一、前言
1、前面我们搭建好了高可用的Hadoop集群,本文正式开始搭建HBase
2、HBase简介
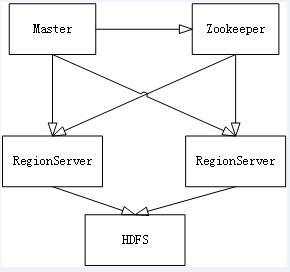
(1)Master节点负责管理数据,类似Hadoop里面的namenode,但是他只负责建表改表等操作,如果挂掉了也不会影响使用
(2)RegionServer节点负责存储数据,类似Hadoop里面的datanode,通过Zookeeper进行通信
(3)可以看出HBase实际上是基于HDFS的分布式数据库,但是单机模式下也可以直接用普通文件系统存储数据
二、HBase环境搭建
1、下载tar.gz包,并解压
tar zxvf /work/soft/installer/hbase-1.2.2-bin.tar.gz
2、由于HBase是依赖Zookeeper的,所以HBase自带Zookeeper,我们先从单机模式搭建开始学习,先把之前搭建的集群停掉
3、进入到HBase目录的conf/hbase-site.xml文件,配置HBase的目录,以下目录HBase会自动创建
vim /work/soft/hbase-1.2.2/conf/hbase-site.xml
4、启动HBase单机模式
/work/soft/hbase-1.2.2/bin/start-hbase.sh
5、通过jps查看进程是否存在

6、进入HBase的命令行
/work/soft/hbase-1.2.2/bin/hbase shell

7、我们尝试一下建表、插入数据、查询的操作,看到结果就说明单机模式成功搭建!
create 'testTable','testFamily'put 'testTable','row1','testFamily:name','jack'scan 'testTable'

8、接下来搭建分布式模式,先停掉单机模式
/work/soft/hbase-1.2.2/bin/stop-hbase.sh
9、然后删除刚刚自动创建的目录
rm -rf /work/hbase/root
rm -rf /work/hbase/zookeeper/data
10、由于HBase默认自动开启自带的Zookeeper,所以我们设置为不开启,用自己的Zookeeper
vim /work/soft/hbase-1.2.2/conf/hbase-env.shexport HBASE_MANAGES_ZK=false
11、手动创建日志文件夹
mkdir /work/hbase/logs
12、配置hbase-env.sh
(1)配置Hadoop的配置文件目录
(2)配置日志文件夹的目录(也就是刚刚手动创建的那个目录)
vim /work/soft/hbase-1.2.2/conf/hbase-env.shexport HBASE_CLASSPATH=/work/soft/hadoop-2.6.4/etc/hadoop
export HBASE_LOG_DIR=/work/hbase/logs
13、配置hbase-site.xml
(1)配置我们的Hadoop集群id
(2)开启分布式开关
(3)配置Zookeeper集群
vim /work/soft/hbase-1.2.2/conf/hbase-site.xml
14、启动HBase集群
(1)首先启动我们的Hadoop集群
(2)启动Master
/work/soft/hbase-1.2.2/bin/hbase-daemon.sh start master
(3)用jps命令查看进程是否存在

(4)启动RegionServer
/work/soft/hbase-1.2.2/bin/hbase-daemon.sh start regionserver
(5)用jps命令查看进程是否存在

(6)通过16010端口访问HBase的控制台,可以看到刚刚开启的regionserver,到此HBase搭建成功!










 京公网安备 11010802041100号
京公网安备 11010802041100号