分类的所有集合中选择概率最大的集合S,并且IoU(B(S),B)≥0.5。如果没有符合条件的,则将该框放置在新的集合Sk+1中

本文以联合交叉点(IoU)作为蝴蝶定位任务的评价指标,定义为两个区域面积与合并区域面积之比。最佳比例为1,即完全重叠。实验中以IoU=0.5作为阈值,即预测盒和原标签盒正定位,IoU>0.5,IoU≤0.5正定位有误。本文将平均精度均值(mAP)作为蝴蝶分类任务的评价指标。地图来源于精确性(pre)和召回(recall)。计算公式如下。
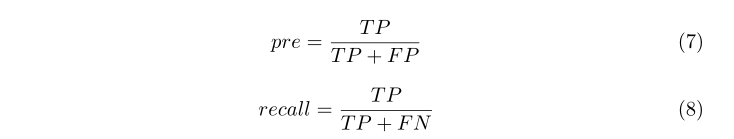
其中,TP(rue阳性数)、FP(假阳性数)和FN(假阴性数)分别表示预测为阳性的阳性样本数、预测为阳性的阴性样本数和预测为阴性的阳性样本数。
根据不同的置信水平,可以得到多个(pre,recall)点,并以查全率为横坐标,查准率为纵坐标,绘制出预查全率曲线。其中,平均精度AP是预召回曲线和召回轴周围的区域,这是预召回曲线的积分,如下所示

在实际应用中,通常用矩形面积和来逼近积分。本文采用PASCAL-VOC Challenge在2010年后的计算方法[15],即召回可以分为n个块[0,1n,…(n−1)n,1],然后平均准确度(AP)可以表示为
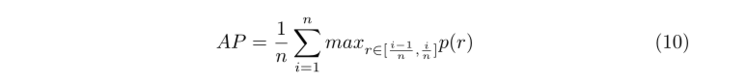

本文测试了两种不同的蝴蝶标记方法:一种是用蝴蝶的触角作为框架的边界,称为全标度标记法;另一种是用蝴蝶的躯干和翅膀作为框架的边界,称为非全标度标记法。采用不同的预处理方法,两种注释方法的最佳结果如表1所示。
可见,非满标度法的计算结果明显优于满标度法。由于满标度法中蝴蝶触角周围的面积较大,这会使蝴蝶触角周围的面积在标记区域中所占的比例降低,从而使背景环境对分类的影响变大。非全标记方法更适合于蝴蝶的自动检测和识别任务。
由于YOLO模型中输入图像大小的不同会导致不同输出尺度下的网格单元数目的不同,因此本文测试了不同输入尺寸下单个YOLO V3模型在蝴蝶自动定位任务中的性能。
采用非满标度法,无需任何其他预处理,三种输入尺寸的最佳结果如表2所示。
可见,采用608px×608px的分辨率输入具有较好的精度。

在蝴蝶自动定位和分类任务中,采用不同的预处理方法对608px×608px输入进行非完全标记,测试了单个YOLO V3模型的性能。表3显示了对分类结果有较大影响的两个参数的影响。
可以看出,通过旋转原始图像(0°、45°、90°、180°)并将其分别曝光1.0、1.2、1.5和1.8次,可以获得最佳的分类结果。mAP的值可以达到0.7766。特别是深色和保护色蝴蝶的识别率明显高于第一组。
我们在一个YOLO模型中选择了三个性能最好的模型(表3中的模型3、4、5)进行集成。在检测任务中,准确率达98.35%。在分类任务中,在测试集分类(94类)中得到0.798地图,在家庭分类(11类)中得到0.850地图。
表4显示了集成Yolo模型和主流目标检测模型(如fast RCNN、Yolo v3等)在蝴蝶自动检测和分类任务中的性能。
上述结果表明,本文提出的数据标注和预处理方法适用于蝴蝶的自动检测和分类任务。它还表明了由我们对自然生态照片中蝴蝶的检测和物种识别是非常有效和正确的。
目前,目标检测领域主要分为两大流派:端到端检测和分布式检测。端到端的检测速度很快,但与分布式检测方案相比,精度有很大差距。利用端到端模型的快速性和蝴蝶种群间的高度相似性,提出了一种基于不同浓度YOLO的综合模型,保持了端到端模型的检测速度,提高了检测精度和定位精度。
集成模型的本质是在各种条件下,根据模型的最优解来寻找更好的解。这样可以提高模型在特定训练集上的性能,提高模型的综合泛化能力。在文献[14]提供的测试集中,该模型在生态照片定位任务中的准确率达到98.35%,在物种定位识别任务中的准确率达到0.7978,在被试定位识别任务中的准确率达到0.8501。
蝴蝶在物种间具有很高的相似性,这表明在知识地图中,蝴蝶之间存在着很强的关系。对于范围更广的目标检测任务,利用知识地图可以对物种进行准确分类和定位,通过不同的模型能力和不同的识别焦点可以进一步优化其识别任务。










 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有