AttentiveNormalizationforConditionalImageGeneration前提知识语义分割什么是语义分割?IN(instancenorma
Attentive Normalization for Conditional Image Generation
- 前提知识
- 语义分割
- IN( instance normalization)实例标准化
- Conditional Image generation
- 什么是Conditional Image generation
- application of conditional image generation
- how to generate images from a class label
- Long-range dependency in image generation
- Prior work:SAGAN
- 摘要
- 介绍
- 3. 方法
- 3.1.语义布局学习模块
- 3.2 软语义布局计算
- 3.3 局部归一化
- 3.4 分析
- 1. 为什么自抽样正则化很有效
- 2. 学习到的语义布局的有效性
- 3. 复杂度分析
- 应用(Applications with Attentive Normalization)
- 实验结果
- 总结
用于条件图像生成的注意力归一化
前提知识
语义分割
什么是语义分割?
语义分割是指像素级的图像理解,即对图像中的每个像素标注所属的类别。示例图如下所示:

左:输入图像 右:图像的语义分割结果
除了识别图中的摩托车和车手外,我们还要标注每个目标的边界。因此,不同于图像分割,语义分割需要模型能够进行密集的像素级分类。
IN( instance normalization)实例标准化
关于BN的理解参考
BN 和 IN 其实本质上是同一个东西,只是 IN 是作用于单张图片(对单个图片的所有像素求均值和标准差),但是 BN 作用于一个 batch(对一个batch里所有的图片的所有像素求均值和标准差)。IN 在训练和测试阶段都用,BN 只在训练阶段用,测试阶段用训练时通过指数衰减滑动平均保存的均值和方差
Conditional Image generation
什么是Conditional Image generation
给定类别的标签来生成图像
比如说给定熊猫的标签,生成器生成一些熊猫的图片
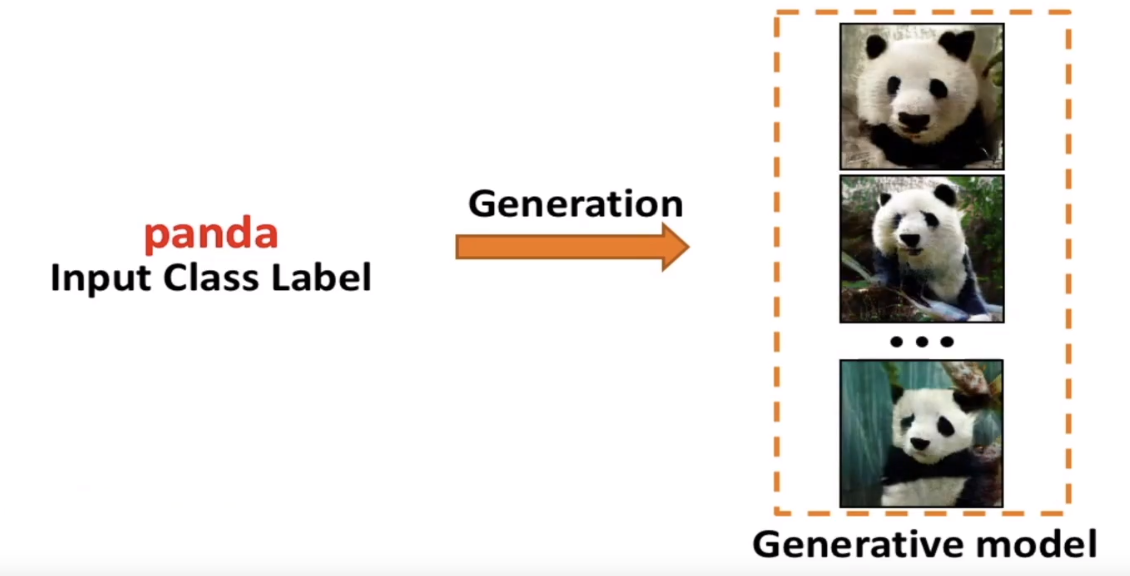
application of conditional image generation
- Image creation and editing(图像创造或者是编辑)
- Data augmentation(图像增强)
- Others.

