论文笔记——ASurveyonTextClassification_FromShallowtoDeepLearning1.1摘要回顾了1961年至2020年的最新研究方法&#x
论文笔记——A Survey on Text Classification_From Shallow to Deep Learning
1.1 摘要
回顾了1961年至2020年的最新研究方法,重点关注从浅学习到深度学习的模型。我们根据所涉及的文本和用于特征提取和分类的模型,建立了文本分类方法。然后我们详细讨论每一个类别,处理支持预测测试的技术发展和基准数据集。本调查还提供了不同技术之间的综合比较,以及识别各种评价指标的优缺点。最后,总结了该研究的关键意义、未来研究方向和面临的挑战。

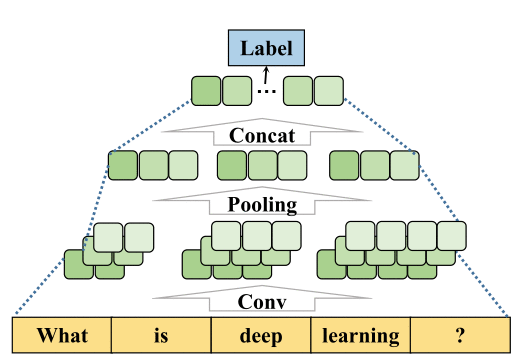
每个模块中使用经典方法进行文本分类的流程图
浅学习模型通常需要通过人工方法获得较好的样本特征,然后再使用经典的机器学习算法进行分类。因此,该方法的有效性在很大程度上受到特征提取的限制。然而,与浅层模型不同的是,深度学习通过学习一组非线性转换将特征工程集成到模型拟合过程中,这些非线性转换将特征直接映射到输出。大部分的文本分类研究工作都是基于DNNs(Deep Neural Networks)的,DNNs是一种数据驱动、计算复杂度高的方法。
1.2 文本分类方法
(一)浅学习模型步骤:首先是对原始输入文本进行预处理,用于训练浅学习模型,一般包括分词、数据清理和数据统计。然后,文本表示的目标是将预处理后的文本以一种更易于计算机使用并最大限度地减少信息丢失的形式表示,最后,根据选择的特征将表示的文本输入到分类器中。

特性工程是一项艰巨的工作。在训练分类器之前,我们需要收集知识或经验从原始文本中提取特征。浅学习方法根据从原始文本中提取的各种文本特征训练初始分类器。

(二)深度学习模型

1)ReNN:将输入文本的每个单词作为模型结构的叶节点。然后使用权重矩阵将所有节点合并成父节点。权重矩阵在整个模型中共享。每个父节点与所有叶节点具有相同的维度。最后,所有节点递归地聚合成一个父节点来表示输入文本以预测标签。

递归神经网络的结构
2)MLP:这是一个三层MLP模型。它包含一个输入层、一个在所有节点中都有激活功能的隐藏层和一个输出层。每个节点连接一个特定的权重wi。段落向量(Page-Vec)是基于它的方法(与CBOW相比,它增加了一个通过矩阵映射到段落向量的段落标记。该模型通过这个向量与单词的三个上下文的联系或平均值来预测第四个单词。段落向量可以被用作段落主题的存储器,并且被用作段落函数并被插入到预测分类器中)。

多层感知器的结构(MLP)
3)RNN:首先,使用单词嵌入技术用特定的向量来表示每个输入单词。然后,将嵌入的单词向量一个接一个地输入RNN单元。RNN单元的输出与输入向量的维数相同,并被馈送到下一个隐藏层。RNN在模型的不同部分共享参数,并且每个输入单词的权重相同。最后,输入文本的标签可以通过隐藏层的最后输出来预测。
递归神经网络的结构(RNN)
在RNN的反向传播过程中,权重通过梯度来调整,梯度通过导数的连续乘法来计算。如果导数极小,通过连续乘法可能会引起梯度消失问题。长短期记忆(LSTM) (RNN的改进),有效地缓解了梯度消失问题。它由一个在任意时间间隔内记住值的单元和三个控制信息流的门结构组成。门结构包括输入门、忘记门和输出门。LSTM分类方法能够更好地捕捉上下文特征词之间的联系,利用遗忘门结构过滤无用信息,有利于提高分类器的整体捕捉能力。
4)CNN:首先,将输入文本的词向量拼接成一个矩阵。然后将矩阵送入卷积层,卷积层包含几个不同维度的滤波器。最后,卷积层的结果经过池化层,并将池化结果串接起来,得到文本的最终向量表示。分类由最终向量预测。TextCNN可以通过一层卷积更好地确定最大池化层的判别短语,并通过保持词向量静态的方式学习除词向量外的超参数。
据文本的最小嵌入单元,将嵌入方法分为字符级、单词级和句子级嵌入方法。字符级嵌入可以解决词汇表外(OOV)的单词。词级嵌入学习单词的语法和语义。此外,句子级嵌入可以捕捉句子之间的关系。

