
©PaperWeekly 原创 · 作者|孙裕道
学校|北京邮电大学博士生
研究方向|GAN图像生成、情绪对抗样本生成

引言
面部表情是人类表达情感状态和意图的最有力、最自然、最普遍的信号之一。由于其在机器人、医疗、驾驶员疲劳监测和许多其他人机交互系统中的实际重要性,人们对自动面部表情分析进行了大量的研究。在计算机视觉和机器学习领域,各种各样的面部表情识别系统已经被用来编码来自面部表情的表情信息。本文会盘点出近几年来关于深度人脸情绪识别的优质论文。

Emotion Recognition via MBP

论文标题:Emotion Recognition in the Wild via Convolutional Neural Networks and Mapped Binary Patterns
论文链接:https://talhassner.github.io/home/publication/2015_ICMI
2.1 模型介绍
该论文提出了一种利用卷积神经网络从静态人脸图像中分类表情的新方法。作者通过去除输入图像中的混杂因素来简化问题域,减少有效训练深层 CNN 模型所需的数据量,用有限的情感标记训练数据对每个模型进行微调,得到最终的分类模型。该论文提出的方法可以分为三部分:
使用 LBP radius 参数的不同值对每个图像的像素进行(Local Binary Pattern)LBP 编码。
LBP 码通过多维标度(MDS)映射到 3 维空间中,该映射使用基于近似推土移动距离。
原始的 RGB 图像和映射的代码图像一起被用来训练多个独立的 CNN 模型来预测七个情绪类别中的一个。最后的分类是通过对网络集合的输出进行加权平均得到的,将预测的情感类别作为具有最大平均概率的类别。
2.1.1 LBP编码提取
LBP 编码捕捉局部图像的微观纹理。它们是通过对小邻域中像素的强度值应用阈值来生成的,使用每个邻域的中心像素的强度作为阈值。得到的 0(低于阈值)和 1(高于阈值)的图案将被视为像素的表示。当邻域包含其他 8 个像素时,这个二进制字符串被视为 0 到 255 之间的 8 位数字,并与支持向量机(SVM)分类器一起使用。
2.1.2 LBP编码映射
LBP 编码映射的关键是使用多维标度(MDS)即将无序的 LBP 编码值转换为度量空间中的点。这样,变换后的点可以使用卷积运算在一起求平均值,但它们的距离近似于原始码到码的距离。首先定义了 LBP 码之间的距离 。这个距离应该反映用于生成每个 LBP 码串的图像强度模式的潜在相似性。表示所有可能编码值之间的距离矩阵可以定义为:

对于给定的距离矩阵 ,MDS 寻求 LPB 编码到低维度量空间的映射,即:
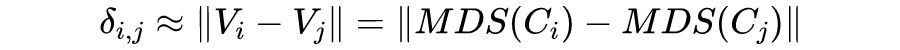
在这里,LBP 编码 , 映射到 ,。
使用 LBP 编码的推土移动距离(EMD)。EMD 被定义为反映将一个分布转化为另一个分布所需的最小花费。这里用它来衡量两个 LBP 代码之间的差异。P 和Q 两个编码之间的 EMD 定义如下:

其中 CDF 是位值的累积分布函数。
2.1.3 CNN集合
采用了四种不同的现有网络架构:VGG_S、VGG_M-2048、VGG_M-4096 网络,以及 BVLC-GoogleNet 网络。CNN 被训练成使用标记的情绪训练数据(七个不同的情绪类别和一个额外的“中性”类别)来预测情绪类别概率的 7 维向量。图像使用两个 RBG 值来表示,并提取具有三个不同参数值的 LBP 编码:默认值为 1、5 和 10。
为了比较原始 EMD 距离,对 LBP 码直接使用 EMD 近似进行编码。为了预测情绪标签,我们取 20 个集合模型产生的 7 维输出向量的加权平均值。所选的类是产生的 7 维平均预测向量中概率最高的类。权重反映了每个分量的相对重要性。这些是通过随机搜索不同的权重组合来确定的,使用训练数据来评估每个组合的质量。

