2019独角兽企业重金招聘Python工程师标准>>> 
前言
由于接触的工作对文本语义分析较多,但是实际的应用场景,如果用solr和es感觉就是杀鸡用牛刀,
所以学习lucene,部署运维都方便,可以学习,美滋滋。时间点:2017.8.22 最新版本 6.6.0
pom.xml 如下
建立索引
Directory 索引存储目录
看下具体的几种实现
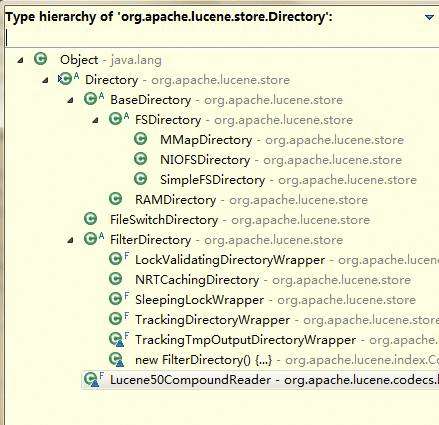
后面再详细介绍,这里大致知道有这么多实现即可。
Analyzer 分词器,同样有多种实现 ,比如:例子中的标准分词,IK中文分词,CJK二分分词等;
后面具体再介绍
创建索引demo:
// 指定索引库的地址Directory dir= NIOFSDirectory.open(FileSystems.getDefault().getPath("E:/lucene_test"));// 创建分词器,标准分词器Analyzer analyzer = new StandardAnalyzer();IndexWriterConfig iwc = new IndexWriterConfig(analyzer);IndexWriter writer = new IndexWriter(dir, iwc);writer.deleteAll(); // 清除以前的indexDocument document = new Document();Field id = new TextField("id", "1"),Field.Store.YES);Field name = new TextField("name", "我是中国人", Field.Store.YES);// 将field域设置到Document对象中document.add(id);document.add(name);writer.addDocument(document)// 关闭writerwriter.close();
通过索引查询
简单查询demo:
// 注意与创建索引使用相同的分词器 Analyzer analyzer = new StandardAnalyzer();// 第一个参数:默认搜索的域的名称QueryParser parser = new QueryParser("name", analyzer);Query query = parser.parse("中国");Directory directory = NIOFSDirectory.open(FileSystems.getDefault().getPath("E:/lucene_test"));IndexReader reader = DirectoryReader.open(directory);IndexSearcher searcher = new IndexSearcher(reader);// 通过searcher来搜索索引库// 第二个参数:指定需要显示的顶部记录的N条TopDocs topDocs = searcher.search(query, 10);// 根据查询条件匹配出的记录总数int count = topDocs.totalHits;System.out.println("匹配出的记录总数:" + count);// 根据查询条件匹配出的记录ScoreDoc[] scoreDocs = topDocs.scoreDocs;for (ScoreDoc scoreDoc : scoreDocs) {// 获取文档的IDint docId = scoreDoc.doc;// 通过ID获取文档Document doc = searcher.doc(docId);System.out.println("id:" + doc.get("id"));System.out.println("name:" + doc.get("name"));}// 关闭资源reader.close();











 京公网安备 11010802041100号
京公网安备 11010802041100号