卷积神经网络(CNN)的架构
5)Attention:
层次注意网络(HAN),通过利用文本的极具信息成分来获得更好的可视化,如图11所示。HAN包括两个编码器和两个层次的注意层。注意机制让模型对特定的输入给予不同的注意。该方法首先将基本词汇聚合成句子向量,然后再将关键句子向量聚合成文本向量。通过两个层次的注意,可以了解每个单词和句子对分类判断的贡献大小,有利于应用和分析。

层次注意网络的体系结构(HAN)
Self-attention在句子中构造K、Q和V矩阵来捕获单词在句子中的权重分布,这些矩阵可以捕获对文本分类的长期依赖。每个输入词向量ai可以表示为三个n维向量,包括qi、ki、vi。自我注意后,输出向量ai可以表示为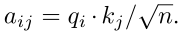 和,所有的输出向量都可以并行计算
和,所有的输出向量都可以并行计算
self-attention的一个例子
6)Transformer:通常使用无监督方法自动挖掘语义知识,然后构造预训练目标,以便机器学习理解语义。
预训练模型

预训练模型架构
7)GNN:将文本分类转换为图形节点分类任务。首先,将四个输入文本和文本中的单词定义为节点,构造成图形结构。图节点由黑色粗体边连接,黑色边表示文档-单词的边和单词-单词的边。单词边缘的权重通常表示单词在语料库中的共现频率。然后,通过隐藏层来表示单词和文本。最后,通过图来预测所有输入文本的标签。
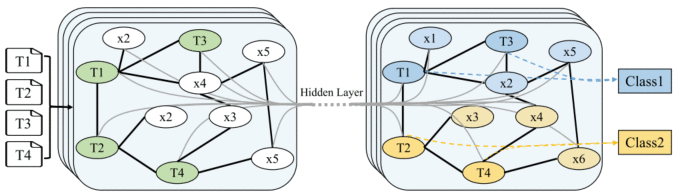
GCN的模型
DGCNN是一个将文本转换为词图的graph-CNN,具有通过CNN模型学习不同层次语义的优势。
TextGCN文本图卷积网络,为整个数据集构建异构的词文本图,并捕获全局词共现信息。
TextING为每个文档构建单独的图表,并通过GNN学习文本级别的单词交互,从而有效地在新文本中生成模糊单词的嵌入。
图注意网络(GATs)通过关注它的邻居来使用隐藏的自我注意层。因此,提出了一些基于GAT的模型来计算每个节点的隐藏表示。具有双重注意机制的异构图注意网络(HGAT)学习当前节点中不同相邻节点和节点类型的重要性。该模型在图上传播信息并捕获关系,以解决半监督短文本分类的语义稀疏性问题。MAGNET基于GATs捕获标签之间的相关性,该方法学习标签之间的关键相关性,并通过特征矩阵和相关矩阵生成分类器。
一些DNNs历年的数据,评价指标和实验数据集等

(应用包括情感分析(SA)、主题标注(TL)、新闻分类(NC)、问答(QA)、对话行为分类(DAC)、自然语言推理(NLI)、关系分类(RC)和事件预测(EP))
1.3 数据集与评价指标
(一)数据集
数据集的汇总统计 C:目标类别数量 L:平均句子长度 N:数据集大小

(二)评价指标

1)准确率、错误率:
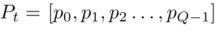
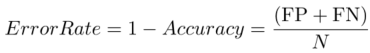
2)精确度、召回率、F1:
3)Micro-F1:
4)Macro-F1:
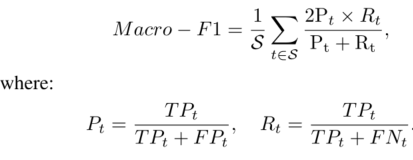
5)P@K: 每个文本都有一组L个基本事实标签,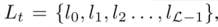 按照概率递减的顺序,,k处的精度为:
按照概率递减的顺序,,k处的精度为:
其中,L是每个文本上的基本事实标签或可能答案的数量,k是极端多标签文本分类中所选标签的数量。
6)NDCG@K:
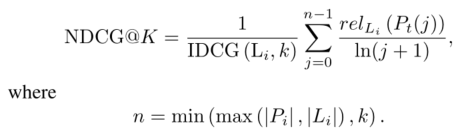
1.4 性能
基于深度学习的文本分类模型在原始数据集上的准确性由分类准确性评估