how to generate images from a class label
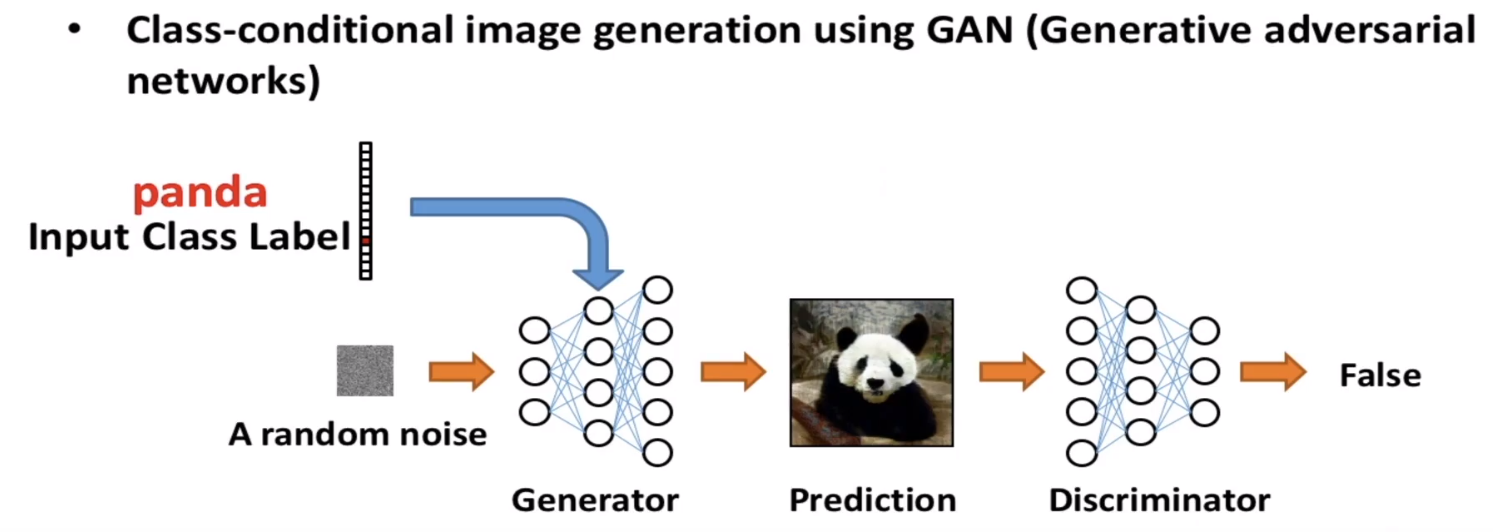
- Class-conditional image generation using GAN(Generative adversarial networks)
CGAN
Long-range dependency in image generation
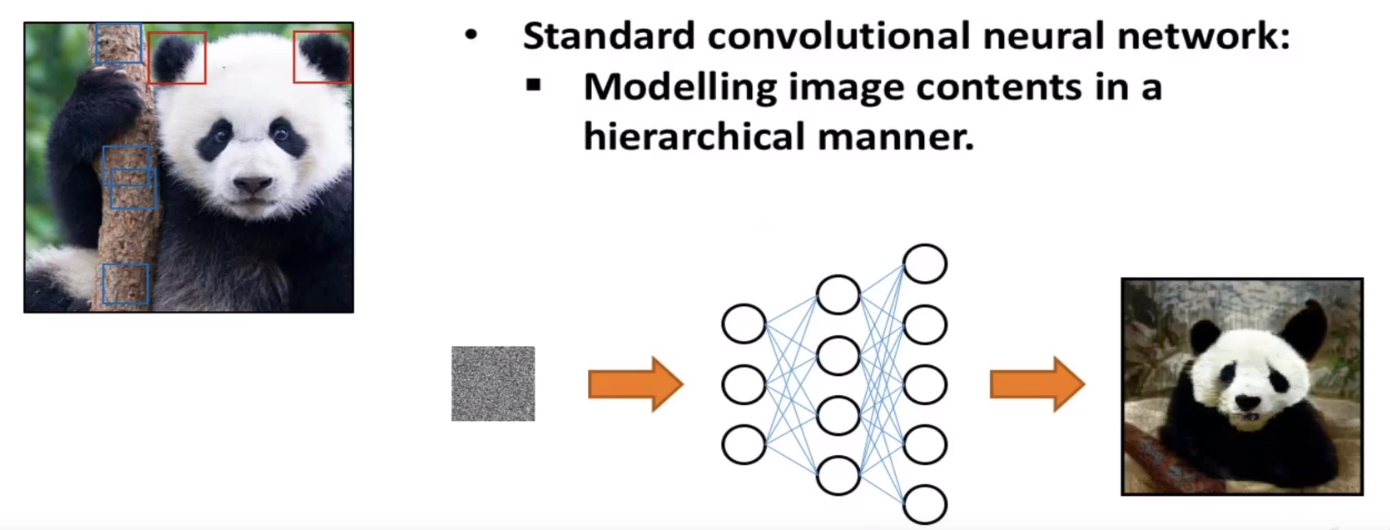
- Standard convolutional neural network:
- Modelling image contents in a hierarchical manner
- Long-range dependency in conduct in a Markov chain.