2.2 实验结果
下表总结了所有不同网络架构和图像表示的验证集结果。用于 LBP 表示的下标表示使用的参数的值。实验结果显示,这些特征是通过梯度直方图金字塔产生的特征和局部相位量化从对齐的人脸中提取,并使用单独的支持向量机融合进行分类。集成结果大大提高了性能,性能显著提高了 40%(提高了15.36%)。

下图提供了一个正确和错误的分类结果图示,所有剩余的六个类别如下图所示。这些结果表明,至少在某些情况下,性能差的原因可能是面部对齐步骤的失败,而不是模型识别的问题。


Deep-Emotion

论文标题:Deep-Emotion: Facial Expression Recognition Using Attentional Convolutional Network
论文链接:https://arxiv.org/pdf/1902.01019.pdf
3.1 模型介绍
在该论文中,作者提出了一种基于注意卷积网络的人脸表情识别方法,它能够集中于脸部的重要部位,并且使用一种可视化技术,该技术能够根据分类器的输出找到重要的面部区域来检测不同的情绪。
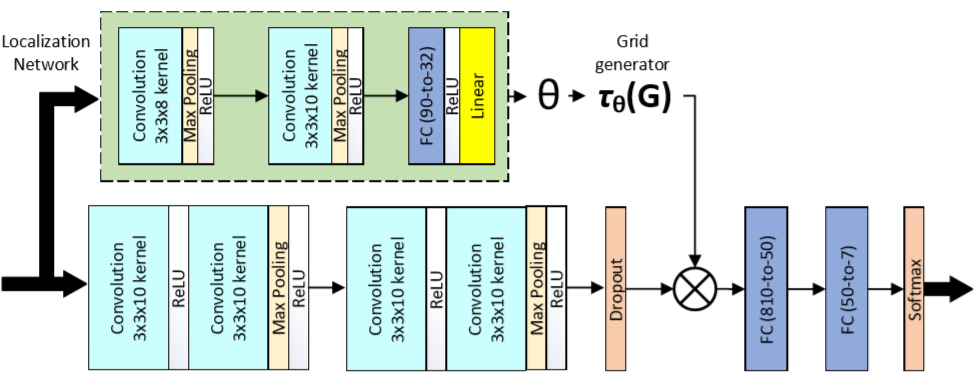
上图为本文提出的的模型架构。其中特征提取部分由四个卷积层组成,每两个卷积层之后是最大池化层和线性单元(ReLU)激活函数。接着是一个 dropout 层和两个全连接层。
空间转换器由两个卷积层(每个卷积层后面是 max pooling 和 ReLU)和两个全连接层组成。在回归变换参数后,将输入转换为采样网格的生成数据。空间变换器模块主要通过估计被关注区域上的一个样本来聚焦图像中最相关的部分。
作者使用不同的变换对输入和输出进行映射。通过使用随机梯度下降法(更具体地说是 Adam 优化器)优化损失函数来训练该模型。本文中的损失函数是两个项的总和,分类损失(交叉熵)和正则化项的总和。
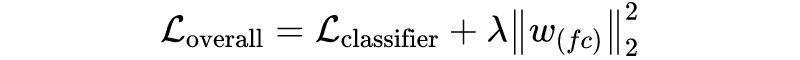
正则化权重 在验证集上进行调整。添加 dropout 层和 项使训练模型更稳定。
3.2 实验结果
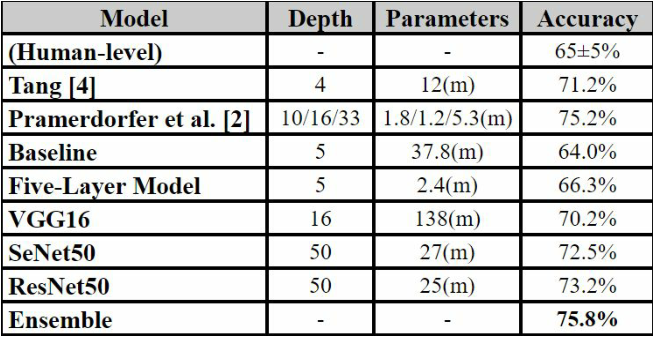
本文提出的模型在 FERG 数据集测试,首先使用大约 34k 个图像进行训练,14k 用于验证,7k 用于测试。对于每个面部表情,随机选择 1k 图像进行测试。由下表可知模型识别的准确率在 99.3% 左右,其它的识别效果都要好。