1.1 摘要
回顾了1961年至2020年的最新研究方法,重点关注从浅学习到深度学习的模型。我们根据所涉及的文本和用于特征提取和分类的模型,建立了文本分类方法。然后我们详细讨论每一个类别,处理支持预测测试的技术发展和基准数据集。本调查还提供了不同技术之间的综合比较,以及识别各种评价指标的优缺点。最后,总结了该研究的关键意义、未来研究方向和面临的挑战。

每个模块中使用经典方法进行文本分类的流程图
浅学习模型通常需要通过人工方法获得较好的样本特征,然后再使用经典的机器学习算法进行分类。因此,该方法的有效性在很大程度上受到特征提取的限制。然而,与浅层模型不同的是,深度学习通过学习一组非线性转换将特征工程集成到模型拟合过程中,这些非线性转换将特征直接映射到输出。大部分的文本分类研究工作都是基于DNNs(Deep Neural Networks)的,DNNs是一种数据驱动、计算复杂度高的方法。
1.2 文本分类方法
(一)浅学习模型步骤:首先是对原始输入文本进行预处理,用于训练浅学习模型,一般包括分词、数据清理和数据统计。然后,文本表示的目标是将预处理后的文本以一种更易于计算机使用并最大限度地减少信息丢失的形式表示,最后,根据选择的特征将表示的文本输入到分类器中。

特性工程是一项艰巨的工作。在训练分类器之前,我们需要收集知识或经验从原始文本中提取特征。浅学习方法根据从原始文本中提取的各种文本特征训练初始分类器。

(二)深度学习模型

1)ReNN:将输入文本的每个单词作为模型结构的叶节点。然后使用权重矩阵将所有节点合并成父节点。权重矩阵在整个模型中共享。每个父节点与所有叶节点具有相同的维度。最后,所有节点递归地聚合成一个父节点来表示输入文本以预测标签。

递归神经网络的结构
2)MLP:这是一个三层MLP模型。它包含一个输入层、一个在所有节点中都有激活功能的隐藏层和一个输出层。每个节点连接一个特定的权重wi。段落向量(Page-Vec)是基于它的方法(与CBOW相比,它增加了一个通过矩阵映射到段落向量的段落标记。该模型通过这个向量与单词的三个上下文的联系或平均值来预测第四个单词。段落向量可以被用作段落主题的存储器,并且被用作段落函数并被插入到预测分类器中)。

多层感知器的结构(MLP)
3)RNN:首先,使用单词嵌入技术用特定的向量来表示每个输入单词。然后,将嵌入的单词向量一个接一个地输入RNN单元。RNN单元的输出与输入向量的维数相同,并被馈送到下一个隐藏层。RNN在模型的不同部分共享参数,并且每个输入单词的权重相同。最后,输入文本的标签可以通过隐藏层的最后输出来预测。

递归神经网络的结构(RNN)
在RNN的反向传播过程中,权重通过梯度来调整,梯度通过导数的连续乘法来计算。如果导数极小,通过连续乘法可能会引起梯度消失问题。长短期记忆(LSTM) (RNN的改进),有效地缓解了梯度消失问题。它由一个在任意时间间隔内记住值的单元和三个控制信息流的门结构组成。门结构包括输入门、忘记门和输出门。LSTM分类方法能够更好地捕捉上下文特征词之间的联系,利用遗忘门结构过滤无用信息,有利于提高分类器的整体捕捉能力。
4)CNN:首先,将输入文本的词向量拼接成一个矩阵。然后将矩阵送入卷积层,卷积层包含几个不同维度的滤波器。最后,卷积层的结果经过池化层,并将池化结果串接起来,得到文本的最终向量表示。分类由最终向量预测。TextCNN可以通过一层卷积更好地确定最大池化层的判别短语,并通过保持词向量静态的方式学习除词向量外的超参数。
据文本的最小嵌入单元,将嵌入方法分为字符级、单词级和句子级嵌入方法。字符级嵌入可以解决词汇表外(OOV)的单词。词级嵌入学习单词的语法和语义。此外,句子级嵌入可以捕捉句子之间的关系。

卷积神经网络(CNN)的架构
5)Attention:
层次注意网络(HAN),通过利用文本的极具信息成分来获得更好的可视化,如图11所示。HAN包括两个编码器和两个层次的注意层。注意机制让模型对特定的输入给予不同的注意。该方法首先将基本词汇聚合成句子向量,然后再将关键句子向量聚合成文本向量。通过两个层次的注意,可以了解每个单词和句子对分类判断的贡献大小,有利于应用和分析。