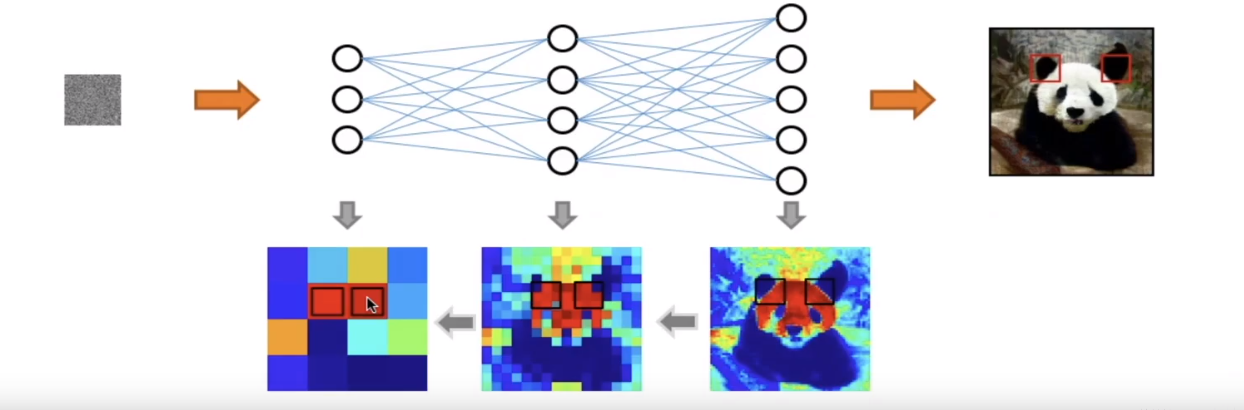
Prior work:SAGAN
SAGAN笔记
比如说:用相似度比较高的点来重构某个像素点
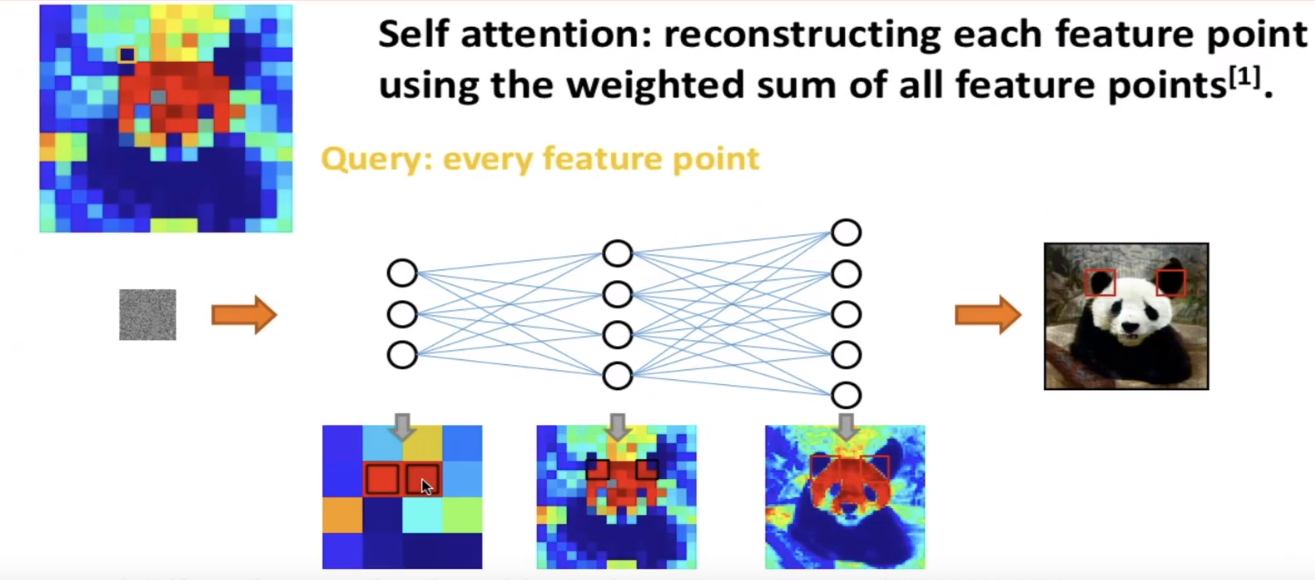
摘要
传统基于卷积的生成对抗网络(DCGAN、CGAN):
在卷积神经网络中,每个卷积核的尺寸都是很有限的(基本上不会大于 5),因此每次卷积操作只能覆盖像素点周围很小一块邻域。
对于距离较远的特征,例如狗有四条腿这类特征,就不容易捕获到了(也不是完全捕获不到,因为多层的卷积、池化操作会把feature map的高和宽变得越来越小,越靠后的层,其卷积核覆盖的区域映射回原图对应的面积越大。但总而言之,毕竟还得需要经过多层映射,不够直接)。
this paper:用注意归一化(Attention Normalization—AN)来描述长期依赖性:
- 输入特征图根据其内部语义相似性被轻轻地划分为几个区域,分别被归一化
- 通过语义对应关系增强了遥远区域之间的一致性。(实现全局性)
- 与
SAGAN对比,我们的注意归一化不需要测量所有位置的相关性,因此可以直接应用于扩大特征图,而无需承担太多的计算负担。(更低计算、扩展性)
介绍
GAN-application:图像创建,编辑,鉴别任务中数据增强。
大多数图像生成—使用全卷积:局部性,无法捕捉到全局信息,结构信息。
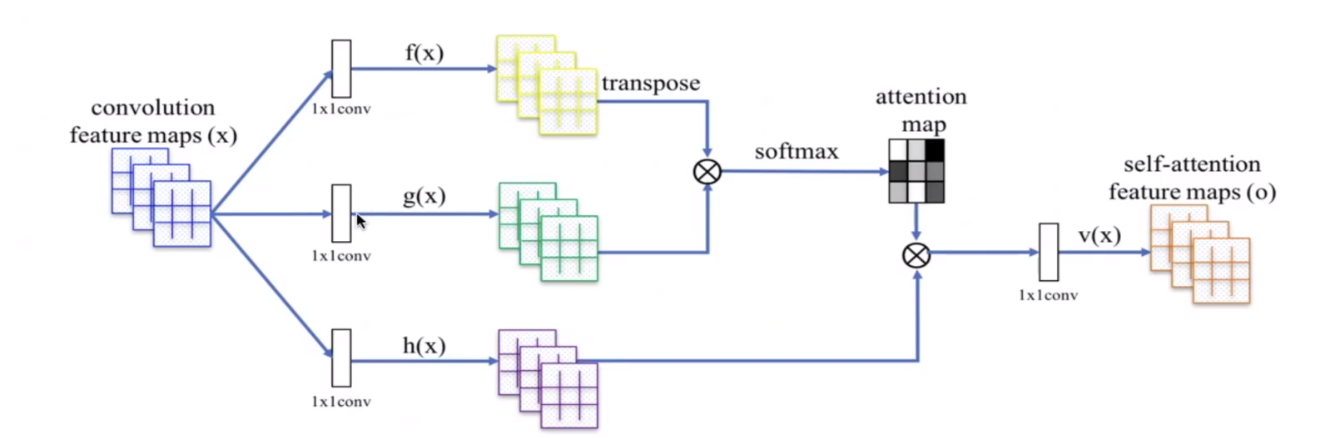
SAGAN = self-attention + DCGAN + … :
- 第一次尝试捕捉全局信息(利用
self-attention捕捉远距离的关系) - 缺点:自我注意模块需要计算特征图中每两点之间的相关性,计算成本大!!!
