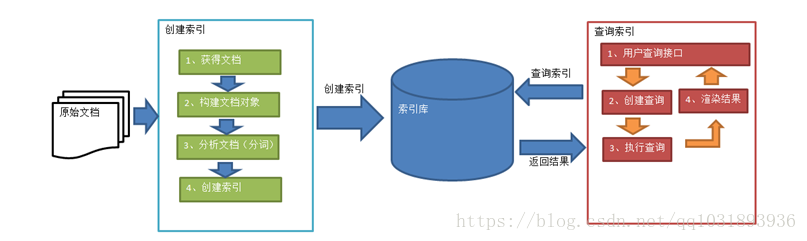
原始文档是指要索引和搜索的内容。原始内容包括互联网上的网页、数据库中的数据、磁盘上的文件等。
获取原始内容的目的是为了索引,在索引前需要将原始内容创建成文档(Document),文档中包括一个一个的域(Field),域中存储内容。
这里我们可以将磁盘上的一个文件当成一个document,Document中包括一些Field(file_name文件名称、file_path文件路径、file_size文件大小、file_content文件内容)。
将原始内容创建为包含域(Field)的文档(document),需要再对域中的内容进行分析,分析的过程是经过对原始文档提取单词、将字母转为小写、去除标点符号、去除停用词等过程生成最终的语汇单元,可以将语汇单元理解为一个一个的单词。
对所有文档分析得出的语汇单元进行索引,索引的目的是为了搜索,最终要实现只搜索被索引的语汇单元从而找到Document(文档)。
用于输入查询内容的载体。
用户输入查询关键字执行搜索之前需要先构建一个查询对象,查询对象中可以指定查询要搜索的Field文档域、查询关键字等,查询对象会生成具体的查询语法。
根据查询语法在倒排索引词典表中分别找出对应搜索词的索引,从而找到索引所链接的文档链表。
以一个友好的界面将查询结果展示给用户,用户根据搜索结果找自己想要的信息,为了帮助用户很快找到自己的结果,提供了很多展示的效果,比如搜索结果中将关键字高亮显示,百度提供的快照等。
创建索引库时,域对象相关的子类介绍:
| Field类 | 数据类型 | Analyzed 是否分析 | Indexed 是否索引 | Stored 是否存储 | 说明 |
| StringField(FieldName, FieldValue,Store.YES)) | 字符串 | N | Y | Y或N | 这个Field用来构建一个字符串Field,但是不会进行分析,会将整个串存储在索引中,比如(订单号,姓名等) 是否存储在文档中用Store.YES或Store.NO决定 |
| LongField(FieldName,FieldValue,Store.YES) | Long型 | Y | Y | Y或N | 这个Field用来构建一个Long数字型Field,进行分析和索引,比如(价格) 是否存储在文档中用Store.YES或Store.NO决定 |
| StoredField(FieldName,FieldValue) | 重载方法,支持多种类型 | N | N | Y | 这个Field用来构建不同类型Field 不分析,不索引,但要Field存储在文档中 |
TextField(FieldName, FieldValue, Store.NO) 或 TextField(FieldName, reader) | 字符串 或 流 | Y | Y | Y或N | 如果是一个Reader,lucene猜测内容比较多,会采用Unstored的策略 |
查询索引库时,索引搜索器的搜索方法介绍:
| 方法 | 说明 |
| indexSearcher.search(query, n) | 根据Query搜索,返回评分最高的n条记录 |
| indexSearcher.search(query,filter,n) | 根据Query搜索,添加过滤规则,返回评分最高的n条记录 |
| indexSearcher.search(query,n,sort) | 根据Query搜索,添加排序规则,返回评分最高的n条记录 |
| indexSearcher.search(booleanQuery,filter,n,sort) | 根据Query搜索,添加过滤该规则,添加排序规则,返回评分最高的n条记录 |
代码:
package com.xushuai.lucene;import org.apache.commons.io.FileUtils;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.*;
import org.apache.lucene.index.*;
import org.apache.lucene.search.*;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.junit.Test;import java.io.File;
import java.io.IOException;/*** Lucene初次使用* Author: xushuai* Date: 2018/5/6* Time: 15:08* Description:*/
public class LuceneDemo {/** 创建索引库的步骤* 第一步:创建一个java工程,并导入jar包。* 第二步:创建一个indexwriter对象。* 1)指定索引库的存放位置Directory对象* 2)指定一个分析器,对文档内容进行分析。* 第三步:创建document对象。* 第四步:创建field对象,将field添加到document对象中。* 第五步:使用indexwriter对象将document对象写入索引库,此过程进行索引创建。并将索引和document对象写入索引库。* 第六步:关闭IndexWriter对象。*//*** 创建索引库* @auther: xushuai* @date: 2018/5/6 15:12* @throws: IOException*/@Testpublic void luceneCreateIndexRepository() throws IOException {//存放索引库的路径Directory directory = FSDirectory.open(new File("D:\\lucene&solr\\lucene\\index"));//创建分析器(使用其子类,标准分析器类)Analyzer analyzer = new StandardAnalyzer();IndexWriterConfig indexWriterConfig = new IndexWriterConfig(Version.LATEST, analyzer);//使用索引库路径和分析器构造索引库写入流IndexWriter indexWriter = new IndexWriter(directory,indexWriterConfig);//读取原始文档创建相应文档对象,并设置相关field域File dir = new File("D:\\lucene&solr\\lucene\\searchsource");//遍历该dir下所有的文件创建文档对象for(File file:dir.listFiles()){//获取其文件名、文件大小、文件位置、文件内容String file_name = file.getName();String file_path = file.getPath();Long file_size = FileUtils.sizeOf(file);String file_content = FileUtils.readFileToString(file);//为获取到的文件属性创建相应域(参数分别为:域名城、域值以及是否保存)Field fileNameField = new TextField("filename",file_name, Field.Store.YES);Field filePathField = new StoredField("filepath",file_path);Field fileSizeField = new LongField("filesize",file_size, Field.Store.YES);Field fileContentField = new TextField("filecontent",file_content,Field.Store.YES);//创建document对象Document document = new Document();//保存域对象document.add(fileContentField);document.add(fileNameField);document.add(filePathField);document.add(fileSizeField);//将document绑定给写入流indexWriter.addDocument(document);}//释放资源indexWriter.close();}/** 查询索引* 第一步:创建一个Directory对象,也就是索引库存放的位置。* 第二步:创建一个indexReader对象,需要指定Directory对象。* 第三步:创建一个indexsearcher对象,需要指定IndexReader对象* 第四步:创建一个TermQuery对象,指定查询的域和查询的关键词。* 第五步:执行查询。* 第六步:返回查询结果。遍历查询结果并输出。* 第七步:关闭IndexReader对象*//*** 查询索引* @auther: xushuai* @date: 2018/5/6 15:48* @throws: IOException*/@Testpublic void luceneSearchIndexRepository() throws IOException {//指定索引库位置Directory directory = FSDirectory.open(new File("D:\\lucene&solr\\lucene\\index"));//创建索引库读取流IndexReader indexReader = DirectoryReader.open(directory);//创建索引搜索器对象IndexSearcher indexSearcher = new IndexSearcher(indexReader);//创建查询条件对象,第一个参数为:域名称 第二个参数为:域值 这里查询条件为:文件名中含有apache的文档Query query = new TermQuery(new Term("filename","apache"));//执行查询,第一个参数为:查询条件 第二个参数为:结果返回最大个数TopDocs topDocs = indexSearcher.search(query, 10);//打印结果集长度System.out.println("查询结果总条数:" + topDocs.totalHits);//遍历结果集for (ScoreDoc doc:topDocs.scoreDocs) {//获取其查询到的文档对象,ScoreDoc对象的doc属性可以获取document的id值Document document = indexSearcher.doc(doc.doc);//打印文件名System.out.println("文件名: " + document.get("filename"));//打印文件大小System.out.println("文件大小:" + document.get("filesize"));//打印文件路径System.out.println("文件路径:" + document.get("filepath"));//打印文件内容System.out.println(document.get("filecontent"));//分割线System.out.print("------------------------------------------------------------------------------");}//释放资源indexReader.close();}
}
查询结果总条数:2
文件名: apache lucene.txt
文件大小:724
文件路径:D:\lucene&solr\lucene\searchsource\apache lucene.txt
# Apache Lucene README file## IntroductionLucene is a Java full-text search engine. Lucene is not a complete
application, but rather a code library and API that can easily be used
to add search capabilities to applications.* The Lucene web site is at: http://lucene.apache.org/* Please join the Lucene-User mailing list by sending a message to:java-user-subscribe@lucene.apache.org## Files in a binary distributionFiles are organized by module, for example in core/:* `core/lucene-core-XX.jar`:The compiled core Lucene library.To review the documentation, read the main documentation page, located at:
`docs/index.html`To build Lucene or its documentation for a source distribution, see BUILD.txt------------------------------------------------------------------------------
文件名: Welcome to the Apache Solr project.txt
文件大小:5464
文件路径:D:\lucene&solr\lucene\searchsource\Welcome to the Apache Solr project.txt
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.Welcome to the Apache Solr project!