本文提出的模型在 CK+ 数据集测试,其中 70% 的图像用于训练,10% 用于验证,20% 用于测试。实验结果如下,可以看出本文提出的模型表现的依然不错。

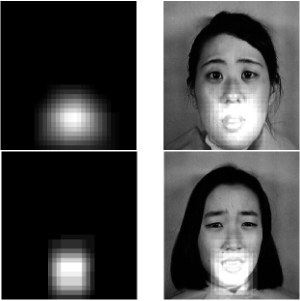
本文最大的一个特点在于引入了注意力机制,可以找到跟表情相关的区域。下图诶三幅带有“恐惧”表情的图像的重要区域。从图中可以看出,这些图像的重要区域在检测口腔时非常相似。

FER with Deep Learning

论文标题:Facial Expression Recognition with Deep Learning
论文链接:https://dl.acm.org/doi/abs/10.1145/3240876.3240908
4.1 模型介绍
在这篇论文中,作者深入研究了面部表情识别的多个深度学习模型,贡献有如下两个分别为:
4.1.1 Fine Tuning ResNet50
ResNet50 是本论文的预训练模型二。ResNet50 是一个有 50 层的深度残差网络。它在 Keras 中定义为 175 层。作者分别用最大输出层和输出层分别为 1024 个和 96 个输出层。冻结了 ResNet 中的前 170 层,并保持网络的其余部分可训练。
采用 SGD 作为模型的优化器,学习率为 0.01,批量大小为 32。以 0.01 的学习率和 128 个批次的 SGD 对 122 个 epoch 进行训练,得到了 73.2% 的正确率。
4.1.2 Fine Tuning VGG16
VGG16 是本论文的预训练模型三。虽然比 ResNet50 和 SeNet50 浅得多,只有16层,但 VGG16 更复杂,参数也更多。作者保持所有预训练层冻结,并添加了两个大小分别为 4096 和 1024 的 FC 层,其中 50% 丢失。在使用 Adam 优化器进行 100 次训练后,在测试集上获得了 70.2% 的准确率。
4.1.3 Author’s methods
作者在训练模型过程的时候一共分为 4 个步骤最终将模型识别的准确率提升到 75.8%,分别为:
数据增强:将人脸表情图像进行水平镜像、±10 度旋转、±10% 图像缩放和 ±10% 水平/垂直移动等。
分级权重:为了解决类不平衡问题,采用了与样本数成反比的类权重。
SMOTE:合成少数过采样技术(SMOTE)包括过采样少数类和欠采样多数类,以获得最佳结果。
综合模型:对七个模型进行了软投票,使最高测试准确率从73.2%提高到75.8%。
4.1.4 MOBILE WEB APP
从架构上讲,作者的 web 应用程序托管在 Firebase 上利用 Tensorflow.js, React.js 标准为了检测、裁剪和调整用户的面部尺寸,并将其作为带有一个灰度通道的 48x48 图像输入到模型。
此外,为了减少磁盘空间和内存占用,在下载到用户设备之前,使用 tensorflowjs 转换器缩小模型权重。


实验结果
下表显示了作者在 FER2013 私有测试数据集上实现的最佳模型的精确度。可以看出作者训练的模型能够达到最好的识别效果。
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。








 京公网安备 11010802041100号
京公网安备 11010802041100号