IN:
我们的方法建立在实例标准化(IN)的基础上,
但是之前的(IN)解将特征映射沿其空间维数的均值和方差归一化。这种策略忽略了这样一个事实,即不同的位置可能对应于具有不同均值和方差的语义。这种机制倾向于在空间上恶化中间特征的学习语义。

根据输入特征图预测的语义布局,对输入特征图进行了空间规范化, 它改善了输入中的远距离关系,并在空间上保留了语义。
语义布局的估计依赖于两个经验观察。
1.特征映射可以看作是`多个语义实体`的组合
2.神经网络中的`深层`捕获了输入图像的`高级语义`
语义布局学习模块:
- 语义布局预测—
semantic layout prediction - 前者产生语义感知掩码,将特征映射分成几个部分。
- 自采样正则化—
self-sampling regularization - 自采样正则化规范了语义布局预测的优化,避免了琐碎的结果。
通过语义布局,空间信息传播通过每个区域独立的归一化进行。自然地增强了具有相似语义的特征点之间的关系,超出了空间极限,因为它们的分布通过归一化变得紧凑。它们的共同特征通过其专有的可学习仿射得以保留,甚至得到增强转型。
主要贡献:
注意归一化(AN):在图像生成过程中捕捉中间特征图中的视觉遥远关系。从输入特征图预测语义布局,然后基于该布局对特征图进行区域实例规范化。- 该模块在语义相似的区域内同时融合和传播特征统计量,计算复杂度较低。
3. 方法
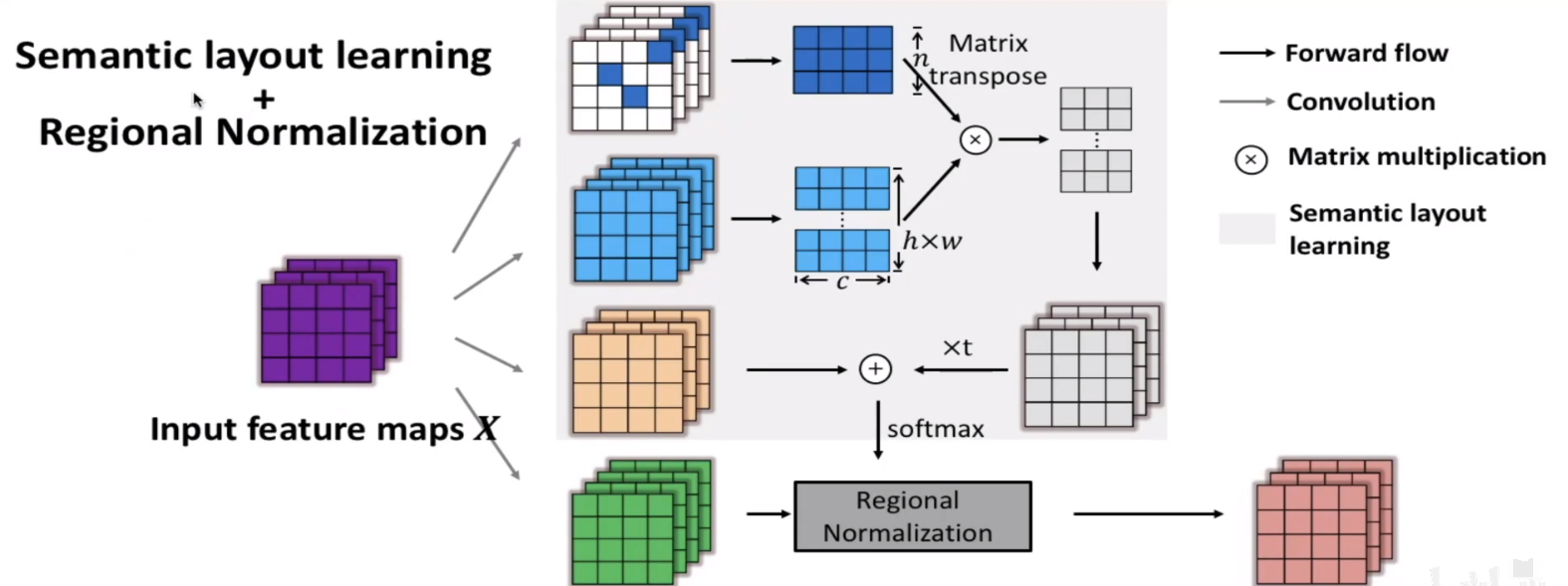
思想:根据特征映射的语义将划分为不同的区域,然后分别对同一区域的特征点进行归一化和去归一化。
第一个任务由建议的语义布局学习(SLL)模块解决,第二个任务由区域规范化进行。
3.1.语义布局学习模块
语义学习分支
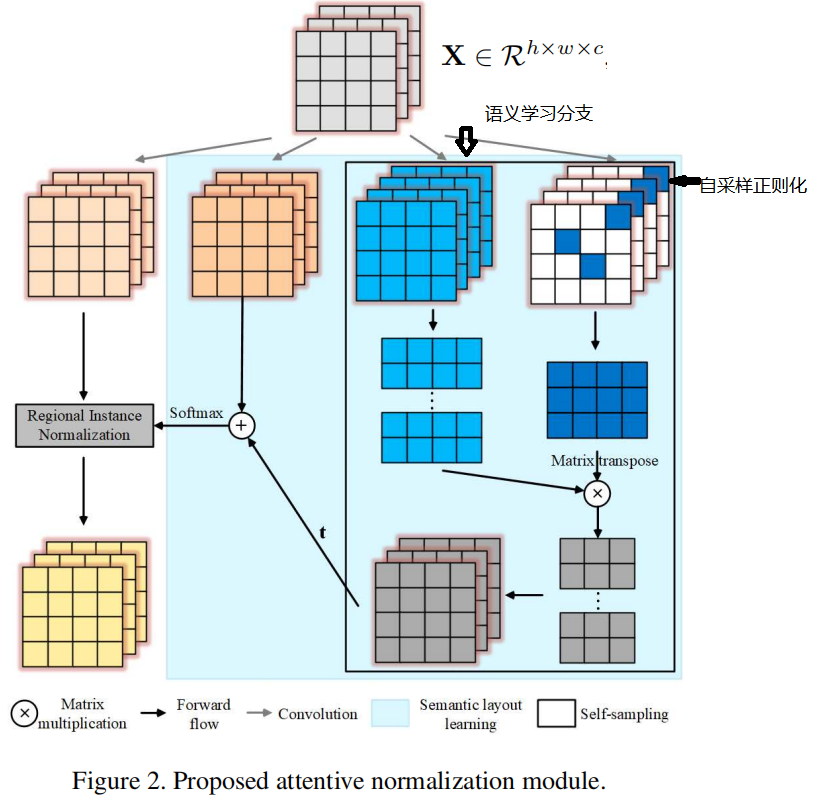
假设每幅图像由n个语义实体组成,对于图像特征图的每个特征来说,其至少由一个语义实体所决定。这个假设给出了一种表达力很强的表示。因为这些实体可表示不同语境下的同一个已知事物。目前这一假设广泛应用于无监督表示学习。在语义布局的学习中,如何根据特征点与语义实体的关系聚拢特征点非常重要,因为这加大同类的类间相似度(intra-similarity)。
具体而言,研究员首先会给定n个理想的语义实体,然后将其与图像特征点的相关程度定义为其内积,最后,表示这些实体的语义通过反向传播进行学习。基于这些实体的激活状态,可以将输入特征图上的特征点聚合到不同的图像区域上。进一步,为加强这些实体所对应的不同模式,对这些实体进行正交正则化:
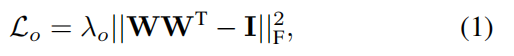
- W∈Rn×cW \in R^{n \times c}W∈Rn×c 是由这些n个实体组成的权重矩阵(每行是行向量形式的跨越权重)
在我们的实现中,采用了具有n个滤波器的卷积层作为语义实体。该层将输入特征映射的XXX转换为新的特征空间,转换为f(X)∈Rh×w×nf(X)∈R^{h×w×n}f(X)∈Rh×w×n。直观地说,n越大,就可以学习到更多样化和更丰富的高级特征。n=16在经验上适合进行128×128类条件图像生成和256×256生成图像绘制。
仅仅依赖这个语义布局学习模块并不能让模型得到有效训练,因为这个模块会倾向于用单个语义实体来聚集所有特征点。具体原因是没有设置策略来对那些与输入特征点关联弱或根本无关联的无意义语义实体进行限制。为此,本文引入自采样分支,以提供一个合理的初始语义布局估计,避免上述问题的发生。
自采样正则化分支
思路:先从特征图中随机的采取n个特诊点,
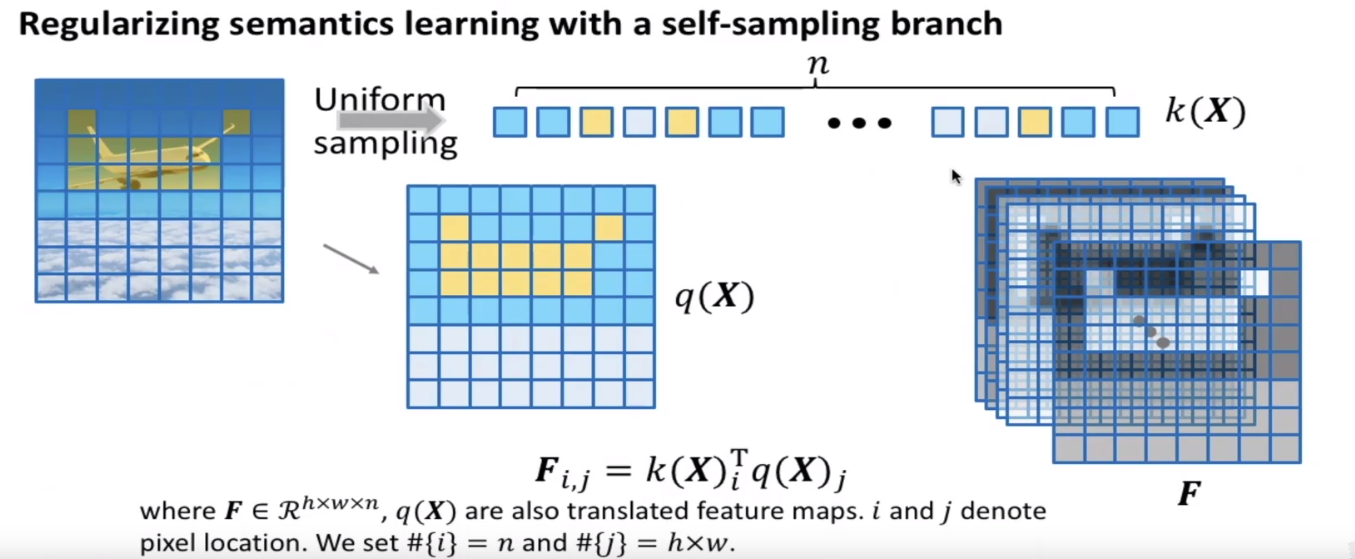
受到特征量化工作的启发,研究员引入自采样分支来对语义的学习过程进行正则化。自采样分支会从输入特征图上随机选取n个特征点,作为语义实体的可选项。然后,当发现某些实体与输入特征图关联度很低后,这个分支就会激活。会利用我们随机采样的n个特诊点大概的估计语义分割图,它会利用同一张特征图里的相关性来近似估计语义布局。
具体而言,分支会从特征图k(X)上均匀采样n个特征像素,作为初始的语义滤波器。进一步,为了捕获更多明显的语义信息,研究员对k(X)先进行最大池化,然后计算一个激活状态图FFF:
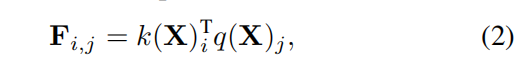
- F∈Rh×w×nF ∈ R^{h×w×n}F∈Rh×w×n
- q(X)q(X)q(X)
- i和ji和ji和j表示像素的位置 ,#{i} = n and #{j} = h × w.
3.2 软语义布局计算
随着缓慢更新的f(X)f(X)f(X)(语义学习分支)和快速生成的FFF(自采样正则化),原始语义激活映射SrawS^{raw}Sraw被计算为
Sraw=tF+f(X)S^{raw} = tF + f(X) Sraw=tF+f(X)
- 其中t∈R1×1×nt∈R^{1×1×n}t∈R1×1×n是一个初始化为0.1的可学习向量。