-----------------------------------Solr is the popular, blazing fast open source enterprise search platform
from the Apache Lucene project.For a complete description of the Solr project, team composition, source
code repositories, and other details, please see the Solr web site at
http://lucene.apache.org/solrGetting Started
---------------See the "example" directory for an example Solr setup. A tutorial
using the example setup can be found athttp://lucene.apache.org/solr/tutorial.html
or linked from "docs/index.html" in a binary distribution.
Also, there are Solr clients for many programming languages, see http://wiki.apache.org/solr/IntegratingSolrFiles included in an Apache Solr binary distribution
----------------------------------------------------example/A self-contained example Solr instance, complete with a sampleconfiguration, documents to index, and the Jetty Servlet container.Please see example/README.txt for information about running thisexample.dist/solr-XX.warThe Apache Solr Application. Deploy this WAR file to any servletcontainer to run Apache Solr.dist/solr-
-------------------------------------------------1. Download the Java SE 7 JDK (Java Development Kit) or later from http://java.sun.com/You will need the JDK installed, and the $JAVA_HOME/bin (Windows: %JAVA_HOME%\bin) folder included on your command path. To test this, issue a "java -version" command from your shell (command prompt) and verify that the Java version is 1.7 or later.2. Download the Apache Ant binary distribution (1.8.2+) from http://ant.apache.org/ You will need Ant installed and the $ANT_HOME/bin (Windows: %ANT_HOME%\bin) folder included on your command path. To test this, issue a "ant -version" command from your shell (command prompt) and verify that Ant is available. You will also need to install Apache Ivy binary distribution (2.2.0) from http://ant.apache.org/ivy/ and place ivy-2.2.0.jar file in ~/.ant/lib -- if you skip this step, the Solr build system will offer to do it for you.3. Download the Apache Solr distribution, linked from the above web site. Unzip the distribution to a folder of your choice, e.g. C:\solr or ~/solrAlternately, you can obtain a copy of the latest Apache Solr source codedirectly from the Subversion repository:http://lucene.apache.org/solr/versioncontrol.html4. Navigate to the "solr" folder and issue an "ant" command to see the available optionsfor building, testing, and packaging Solr.NOTE: To see Solr in action, you may want to use the "ant example" command to buildand package Solr into the example/webapps directory. See also example/README.txt.Export control
-------------------------------------------------
This distribution includes cryptographic software. The country in
which you currently reside may have restrictions on the import,
possession, use, and/or re-export to another country, of
encryption software. BEFORE using any encryption software, please
check your country's laws, regulations and policies concerning the
import, possession, or use, and re-export of encryption software, to
see if this is permitted. See
information.The U.S. Government Department of Commerce, Bureau of Industry and
Security (BIS), has classified this software as Export Commodity
Control Number (ECCN) 5D002.C.1, which includes information security
software using or performing cryptographic functions with asymmetric
algorithms. The form and manner of this Apache Software Foundation
distribution makes it eligible for export under the License Exception
ENC Technology Software Unrestricted (TSU) exception (see the BIS
Export Administration Regulations, Section 740.13) for both object
code and source code.The following provides more details on the included cryptographic
software:Apache Solr uses the Apache Tika which uses the Bouncy Castle generic encryption libraries forextracting text content and metadata from encrypted PDF files.See http://www.bouncycastle.org/ for more details on Bouncy Castle.------------------------------------------------------------------------------










 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有