层次注意网络的体系结构(HAN)
Self-attention在句子中构造K、Q和V矩阵来捕获单词在句子中的权重分布,这些矩阵可以捕获对文本分类的长期依赖。每个输入词向量ai可以表示为三个n维向量,包括qi、ki、vi。自我注意后,输出向量ai可以表示为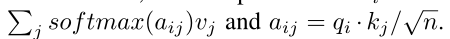 和
和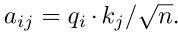 ,所有的输出向量都可以并行计算
,所有的输出向量都可以并行计算

self-attention的一个例子
6)Transformer:通常使用无监督方法自动挖掘语义知识,然后构造预训练目标,以便机器学习理解语义。

预训练模型

预训练模型架构
7)GNN:将文本分类转换为图形节点分类任务。首先,将四个输入文本和文本中的单词定义为节点,构造成图形结构。图节点由黑色粗体边连接,黑色边表示文档-单词的边和单词-单词的边。单词边缘的权重通常表示单词在语料库中的共现频率。然后,通过隐藏层来表示单词和文本。最后,通过图来预测所有输入文本的标签。
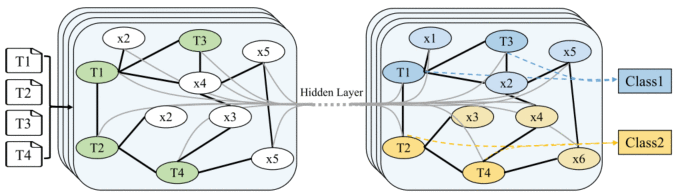
GCN的模型
DGCNN是一个将文本转换为词图的graph-CNN,具有通过CNN模型学习不同层次语义的优势。
TextGCN文本图卷积网络,为整个数据集构建异构的词文本图,并捕获全局词共现信息。
TextING为每个文档构建单独的图表,并通过GNN学习文本级别的单词交互,从而有效地在新文本中生成模糊单词的嵌入。
图注意网络(GATs)通过关注它的邻居来使用隐藏的自我注意层。因此,提出了一些基于GAT的模型来计算每个节点的隐藏表示。具有双重注意机制的异构图注意网络(HGAT)学习当前节点中不同相邻节点和节点类型的重要性。该模型在图上传播信息并捕获关系,以解决半监督短文本分类的语义稀疏性问题。MAGNET基于GATs捕获标签之间的相关性,该方法学习标签之间的关键相关性,并通过特征矩阵和相关矩阵生成分类器。
一些DNNs历年的数据,评价指标和实验数据集等

(应用包括情感分析(SA)、主题标注(TL)、新闻分类(NC)、问答(QA)、对话行为分类(DAC)、自然语言推理(NLI)、关系分类(RC)和事件预测(EP))
1.3 数据集与评价指标
(一)数据集
数据集的汇总统计 C:目标类别数量 L:平均句子长度 N:数据集大小

(二)评价指标

1)准确率、错误率:
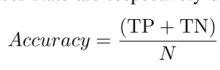
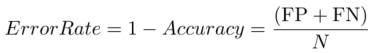
2)精确度、召回率、F1:

3)Micro-F1:
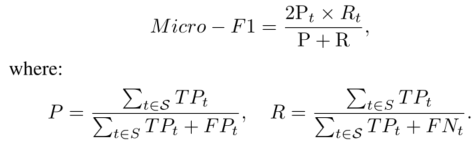
4)Macro-F1:
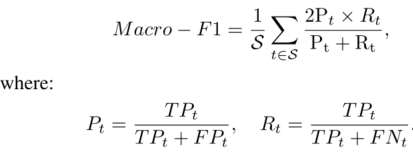
5)P@K: 每个文本都有一组L个基本事实标签,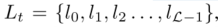 按照概率递减的顺序,
按照概率递减的顺序,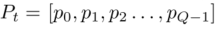 ,k处的精度为:
,k处的精度为:
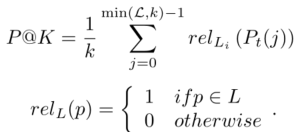
其中,L是每个文本上的基本事实标签或可能答案的数量,k是极端多标签文本分类中所选标签的数量。
6)NDCG@K:
1.4 性能
基于深度学习的文本分类模型在原始数据集上的准确性由分类准确性评估


![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)









 京公网安备 11010802041100号
京公网安备 11010802041100号