- 能够逐渐调整自采样分支带来的影响,使得当训练中出现无意义实体后,自采样分支能够提供有意义的实体可选项。
然后用softmax对SrawS^{raw}Sraw进行了归一化,得到软语义布局:
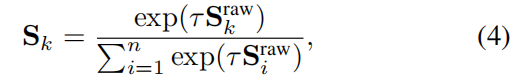
- 其中,i和ki和ki和k索引了特征通道
- 每个SkS_kSk都是一个soft mask,表示属于k.τk.τk.τ类的每个像素的概率是控制预测语义布局平滑度的系数,默认值设置为0.1。
3.3 局部归一化
基于得到的软语义布局,对特征图中长距离关系的建模可以通过局部实例归一化完成。它关注空间信息,将每个独立区域作为一个实例:
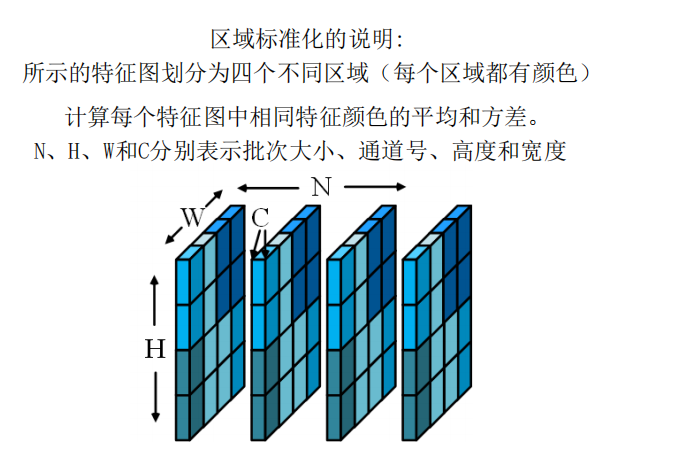
有同样或类似语义的特征点间的相关性可以通过共享的均值与方差来改进,写为:
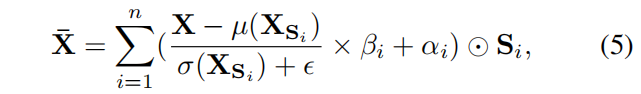
- XSi=X⊙SiX_{S_i} =X⊙S_iXSi=X⊙Si。—提取语义
- βi和αiβi和αiβi和αi是仿射变换的可学习的参数向量(∈R1×1×c∈R^{1×1×c}∈R1×1×c),分别初始化为1和0。
- µ(⋅)和σ(⋅)µ(·)和σ(·)µ(⋅)和σ(⋅)分别计算与实例之间的平均值和标准偏差。
AN关于原始输入特征图的最终输出结果为:
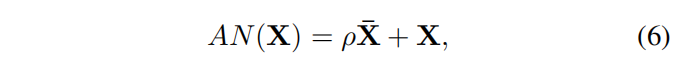
- ρρρ是一个初始化为0的可学习的标量。
- 通过逐渐在局部归一化上施加更多注意力,这种残差学习的方式能够平滑学习曲线。
3.4 分析
1. 为什么自抽样正则化很有效
它可以从当前特征图中自适应地捕获语义,如果不充分了解部分语义实体,则可以生成适当的语义实体候选。 当深度特征无法捕获语义时,统一采样使得这样的过程在早期训练阶段就不支持特定类型的语义。
而且,这样的采样使得训练过程中所使用的实体替代方案发生变化。 我们注意到,无用实体的已激活替代项的变体对于学习语义实体至关重要,因为它可以刺激当前学习的无用实体捕获输入特征图中的现有语义。 在我们的实验中已通过实验验证(第5节)。 简而言之,该策略通过仅学习单个语义实体来使SLL正规化,并导致了解更多现有的语义。
2. 学习到的语义布局的有效性
预测的语义布局指示语义上具有较高内部一致性的区域。 如图所示,根据我们预测的语义布局突出显示的区域计算出的标准差比根据生成的图像的整个中间特征图计算出的标准差要低得多(第一行分别为0.35、0.44和1.09对4.77,以及 0.41、0.71和0.81比第二行的5.40)。 根据它们的相似性对这些点进行区域归一化可以更好地保留学习到的语义。

如下图所示,学习到的语义实体通过激活特征图的不同区域来显示它们的多样性。注意,突出的前景对象可以被检测到作为背景部分。一些实体关注对象的部分内容,因为这些区域与给定的标签信息高度相关。如第一行©和(f)所示,它们分别突出了熊猫的耳朵/身体和面部区域,具有高度辨别的特征。

3. 复杂度分析
除了生成中间特征图的卷积计算外,主要的计算方法是自采样和区域归一化。它们都花费O(NHWnC)O(NHWnC)O(NHWnC),导致最终的O(nNHWC)O(nNHWC)O(nNHWC),其中N、H、W和C分别表示输入特征映射的批大小、高度、宽度和信道号。
AN消耗的量远少于自我注意模块(具有时间复杂度O(N(H2W2CHWC2))O(N(H^2W^2CHWC^2))O(N(H2W2CHWC2))。它没有关于特征图的空间大小的平方项。
应用(Applications with Attentive Normalization)
本文把提出的AN整合进两个GAN框架,分别进行类条件图像生成(class-conditional image generation)和生成式图像修复(generative image inpainting)任务
1. 类条件图像生成

类条件图像生成。此任务通过在给定图像上进行训练来学习合成图像分布。通过生成器G,系统会将一个随机采样的噪声z映射到图像x(标签为y)上。
本文中,生成器G由5个残差块组成,在第3个残差块上使用了AN,如下图所示。另外,判别器D由5个残差块组成,在第一个残差块上使用了AN模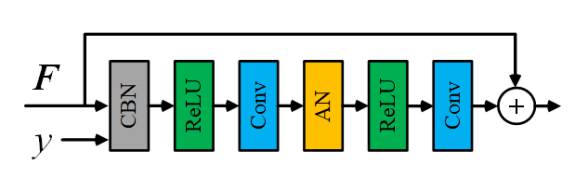
处于优化的目的,用于训练生成器的对抗损失写为:
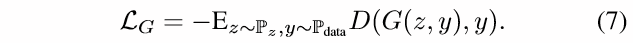
其对应的判别器更新损失为:
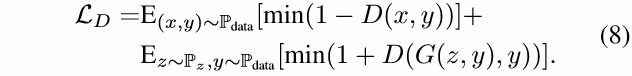
2. 生成式图像修复
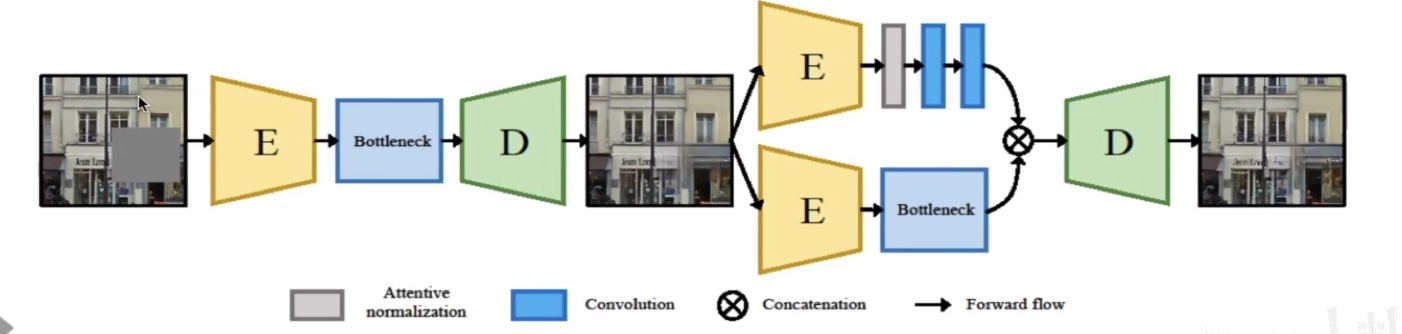
这项任务将不完整图像C和一个mask M(像素缺失即值为1,存在像素则值为0)作为输入,然后基于图像展示的语境,预测一个视觉上看起来合理的结果。生成的内容需要与既有内容连贯。在该任务中,通过对已知区域的探究来填补未知区域至关重要。
本文使用了一个两阶段神经网络框架,这两个阶段均利用了编码解码结构。其中AN用于第二阶段,对图像语境信息进行处理以优化最终的预测区域。
在这个任务中,学习的目标包括一个重建项和一个对抗项:
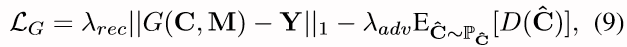
至于判别器D的训练,使用了WGAN-GP 损失:
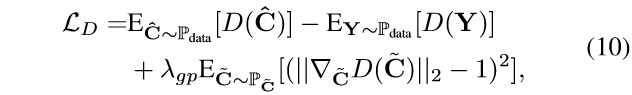
实验结果
由于类条件图像生成和生成式图像修复都需要生成足够可信的物体与复杂场景,很依赖对图像上远距离信息间关系的建模,因此本文选择这两项任务来评估AN对长距离关系的建模能力。
类条件图像生成
本文方法在ImageNet上进行类条件图像生成任务的量化结果(表1):
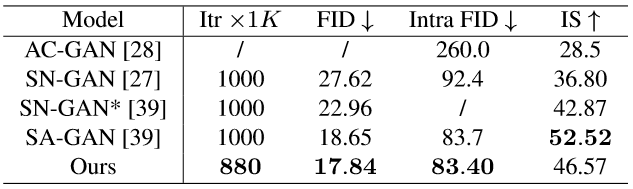
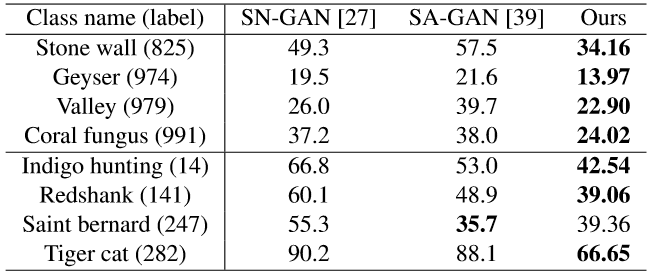
从表2可知,在对自然场景或纹理(第一大行)以及复杂结构关系(第二大行)的处理上,AN均在Intra FID指标上(越低越好)显著超越了SN-GAN,且极少数任务不及SA-GAN。
表2:在ImageNet的典型图像类别上的类条件生成Intra FID指标对比:
通过下图也可以在视觉上验证这个结果,即AN可以很好处理纹理(Alp、Agaric)和结构敏感(Drilling platform、Schooner)的问题。

生成式图像修复
生成式图像修复任务依赖于长距离语义关系以及类条件图像生成。与类条件图像生成的不同之处在于,在生成式图像修复任务中,语境区域的特征是已知的。如图9所示,本文方法得出的结果在视觉效果上会有更多语义布局(墙面与窗户)与纹理细节。量化评估测试(表3)结果也表明,本文方法能够增强信息在跨空间区域上的融合。
图9:Paris Streetview数据集上,生成式图像修复任务对比,(a)输入图像,(b)CA结果,(c)本文结果

表3:Paris Streetview数据集上的量化对比

总结
本文提出一个在条件图像生成任务上通过归一化进行远距离关系建模的新方法,它由语义布局学习与局部归一化两个操作组成,学习得到的语义布局足以让局部归一化来保留和增强从生成器习得的语义相关性。








 京公网安备 11010802041100号
京公网安备 11010802041100号